Alignment to Read Counts & Visualization in IGV
BEFORE YOU START THIS SECTION, MAKE SURE YOU ARE LOGGED INTO THE CLUSTER USING SRUN
srun --time=4:00:00 -n 8 --mem=20g --pty /bin/bash --reservation=workshop
1. To align our data we will need the genome and annotation for Arabidopsis thaliana. There are many places to find them, but we are going to get them from the Ensembl Genomes FTP site. In a browser, go to here:
ftp://ftp.ensemblgenomes.org/pub/plants/release-39/
Navigate through the directories to find a GTF (NOT GFF3) annotation file for Arabidopsis thaliana, as well as a complete genome. The genome file is “Arabidopsis_thaliana.TAIR10.dna.toplevel.fa.gz” and the annotation file is “Arabidopsis_thaliana.TAIR10.39.gtf.gz”. When you find those files, copy the location links and use wget to add them to your ref directory:
cd ~/rnaseq_example/ref
wget <link to genome>
wget <link to annotation>
Finally, you will need to use gunzip to uncompress the files:
gunzip Arabidopsis_thaliana.TAIR10.dna.toplevel.fa.gz
gunzip Arabidopsis_thaliana.TAIR10.39.gtf.gz
Take a look at the GTF file:
less Arabidopsis_thaliana.TAIR10.39.gtf
Press ‘q’ to exit this screen.
2. We are going to use an aligner called ‘STAR’ to align the data, but in order to use star we need to index the genome for star. So go back to your ref directory and let’s do the indexing (Note that the STAR command below has been put on multiple lines for readability). We specify 4 threads, the output directory, the fasta file for the genome, the annotation file (GTF), and the overhang parameter, which is calculated by subtracting 1 from the read length.
cd ../ref
module load star
mkdir star_index
Now, generate the index:
STAR --runThreadN 4 \
--runMode genomeGenerate \
--genomeDir star_index \
--genomeFastaFiles Arabidopsis_thaliana.TAIR10.dna.toplevel.fa \
--sjdbGTFfile Arabidopsis_thaliana.TAIR10.39.gtf \
--sjdbOverhang 99
This step will take 5 minutes. You can look at the STAR documentation while you wait. All of the output files will be written to the star_index directory.
3. We are now ready to try an alignment. Let’s create an output directory for STAR:
cd ~/rnaseq_example
mkdir 02-STAR_alignment
cd 02-STAR_alignment
and let’s run STAR on the pair of subset files we created before. (Again, the command is on multiple lines for readability):
STAR --runThreadN 8 \
--sjdbOverhang 99 \
--genomeDir ../ref/star_index \
--sjdbGTFtagExonParentGene gene_id \
--sjdbGTFfile ../ref/Arabidopsis_thaliana.TAIR10.39.gtf \
--outSAMtype BAM SortedByCoordinate \
--outReadsUnmapped Fastx \
--quantMode GeneCounts \
--outFileNamePrefix C61.subset. \
--readFilesCommand zcat \
--readFilesIn ../01-HTS_Preproc/C61/C61_R1.fastq.gz ../01-HTS_Preproc/C61/C61_R2.fastq.gz
For this command, we are giving it the overhang like from the previous step, the genome index directory we created in the last step, an identifier name from the GTF file that identifies genes, the annotation file, the output file type, outputting unmapped reads, telling it to count reads on a gene level, the prefix for all the output files, the command to unzip the files, and finally, the input files.
4. Now let’s take a look at an alignment in IGV. We are going to take an alignment that was run using full read set, but cut it down so that it is small enough to download easily. First, let’s take just the chromosome 5 portion of the alignment for the I864 sample. We will use ‘samtools’ for this step, which is a program to manipulate SAM/BAM files. Take a look at the options for samtools and ‘samtools view’:
module load samtools
samtools
samtools view
Now, use the ‘samtools view’ command to extract just chromosome 5 of an already completed alignment:
samtools view -b -@ 8 -o chr5.bam /share/biocore/workshops/2018_June_RNAseq/02-STAR_alignment/C61/C61_Aligned.sortedByCoord.out.bam 5
We need to index the new BAM file:
samtools index chr5.bam
Now, download chr5.bam and chr5.bam.bai (the index file) to your laptop. You will also need to download and uncompress both the Arabidopsis thaliana genome and annotation to your laptop. Just go back to where you got them before and instead of using wget, just download them directly to your laptop. And make sure to uncompress them.
5. Now we are ready to use IGV. Go to the IGV page at the Broad Institute and click on Downloads.
Scroll down the page and under “Java Web Start” click on the “Launch” button with 1.2Gb of memory. This will download a “.jnlp” file which will need to be run using Java Web Start (javaws). If you don’t have this on your computer, you will need to install it.
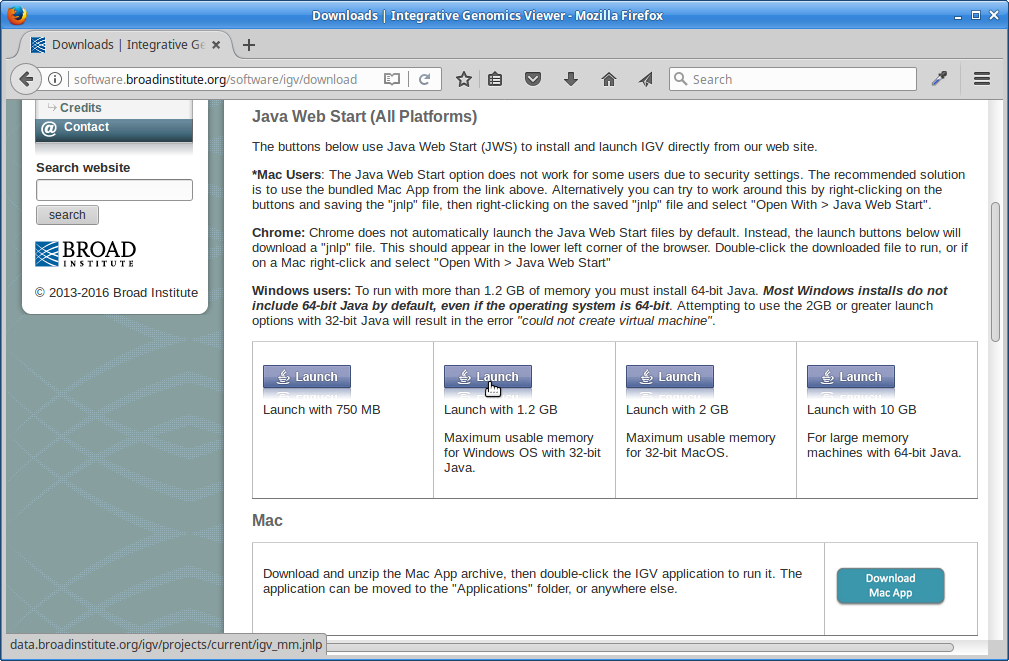
6. IGV should start up automatically. The first thing we want to do is load our Arabidopsis genome. Click on “Genomes” in the menu and choose “Load Genome from File”:
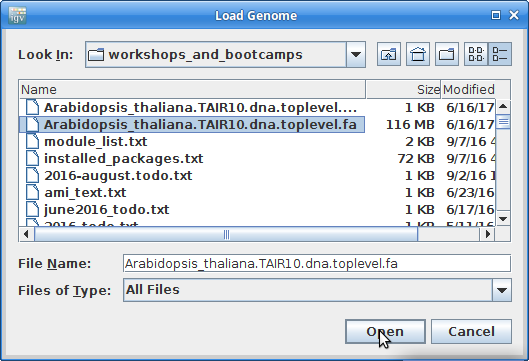
Find your genome file on your laptop and choose that:
7. Now let’s load the alignment. Click on “File” and choose “Load from File”:
Choose your chr5.bam file. Make sure the chr.bam.bai file is in the same directory as the BAM file.
Now your alignment is loaded. Any loaded file aligned to a genome is called a “track”.
8. Choose chromosome 5 from the chromosome dropdown:
You will need to zoom in to see alignments, so click on the plus sign until you see something. You also may have to move around by clicking and dragging in the BAM track window.
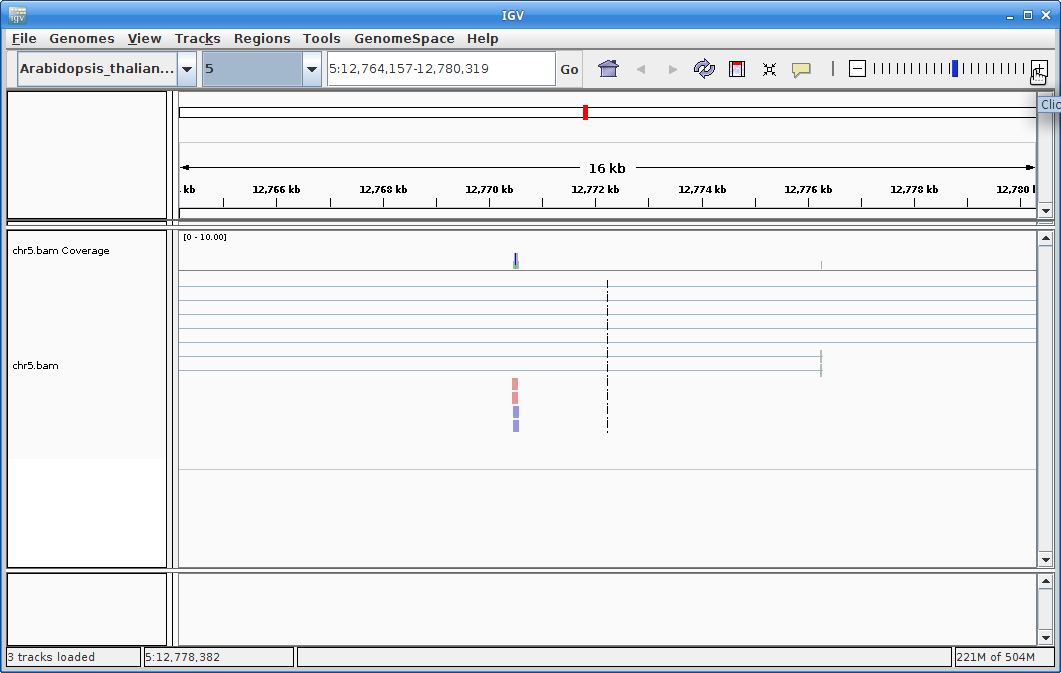
You can also zoom in by clicking and dragging across the number line at the top. That section will highlight, and when you release the button, it will zoom into that section.
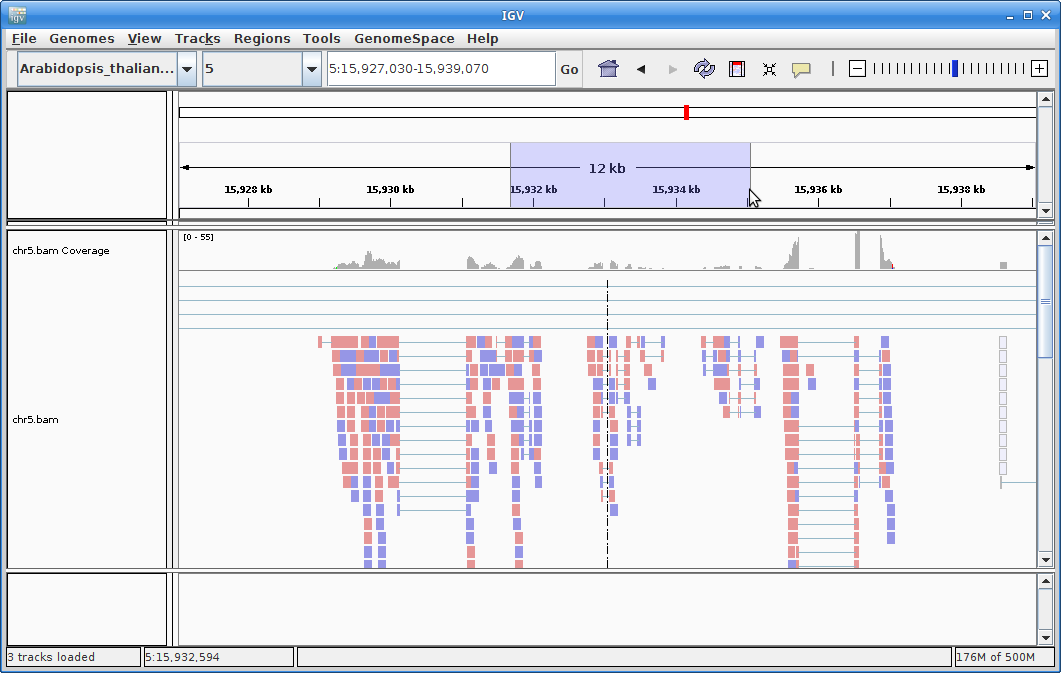
9. In order to see alignments more easily when zoomed out, we are going to create a coverage track. Click on “Tools” and then choose “Run igvtools”.
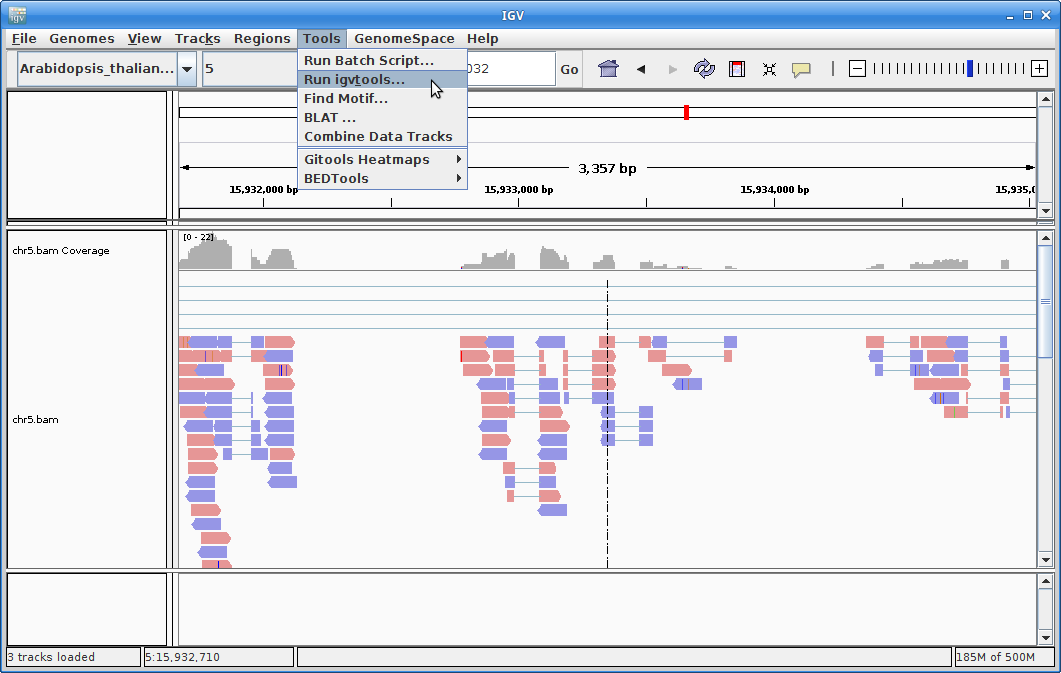
Choose “Count” as the command, and choose your chr5.bam file as the Input File (the output file path will get created automatically):
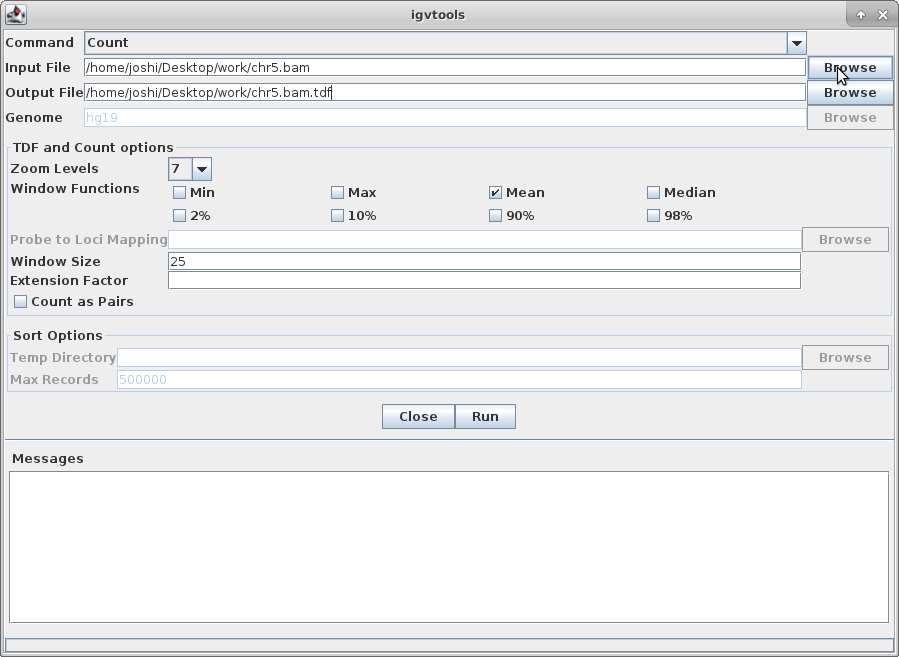
Choose a Zoom Level of 10 and then click “Run”:
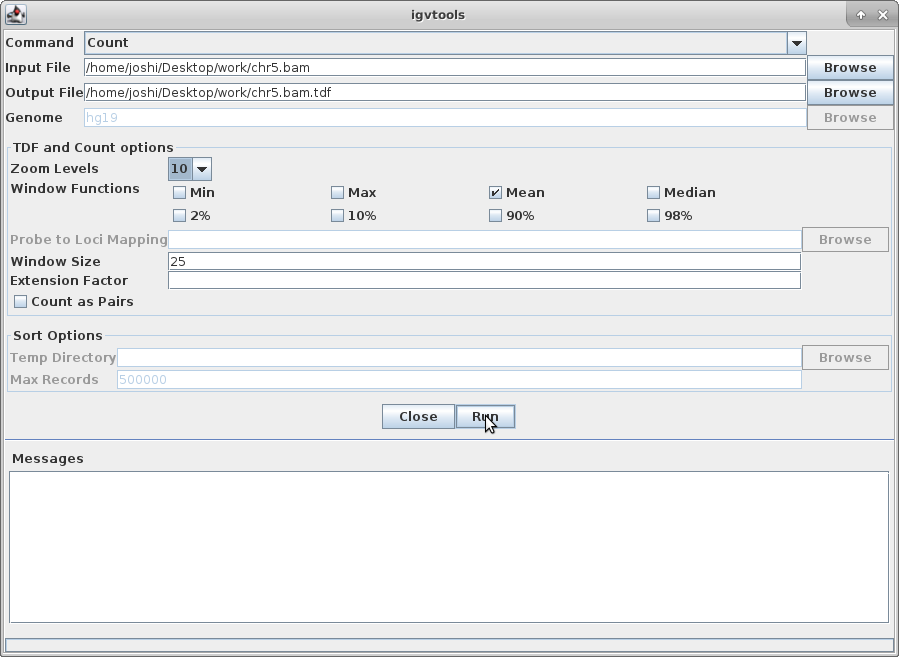
10. Once that is done, there will be a chr5.bam.tdf file in the same directory as your bam file. Click on “File” and “Load from File” and choose that file. This will create a coverage track that is visible even at maximum zoom out.
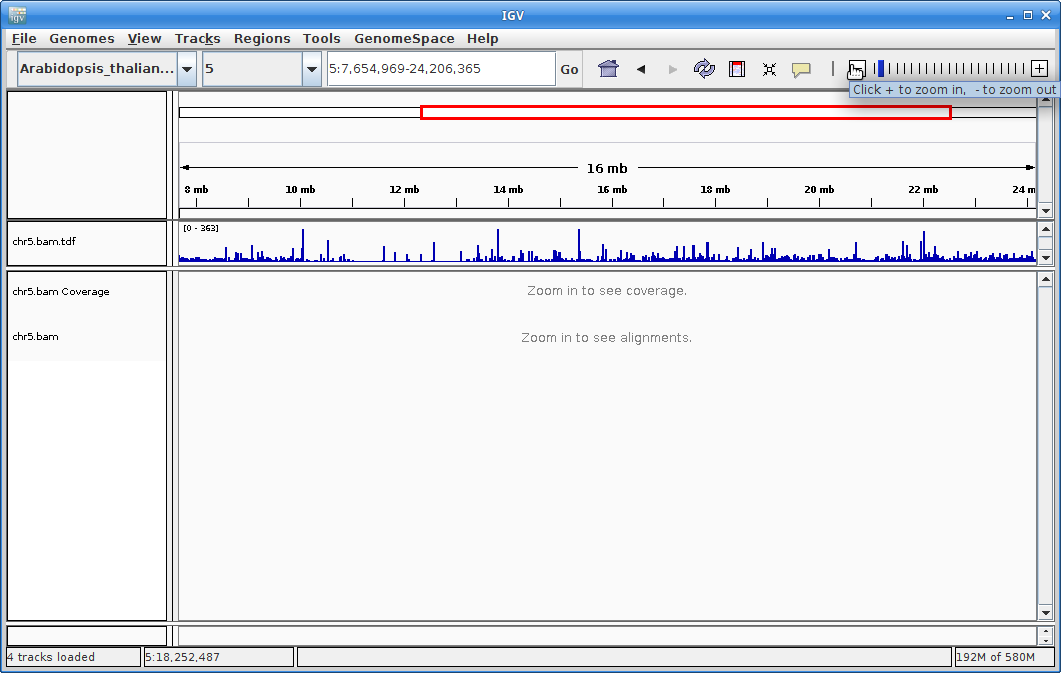
Click on the minus sign in the upper right to zoom out. Zoom out until you are all the way zoomed out. The alignment track will not show anything, but you will be able to see the coverage track which will show you the locations of the alignments.
Zoom in by clicking and dragging across the number line until you get to some alignments. You are looking at a visual representation of the alignment of the reads to the genome. Each of the little boxes in the track represent reads. The reads can be visualized in different ways which we will show you in class.
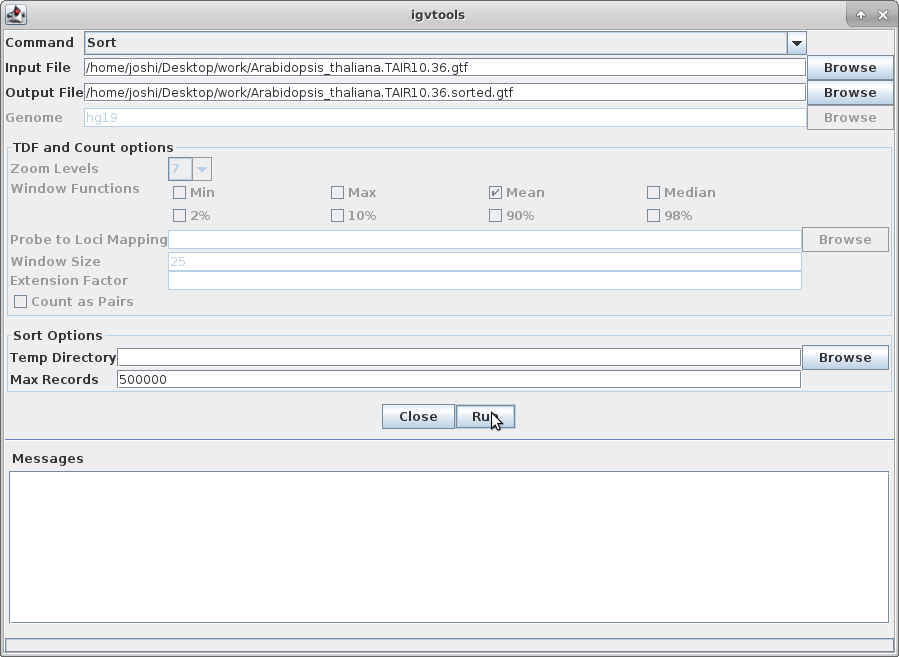
11. The other track we will add to IGV is the annotation for Arabidopsis. In order to do that, we need to first sort the annotation file. Go to igvtools again:
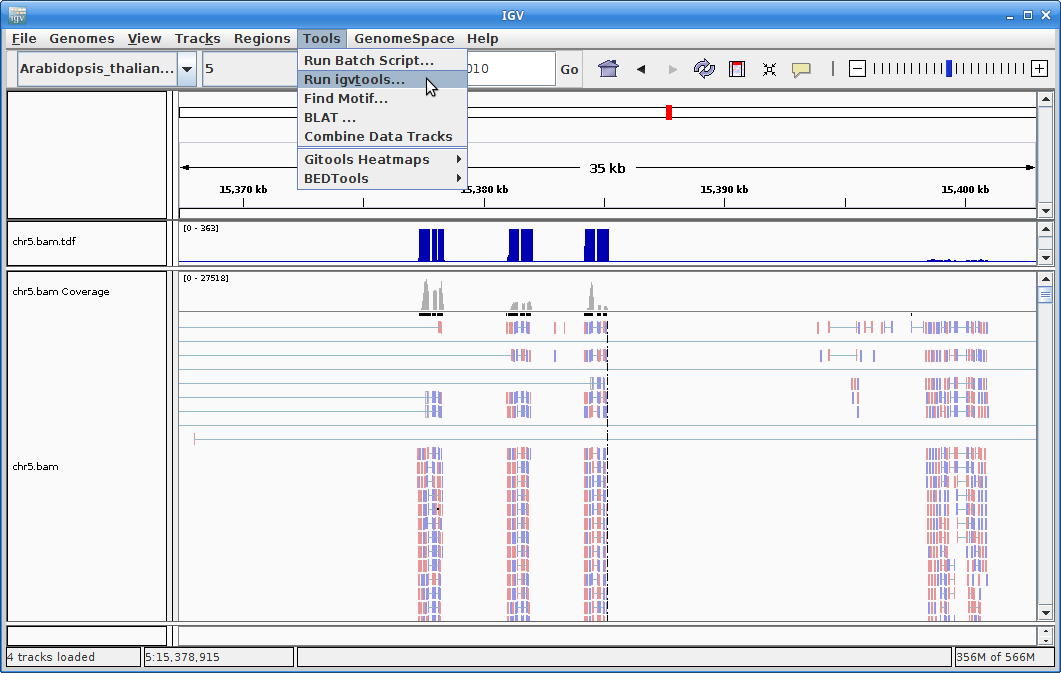
Choose “Sort” as the command and choose the gtf annotation file as the input file. Run it:
–
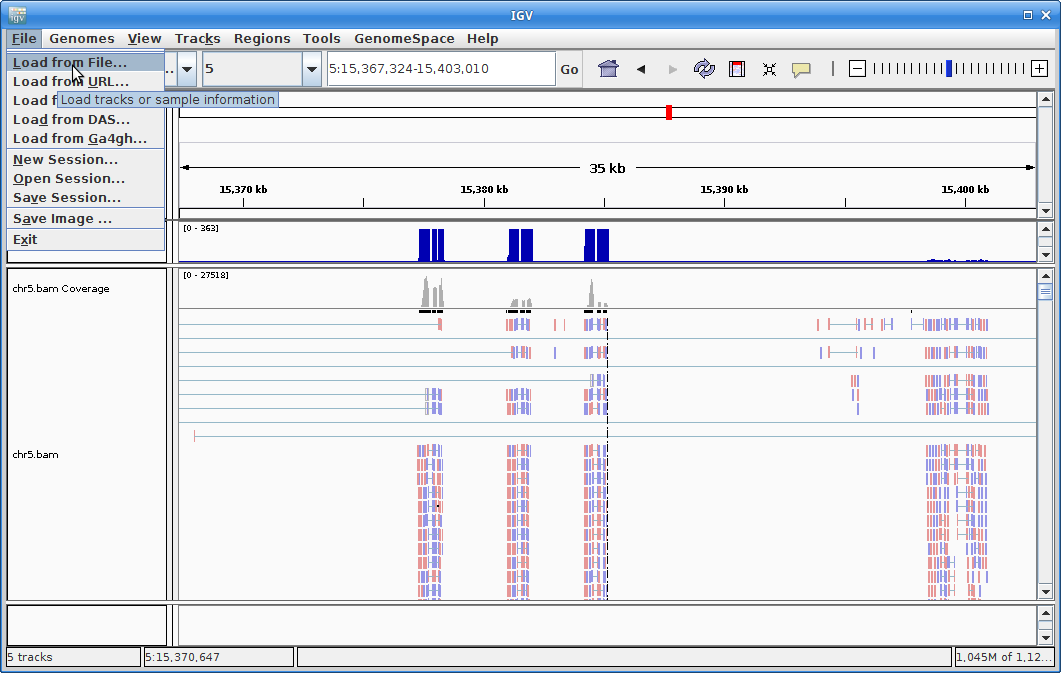
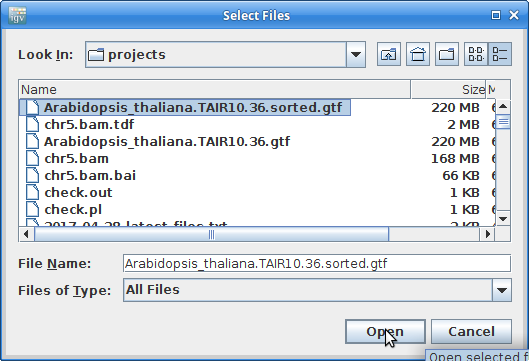
12. Load the newly created and sorted gtf file:
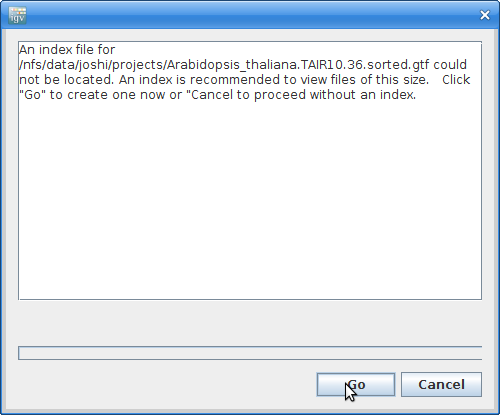
It will give you a warning about not having an index file. Click “Go” to create one:
13. Once the annotation track is loaded, zoom into a gene and you will see that the reads should be aligning with the exons in the genes. This makes sense, since RNA-Seq reads are from exons:
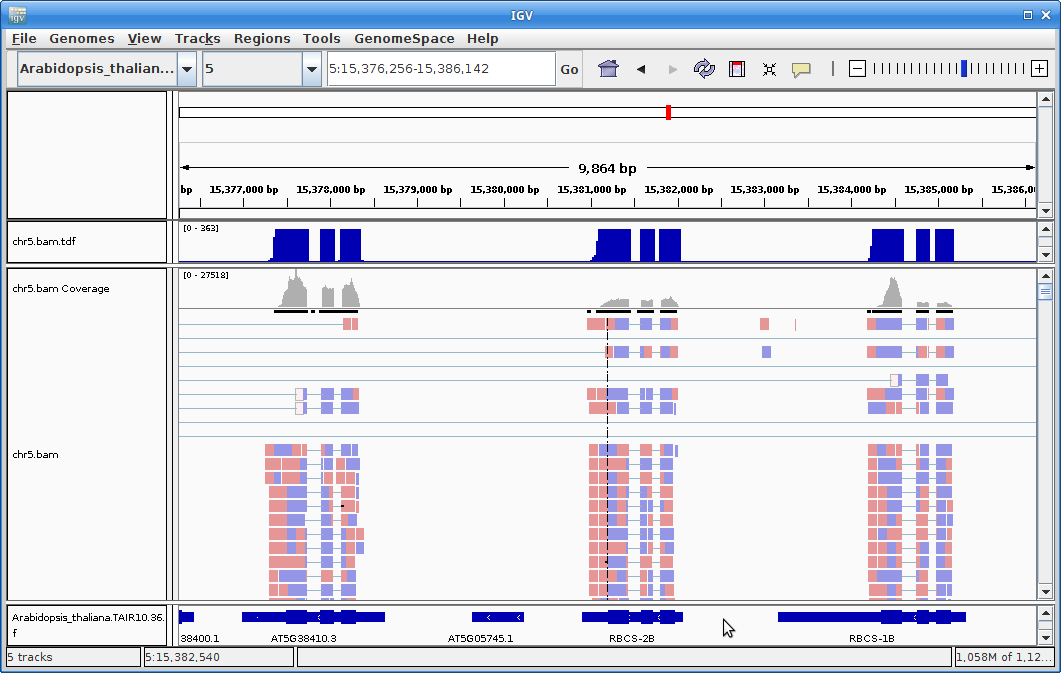
14. Ok, let’s go back to the command-line. Now we are going to run all of the STAR alignments on the cluster. We will run the script, star.slurm from the base directory:
cd ~/rnaseq_example
Next, copy a slurm task array file called “star.slurm”:
cp /share/biocore/workshops/2018_June_RNAseq/star.slurm .
This file is not complete. The variables for the reference directory and the GTF annotation file are blank. You need to use nano (the text editor) to add the full paths of the reference directory and the GTF annotation file. Once you do that and save the file, you can move on to the final step.
nano star.slurm
Find the paths you need and add them to the correct spots in the script. You may need to open another terminal. Save the file and exit nano.
15. First, take look at the file:
cat star.slurm
It looks very similar to our previous task array file, except we are running STAR, so we are using a few more variables. If everything is set up properly, then all you have to do is use sbatch:
sbatch star.slurm
You will want to use ‘squeue’ to make sure that your jobs are actually running. If your jobs finish quickly, then something went wrong.
squeue -u <your username>
And now you wait.
16. Once your jobs have finished successfully, use a script of ours, aln_stats.sh to collect the alignment stats. Don’t worry about the script’s contents at the moment; you’ll use very similar commands to create a counts table in the next section. For now:
cd ~/rnaseq_example/02-STAR_alignment/
cp /share/biocore/workshops/2018_June_RNAseq/02-STAR_alignment/aln_stats.sh .
. aln_stats.sh
The table that this script creates (“stats.txt”) can be pulled to your laptop via ‘scp’, or WinSCP, etc., and imported into a spreadsheet. Are all samples behaving similarly? Discuss …
17. Scripts
slurm script for mapping using slurm task array and star
shell script for mapping using bash loop and star.
shell script to produce summary mapping table