
Running jobs on the cluster and using modules
The HPC Core (High Performance Computing Core) runs many clusters on the UC Davis campus. The job scheduling system we use on these clusters is called Slurm. In this section, we will go through examples of the commands we will be using to interact with the cluster.
First, what is a cluster?
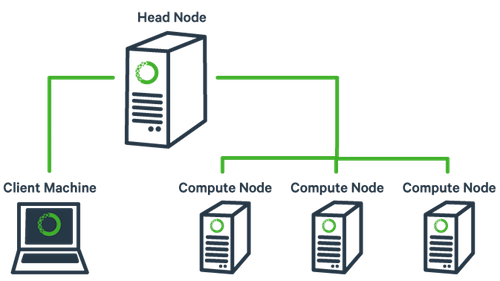
The basic architecture of a compute cluster consists of a “head node”, which is the computer from which a user submits jobs to run, and “compute nodes”, which are a large number of computers on which the jobs can be run. It is also possible to log into a compute node and run jobs directly from there. In general you should never run a job directly on the head node!
Cluster Terminology
-
Node: An individual computer in the cluster
-
Login (or head) node: The node users log in to and use to submit jobs.
-
Scheduler (and queue): The entity that coordinates which jobs run at what time on which node(s)
-
CPU Core: A single processing unit
-
Thread: Processing unit that shares resources with other threads
-
Interconnect: The network connecting the nodes to each other and to the storage
-
Core (memory): RAM
-
Swap: If RAM is exceeded, virtual memory will be used. Using disk instead of RAM. (Much slower)
-
Thrash: Competing processes swapping at the same time.
Let’s login to the cluster
There are different ways to log into the cluster depending upon what kind of computer you are using. However, if you are using Mac, Linux, or Windows 10+ with Ubuntu installed, then you can use this command on the command-line in a terminal:
ssh <username>@<your login node>
where ‘<username>’ is replaced with your username and ‘<your login node>’ is replaced with the fully qualified name of your login node (e.g. barbera.genomecenter.ucdavis.edu).
Let’s look at a few slurm commands.
The commands that you will most likely be using are srun, sbatch, squeue, scancel, and sacct.
‘srun’ is used to run a job interactively. We most often use it to start an interactive session on a compute node. Take a look at the options to srun:
srun --help
Different clusters have different requirements for when options need to be specified to run a job. For example, the LSSC0 cluster requires that you specify a time limit for your job. If your job exceeds these limits, then it will be killed. So we can run the following to create an interactive session on a node:
srun -t 00:30:00 -c 1 -n 1 --mem 500 --partition production --account workshop --pty /bin/bash
This command is requesting a compute node with a time limit of 30 minutes (-t), one processor (-c), a max memory of 0.5Gb [500] (--mem), and then finally, specifying a shell to run in a terminal (“--pty” option). You should run this command to get to a compute node when you want to run jobs on the command-line directly.
You safely ignore the working and error. Notice that we are no longer on the head node, but are now on a compute node.
use Exit on the command line to exit the session
exit
‘sbatch’ is used to submit jobs to run on the cluster. Typically it is used to run many jobs via the scheduler non-interactively. Look at the options for sbatch:
sbatch --help
Generally, we do not use any options for sbatch … we typically give it a script (i.e. a text file with commands inside) to run. Let’s take a look at a template script template.slurm:
#!/bin/bash
# options for sbatch
#SBATCH --job-name=name # Job name
#SBATCH --nodes=1 # should never be anything other than 1
#SBATCH --cpus-per-task=1 # number of cpus to use
#SBATCH --time=60 # Acceptable time formats include "minutes", "minutes:seconds", "hours:minutes:seconds", "days-hours", "days-hours:minutes" and "days-hours:minutes:seconds".
#SBATCH --mem=2000 # Memory pool for all cores (see also --mem-per-cpu)
#SBATCH --partition=production # cluster partition
#SBATCH --account=workshop # cluster account to use for the job
##SBATCH --array=1-16 # Task array indexing, see https://slurm.schedmd.com/job_array.html, the double # means this line is commented out
#SBATCH --output=stdout.out # File to which STDOUT will be written
#SBATCH --error=stderr.err # File to which STDERR will be written
#SBATCH --mail-type=ALL
#SBATCH --mail-user=myemail@email.com
# for calculating the amount of time the job takes and echo the hostname
begin=`date +%s`
echo $HOSTNAME
# Sleep for 5 minutes
sleep 300
# getting end time to calculate time elapsed
end=`date +%s`
elapsed=`expr $end - $begin`
echo Time taken: $elapsed
The first line tells sbatch what scripting language (bash here) the rest of the file is in. Any line that begins with a “#” symbol is ignored by the bash interpreter, those lines that begin with “#SBATCH” are used by the slurm controller. Those lines are for specifying sbatch options without having to type them on the command-line every time. In this script, on the next set of lines, we’ve put some code for calculating the time elapsed for the job and then we simply wait for 5 minutes (300 seconds) and exit. Let’s run it:
wget https://raw.githubusercontent.com/ucdavis-bioinformatics-training/2022-May-Slurm-Seminar/master/scripts/template.slurm
cat template.slurm
sbatch template.slurm
After finishing you will see two new files in the directory stdout.out and stderr.err where stdout and stderr (respectively) were redirected to.
‘squeue’ lists the currently queued/running jobs.
squeue --help
Looking at the help documentation, we see that we can filter the results based on a number of criteria. The most useful option is “-u”, which you can use to see just the jobs for a particular user ID. The first column gives you the job ID of the job, the second is the partition (different queues for different types of machines), the name of the job, the user who ran the job, the state of the job (R is for running), the length of time the job has been running, the number of nodes the job is using, and finally, the node name where the job is running or a reason why the job is waiting.
squeue -u username
You can see the job has been running (ST=R) for 6 seconds (TIME=0:06) on node drove-12. The jobid (here 29390121) can be used to cancel the job later, or get additional job information.
‘scancel’ command is used to cancel jobs (either running or in queue).
You can give it a job ID, or if you use the “-u” option with your username, you can cancel all of your jobs at once.
scancel -j 29390121
will cancel the above job if its still running.
‘sacct’ command is used to get accounting data for any job that has ever run, using the job ID.
To get statistics on completed jobs by jobID (replace jobid with your jobid):
sacct -j jobid --format=JobID,JobName,MaxRSS,Elapsed
To view the same information for all jobs of a user (replace username with your username):
sacct -u username --format=JobID,JobName,MaxRSS,Elapsed
You can get more information about each command by typing “
Array Jobs
If you need to submit many jobs to the cluster at once, the best way to do that is to use Job Arrays. Here is an example of a real world job script using a Job Array:
#!/bin/bash
#SBATCH --array=1-22 # NEED TO CHANGE THIS!
#SBATCH --job-name=htstream # Job name
#SBATCH --nodes=1
#SBATCH --cpus-per-task=8
#SBATCH --time=2-0
#SBATCH --mem=20000 # Memory pool for all cores (see also --mem-per-cpu)
#SBATCH --partition=production
start=`date +%s`
hostname
outdir="01-Cleaned"
sampfile="newids.sample_data.txt"
SAMPLE=`head -n ${SLURM_ARRAY_TASK_ID} $sampfile | tail -1 | cut -f1`
R1=`head -n ${SLURM_ARRAY_TASK_ID} $sampfile | tail -1 | cut -f2`
R2=`head -n ${SLURM_ARRAY_TASK_ID} $sampfile | tail -1 | cut -f3`
echo $SAMPLE
if [ ! -e $outdir ]; then
mkdir $outdir
fi
if [ ! -e "$outdir/$SAMPLE" ]; then
mkdir $outdir/$SAMPLE
fi
module load htstream/1.3.3
call="hts_Stats -F -L $outdir/$SAMPLE/$SAMPLE.stats.log -1 $R1 -2 $R2 | \
hts_SeqScreener -F -A $outdir/$SAMPLE/$SAMPLE.stats.log | \
hts_AdapterTrimmer -F -A $outdir/$SAMPLE/$SAMPLE.stats.log | \
hts_Overlapper -F -A $outdir/$SAMPLE/$SAMPLE.stats.log | \
hts_QWindowTrim -F -A $outdir/$SAMPLE/$SAMPLE.stats.log | \
hts_LengthFilter -F -m 50 -A $outdir/$SAMPLE/$SAMPLE.stats.log | \
hts_Stats -F -f $outdir/$SAMPLE/$SAMPLE.cleaned -A $outdir/$SAMPLE/$SAMPLE.stats.log"
echo $call
eval $call
end=`date +%s`
runtime=$((end-start))
echo Runtime: $runtime seconds
The key to using job arrays is the “--array” option and the SLURM_ARRAY_TASK_ID environment variable. The “--array” option is your slurm script defines the range for the SLURM_ARRAY_TASK_ID variable. The slurm controller will go through the range and create a new job (using the same slurm script) for every number in that range. Each number will be assigned to SLURM_ARRAY_TASK_ID for each job. E.g., if the range is “1-22” then there will be 22 jobs run, each one getting a unique value for SLURM_ARRAY_TASK_ID. The common thing to do is to use the SLURM_ARRAY_TASK_ID value to index into a sample metadata file. E.g., you could have a text file with 22 lines, each line corresponding to a different sample.
Then you can run the script using sbatch. Once you run it, all the jobs will get created and be put into the queue. The entire job array gets a job ID, and each individual job’s SLURM_ARRAY_TASK_ID value is appended to the job array ID to produce the individual job IDs.
You can use the same commands for an array job that you use for a single job. You can cancel all of the array jobs by specifying the job array ID in scancel, or you can cancel individual jobs using the individual job IDs (i.e. with the appended SLURM_ARRAY_TASK_ID value).
Use this one simple trick
One way to check if you properly wrote the script, without having to run all of your jobs, is to assign SLURM_ARRAY_TASK_ID a value of 1 explicitly and then run the script on the command line directly:
export SLURM_ARRAY_TASK_ID=1
bash hts_pe_array.slurm
This will run only the first sample from your sample file in the terminal. It help you determine if there is anything wrong with the script without needing to run everything. Once you are satisfied that the script is good, then you can kill that job and run the whole job array.