
Using the computing cluster
In order to log in, you should have already created an account on our systems.
For Macs/Linux/Windows 10 - Logging In
-
For Macs, open a Terminal (usually under Applications/Utilities on a Mac), or install iterm2. For Linux, just open a regular terminal. For Windows 10, open a command prompt by searching for and running “cmd”.
-
Copy and paste this into the terminal:
ssh username@tadpole.genomecenter.ucdavis.edu
where ‘username’ is replaced with your username. Press Enter. You will probably get a warning about not being able to establish the authenticity of the host and it will ask if you want to continue connecting. Just type “yes” and press enter.
- Type in your password. No characters will display when you are typing. Press Enter.
For Windows 8 and less
- Download and install PuTTY.
- Open up PuTTY
- In the Host Name field, type tadpole.genomecenter.ucdavis.edu
- Make sure the Connection Type is SSH.
- Press “Open”. It will ask you for your username and password.
Running jobs on the cluster and using modules
1. In the UC Davis Bioinformatics Core we have a large computational cluster (named lssc0) that we use for our analyses. The job scheduling system we use on this cluster is called Slurm. In this section, we will go through examples of the commands we will be using to interact with the cluster.
For this workshop we will be using a cluster reservation, meaning we’ve set aside resources (5 nodes) for exclusive use by the workshop, so any wait times will be minimal. The reservation is:
| RESV_NAME | STATE | START_TIME | END_TIME | DURATION |
| epigenetics-workshop | ACTIVE | 2020-11-29T00:00:00 | 2020-12-11T00:00:00 | 12-00:00:00 |
You’ll notice the reservation extends to Dec-11-2020, you will have an extra week to work on the cluster and workshop material.
First, what is a cluster?
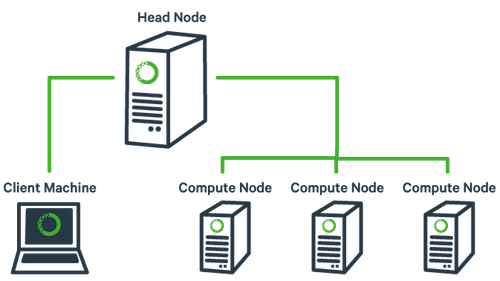
The basic architecture of a compute cluster consists of a “head node”, which is the computer from which a user submits jobs to run, and “compute nodes”, which are a large number of computers on which the jobs can be run. It is also possible to log into a compute node and run jobs directly from there. In general you should never run a job directly on the head node!
Lets login to the cluster
ssh [username]@tadpole.genomecenter.ucdavis.edu
where ‘username’ is replaced with your username. Be sure to remove the square brackets. Press Enter.
2. Now, let’s look at a few slurm commands.
The main commands we will be using are srun, sbatch, squeue, scancel, and sacct. First, log into the head node (tadpole.genomecenter.ucdavis.edu).
2a. ‘srun’ is used to run a job interactively. We most often use it to start an interactive session on a compute node. Take a look at the options to srun:
srun --help
Our cluster requires that you specify a time limit for your job. If your job exceeds these limits, then it will be killed. So try running the following to create an interactive session on a node:
srun -t 00:30:00 -c 1 -n 1 --mem 500 --partition production --account workshop --reservation workshop --pty /bin/bash
This command is requesting a compute node with a time limit of 30 minutes (-t), one processor (-c), a max memory of 0.5Gb [500] (–mem), and then finally, specifying a shell to run in a terminal (“–pty” option). Run this command to get to a compute node when you want to run jobs on the command-line directly.
You safely ignore the working and error. Notice that we are no longer on tadpole, but are now on drove-13 in this example, one of our compute nodes.
use Exit on the command line to exit the session
exit
2b. ‘sbatch’ is used to submit jobs to run on the cluster. Typically it is used to run many jobs via the scheduler non-interactively. Look at the options for sbatch:
sbatch --help
Generally, we do not use any options for sbatch … we typically give it a script (i.e. a text file with commands inside) to run. Let’s take a look at a template script template.slurm:
#!/bin/bash
# options for sbatch
#SBATCH --job-name=name # Job name
#SBATCH --nodes=1 # should never be anything other than 1
#SBATCH --ntasks=1 # number of cpus to use
#SBATCH --time=30 # Acceptable time formats include "minutes", "minutes:seconds", "hours:minutes:seconds", "days-hours", "days-hours:minutes" and "days-hours:minutes:seconds".
#SBATCH --mem=500 # Memory pool for all cores (see also --mem-per-cpu)
#SBATCH --partition=production # cluster partition
#SBATCH --account=workshop # cluster account to use for the job
#SBATCH --reservation=workshop # cluster account reservation
##SBATCH --array=1-16 # Task array indexing, see https://slurm.schedmd.com/job_array.html, the double # means this line is commented out
#SBATCH --output=stdout.out # File to which STDOUT will be written
#SBATCH --error=stderr.err # File to which STDERR will be written
#SBATCH --mail-type=ALL
#SBATCH --mail-user=myemail@email.com
# for calculating the amount of time the job takes and echo the hostname
begin=`date +%s`
echo $HOSTNAME
# Sleep for 5 minutes
sleep 300
# getting end time to calculate time elapsed
end=`date +%s`
elapsed=`expr $end - $begin`
echo Time taken: $elapsed
The first line tells sbatch what scripting language (bash here) the rest of the file is in. Any line that begins with a “#” symbol is ignored by the bash interpreter, those lines that begin with “#SBATCH” are used by the slurm controller. Those lines are for specifying sbatch options without having to type them on the command-line every time. In this script, on the next set of lines, we’ve put some code for calculating the time elapsed for the job and then we simply wait for 5 minutes (300 seconds) and exit. Lets try running it
cd /share/workshop/mrnaseq_workshop/$USER
wget https://raw.githubusercontent.com/ucdavis-bioinformatics-training/2021-June-RNA-Seq-Analysis/master/software_scripts/scripts/template.slurm template.slurm
cat template.slurm
sbatch template.slurm
The non slurm version is the template.sh script. You’ll notice it looks the same only missing the #SBATCH commands.
After finishing you will see two new files in the directory stdout.out and stderr.err where stdout and stderr (respectively) were redirected to.
2c. ‘squeue’ is to list your currently queued/running jobs. T
squeue --help
Looking at the help documentation, we see that we can filter the results based on a number of criteria. The most useful option is “-u”, which you can use to see just the jobs for a particular user ID. The first column gives you the job ID of the job, the second is the partition (different queues for different types of machines), the name of the job, the user who ran the job, the state of the job (R is for running), the length of time the job has been running, the number of nodes the job is using, and finally, the node name where the job is running or a reason why the job is waiting.
squeue -u $USER
You can see the job has been running (ST=R) for 6 seconds (TIME=0:06) on node drove-12. The jobid (here 29390121) can be used to cancel the job later, or get additional job information.
2d. ‘scancel’ command is used to cancel jobs (either running or in queue).
You can give it a job ID, or if you use the “-u” option with your username, you can cancel all of your jobs at once.
scancel 29390121
will cancel the above job if its still running.
2e. ‘sacct’ command is used to get accounting data for any job that has ever run, using the job ID.
To get statistics on completed jobs by jobID (replace jobid with your jobid):
sacct -j jobid --format=JobID,JobName,MaxRSS,Elapsed
To view the same information for all jobs of a user (replace username with your username):
sacct -u username --format=JobID,JobName,MaxRSS,Elapsed
You can get more information about each command by typing “
Environment modules
1. The ‘module’ command and its sub-commands. You will NOT find the ‘module’ command on all linux computers. Using modules is generally something that is used on a shared system (like clusters) and generally installed by the system’s administrator. The module system allows to only ‘load’ software when needed as well as to make multiple versions of software available at the same time. It basically changes your PATH variable (and possibly other environment variables) so that the shell searches the correct directories for the software you want to use. First, take a look at all the software available on our system:
module avail
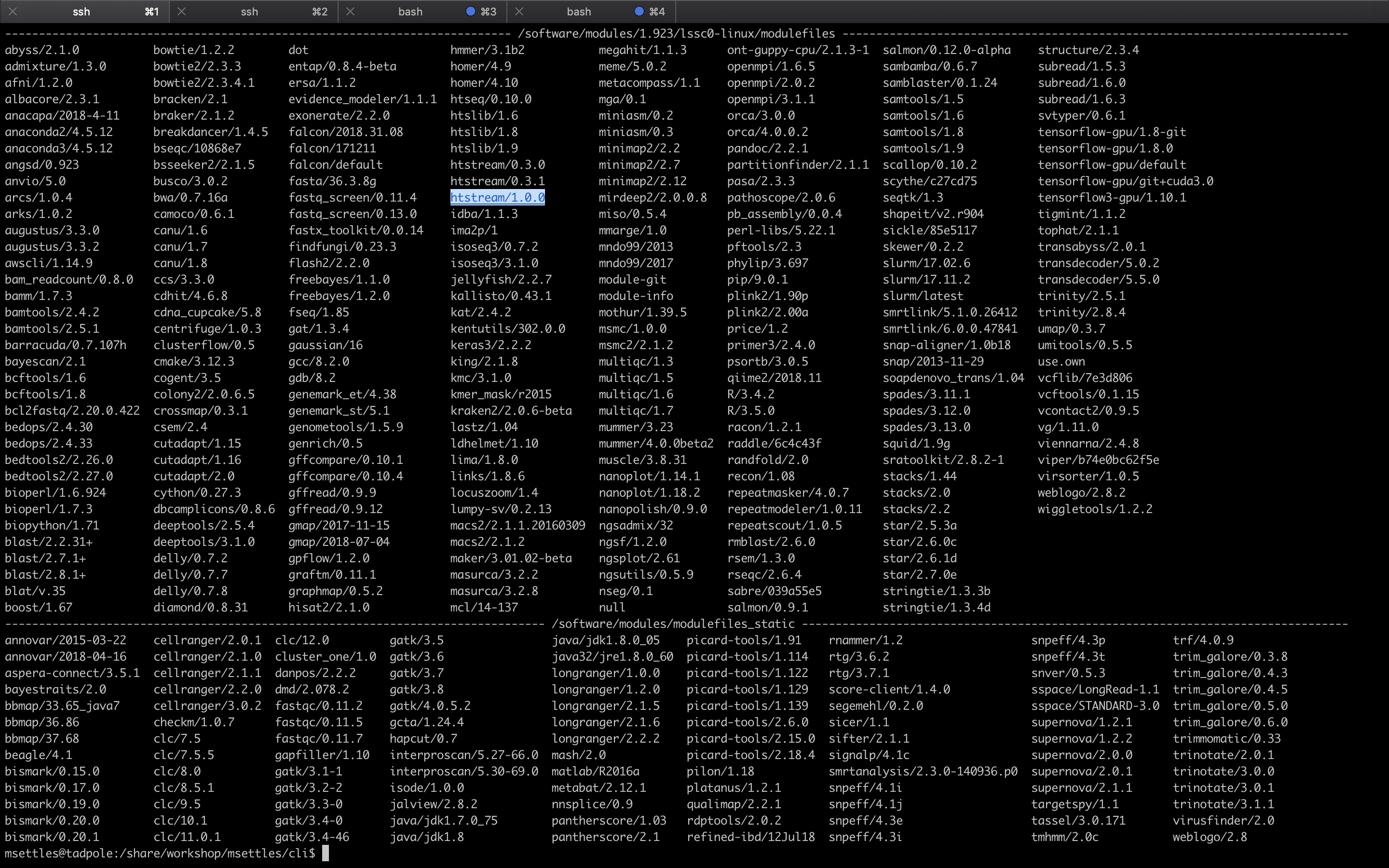
This is a list of all the software (with different versions) that you can access. The format of ‘modules’ is software/version here you can see htstream has 3 different versions installed with the latest being 1.0.0. When you load a module without specifying a version, it will load the default (generally the latest) version. If you need an older version, you need to use the cooresponding version number:
Now try running the ‘hts_Stats’ app from htstream:
hts_Stats
You should get an error saying that the command was not found. Take a look at your PATH variable.
echo $PATH
These are the directories (colon separated) that are searched for executable applications to run on the command-line. In order to access a piece of software that is not in one of these default directories, we need to use the ‘module load’ command, or set the PATH to locate it:
module load htstream/1.0.0
hts_Stats
Use the ‘which’ command to find out where the ‘hts_Stats’ command is actually located:
which hts_Stats
You’ll see that hts_Stats is located in a completely different place and yet you are able to access it. This is because the module command changes your PATH variable so that it has the correct directory. Take a look at your PATH again:
echo $PATH
You’ll see that the directory for htstream has been added to PATH.
2. A few more module sub-commands that are useful:
‘module list’ will list all of your currently loaded modules in this terminal/session.
module list
‘module unload’ will unload the module(s) you specify.
module load star
module load samtools
module list
module unload star
module list
‘module purge’ will unload all of your modules. Which simply means that it will take out the directories for all of the modules from your PATH variable. Take a look at $PATH now:
echo $PATH
module purge
module list
echo $PATH