
Generating a Gene Expression Matrix
Most analyses have two stages: data reduction and data analysis.
Statistical analyses of scRNA-seq data take as their starting point an expression matrix, where each row represents a gene and each column represents a sample (in scRNAseq columns are cells). Each entry in the matrix represents the number of reads (proxy for expression level) of a particular gene in a given sample (cell). Generating the expression matrix often involves some, or all, of the following.
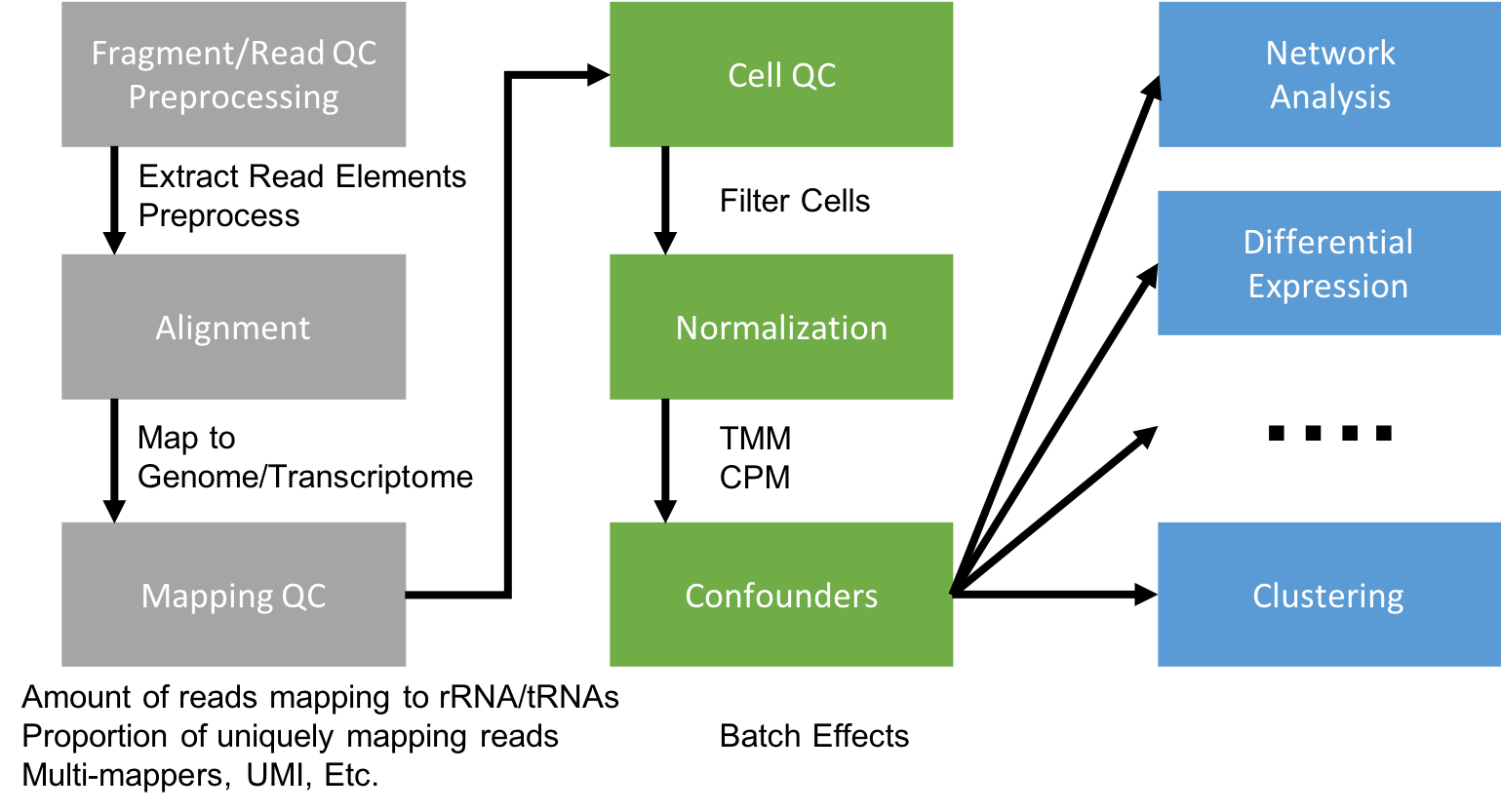
Flowchart of scRNAseq analysis
Because we are working with 10x Genomics data, we will be using the 10x Cell Ranger pipeline to handle the first column (data reduction tasks).
Preprocessing and mapping reads
Raw fastq files first need to be preprocessed, extracting any elements that are a part of the sequence read and potentially “cleaned” with applications such as HTStream.
- Library Barcode (library Index) - Used to pool multiple libraries on one sequencing lane
- Cell Barcode (10x Barcode) – Used to identify the cell the read came from
- Unique Molecular Index (UMI) – Used to identify reads that arise during PCR replication
- Sequencing Read – Used to identify the gene a read came from
The remaining sequences are mapped to a reference genome/trancriptome. Cell Ranger is based on STAR aligner. Another good choice is a pseudo-alignment method (e.g. Kallisto, Salmon). For full-length datasets with tens- or hundreds of thousands of reads per cell pseudo-aligners become appealing since their run-time can be several orders of magnitude less than traditional aligners.
Note, if spike-ins are used, the spike-in sequences should be added to the reference sequence prior to mapping.
Mapping QC
After aligning sequence data to the genome we should evaluate the quality of the mapping. There are many ways to measure the mapping quality, including: percentage mapped, amount of reads which map to rRNA/tRNAs, proportion of uniquely mapped reads, reads mapping across splice junctions, read depth along the transcripts, etc. Methods developed for bulk RNAseq, such as RSeQC and samtools, are applicable to single-cell data.
Gene Counting
STAR (and by extension, Cell Ranger), Kallisto, and Salmon all quantify the expression level of each gene for
each cell as a part of its output. If UMIs were used, duplicates need to be first marked and then gene expression levels recounted. The package UMI-tools can be used to process and correct UMIs. Cell Ranger handles UMI deduplication and cell barcode assignment internally.
Specific steps to be performed are dependent on the type of library, the element layout of the read, and the sequencing parameters.
STAR, Salmon, Kallisto/bustools each have pipelines build specifically for processing single-cell datasets and 10X genomics data.
scRNAseq Libraries
Generating scRNAseq libraries is currently an active area of research with several protocols being published in the last decade, including:
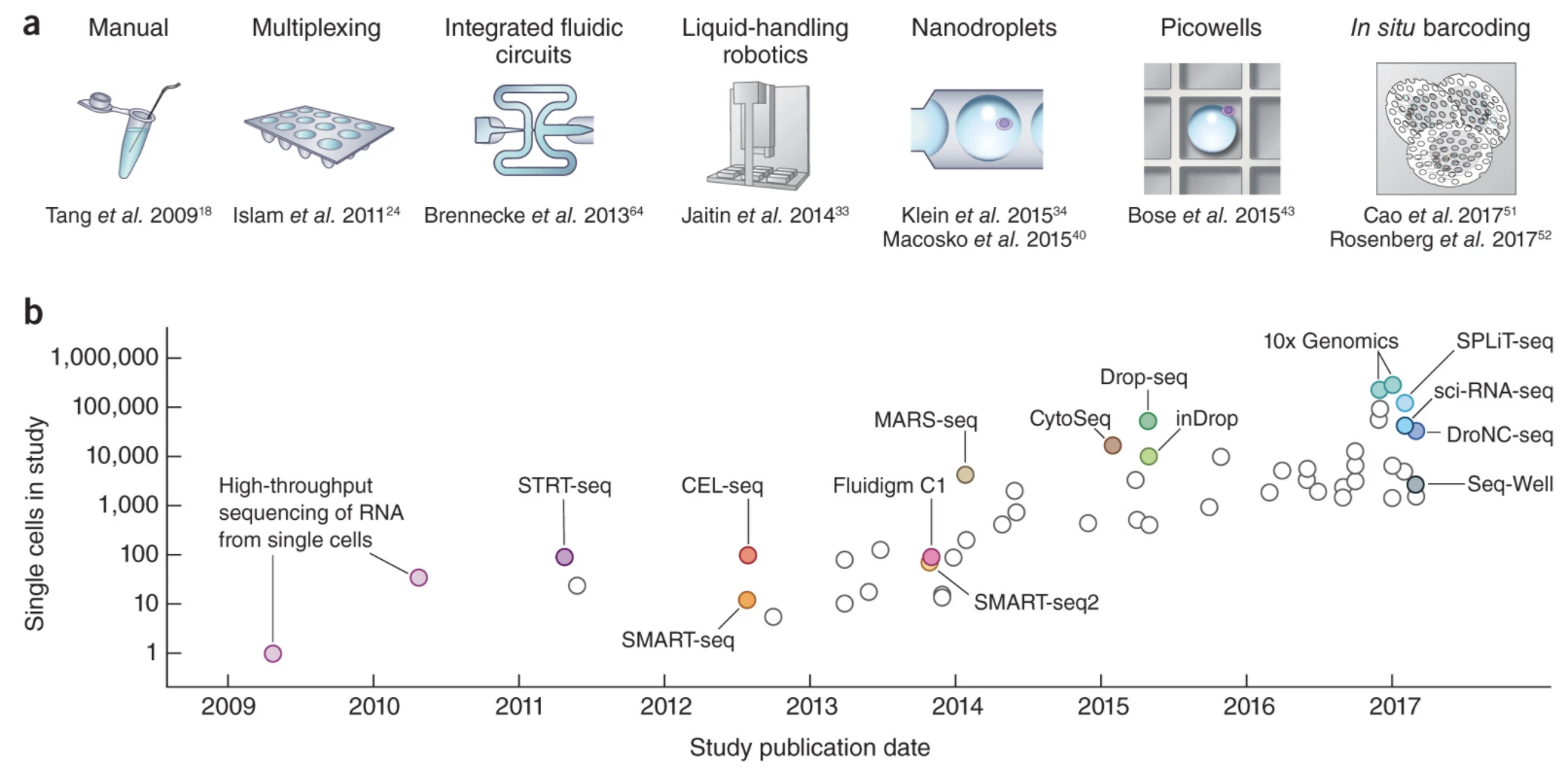
Flowchart of scRNAseq library prep protocols
Svensson, etc., 2018, Nature Protocols https://www.nature.com/articles/nprot.2017.149
- CEL-seq, Hashimshony, 2012
- CEL-seq2, Hashimshony, 2016
- DroNC-seq, Habib, 2017
- Drop-seq, Macosko, 2015
- InDrop-seq, Klein, 2015
- MATQ-seq, Sheng, 2017_2018
- MARS-seq, Jaitin, 2014
- SCRB-seq, Soumillon, 2014
- Seq-well, Gierahn, 2017
- Smart-seq, Picelli, 2014
- Smart-seq2, Picelli, 2014
- SMARTer clontech
- STRT-seq, Islam, 2014
- SplitSeq, 2018 (NOW Parse Biosciences)
- Smart-seq3, Hagemann-Jensen, 2020
- Smart-seq-total, Isakova, 2021
- VASA-seq, Salmen, 2022
Differences between the methods are in how they capture a cell and quantify gene expression (either full-length or tag-based).
Full-length capture tries to achieve a uniform coverage of each transcript (many reads per transcript). Tag-based protocols only capture either the 5’- or 3’-end of each transcript (single read per transcript). Choice in method determines what types of analyses the data can be used for. Full-length capture can be used to distinguish different iso-forms, where tag-based method is best used for only gene abundance.
- Tag-based 3’ counting techniques
- 1 read per transcript
- Based on polyA
- Expression analysis only
- Fewer reads per cell needed (~20K reads/cell 10x V3+)
- Less noise in expression patterns
- Full-length
- Based on polyA
- Expression analysis
- Splicing information
- The more information desired beyond expression, the higher the reads needed per cell (~50K reads/cell to 10M reads/cell)
For smaller experiments < 5000 cells, the R packages SingleCellExperiment, scater, SC3 are good choices. For larger experiments (> 5000 cells), the R package Seurat offers a complete solution.
If you prefer Python, scanpy is a good choice.
A nice page keeping track of single-cell software can be found here.
10X Genomics generation of expression matrix with cellranger
10X Genomics Cell Ranger uses a fork of the STAR aligner, Orbit, to map reads to a genome after first preprocessing them (extracting cell and UMI sequences).
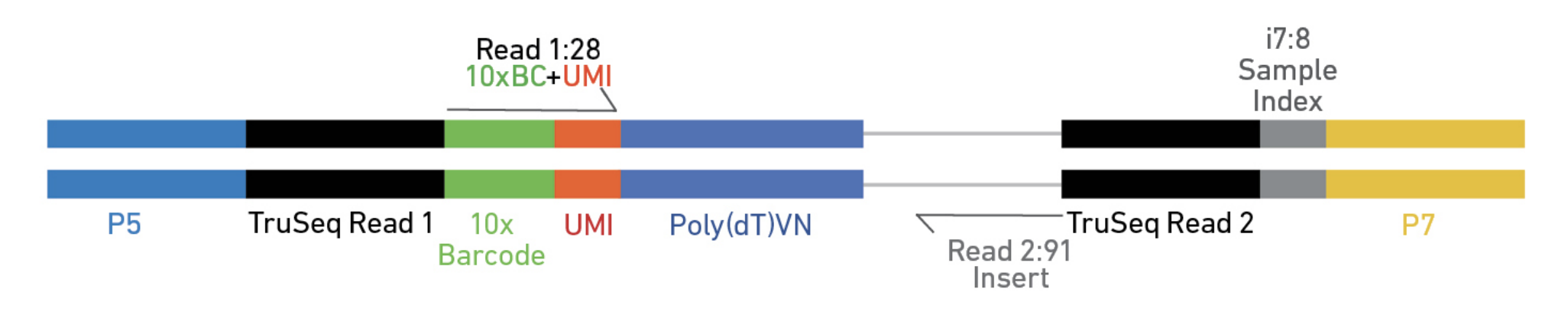
Elements to a 10x read (V3)
cellranger version 7 has many sub-applications
-
cellranger mkfastq
- cellranger count
- cellranger vdj
-
cellranger multi
- cellranger aggr
- cellranger reanalyze
- cellranger mat2csv
- cellranger targeted-compare
-
cellranger targeted-depth
- cellranger mkref
- cellranger mkgtf
-
cellranger mkvdjref
- cellranger testrun
- cellranger upload
- cellranger sitecheck
Cell barcode and UMI filtering
- Cell barcodes
- Must be on static list of known cell barcode sequences
- May be 1 mismatch away from the list if the mismatch occurs at a low- quality position (the barcode is then corrected).
- UMIs (Unique Molecular Index)
- Must not be a homopolymer, e.g. AAAAAAAAAA
- Must not contain N
- Must not contain bases with base quality < 10
- UMIs that are 1 mismatch away from a higher-count UMI are corrected to that UMI if they share a cell barcode and gene.
Read Trimming
Cell Ranger only performs read trimming to 3’ gene expression assays.
A full length cDNA construct is flanked by the 30 bp template switch oligo (TSO) sequence, AAGCAGTGGTATCAACGCAGAGTACATGGG, on the 5’ end and poly-A on the 3’ end. Some fraction of sequencing reads are expected to contain either or both of these sequences, depending on the fragment size distribution of the sequencing library. Reads derived from short RNA molecules are more likely to contain either or both TSO and poly-A sequence than longer RNA molecules.
In order to improve mapping, the TSO sequence is trimmed from the 5’ end of read 2 and poly-A is trimmed from the 3’ end prior to alignment.
Tags ts:i and pa:i in the output BAM files indicate the number of TSO nucleotides trimmed from the 5’ end of read 2 and the number of poly-A nucleotides trimmed from the 3’ end, respectively. The trimmed bases are present in the sequence of the BAM record and are soft clipped in the CIGAR string.
Alignment
Genome Alignment
Cell Ranger uses an aligner called Orbit (a wrapper around STAR), which performs splicing-aware alignment of reads to the genome. Cell Ranger uses the transcript annotation GTF to bucket the reads into exonic, intronic, and intergenic, and by whether the reads align (confidently) to the genome. A read is exonic if at least 50% of it intersects an exon, intronic if it is non-exonic and intersects an intron, and intergenic otherwise.
MAPQ adjustment
For reads that align to a single exonic locus but also align to 1 or more non-exonic loci, the exonic locus is prioritized and the read is considered to be confidently mapped to the exonic locus with MAPQ 255.
Transcriptome Alignment
Cell Ranger further aligns exonic reads to annotated transcripts, looking for compatibility. A read that is compatible with the exons of an annotated transcript, and aligned to the same strand, is considered mapped to the transcriptome. If the read is compatible with a single gene annotation, it is considered uniquely (confidently) mapped to the transcriptome. Only reads that are confidently mapped to the transcriptome are used for UMI counting.
In certain cases, such as when the input to the assay consists of nuclei, there may be high levels of intronic reads generated by unspliced transcripts. In order to count these intronic reads, the cellranger count and cellranger multi pipelines can be run with the option ‘include-introns’ in versions 5.0-6.1. Starting from version 7.0, cellranger count includes the intronic reads in quantification of gene expression by default. For cellranger multi, one can set include-introns to true to include the intronic reads.
UMI Counting
- Using only the confidently mapped reads with valid barcodes and UMIs,
- Correct the UMIs UMIs are corrected to more abundant UMIs that are one mismatch away in sequence (hamming distance = 1).
- Record which reads are duplicates of the same RNA molecule (PCR duplicates)
- Count only the unique UMIs as unique RNA molecules
- These UMI counts form an unfiltered gene-barcode matrix.
Filtering cells (the 10x way)
Cell Ranger 3.0 introduced and improved cell-calling algorithm that is better able to identify populations of low RNA content cells, especially when low RNA content cells are mixed into a population of high RNA content cells. For example, tumor samples often contain large tumor cells mixed with smaller tumor infiltrating lymphocytes (TIL) and researchers may be particularly interested in the TIL population. The new algorithm is based on the EmptyDrops method (Lun et al., 2019).
The algorithm has two key steps:
- It uses a cutoff based on total UMI counts of each GEM barcode to identify cells. This step identifies the primary mode of high RNA content cells.
- Then the algorithm uses the RNA profile of each remaining barcode to determine if it is an “empty” or a cell containing partition. This second step captures low RNA content cells whose total UMI counts may be similar to empty GEMs.
In the first step, the original cell calling algorithm is used to identify the primary mode of high RNA content cells, using a cutoff based on the total UMI count for each barcode. Cell Ranger may take as input the expected number of recovered cells, N (see –expect-cells). Let m be the 99th percentile of the top N barcodes by total UMI counts. All barcodes whose total UMI counts exceed m/10 are called as cells in the first pass.
In the second step, a set of barcodes with low UMI counts that likely represent ‘empty’ GEM partitions is selected. A model of the RNA profile of selected barcodes is created. This model, called the background model, is a multinomial distribution over genes. It uses Simple Good-Turing smoothing to provide a non-zero model estimate for genes that were not observed in the representative empty GEM set. Finally, the RNA profile of each barcode not called as a cell in the first step is compared to the background model. Barcodes whose RNA profile strongly disagrees with the background model are added to the set of positive cell calls. This second step identifies cells that are clearly distinguishable from the profile of empty GEMs, even though they may have much lower RNA content than the largest cells in the experiment.
Below is an example of a challenging cell-calling scenario where 300 high RNA content 293T cells are mixed with 2000 low RNA content PBMC cells. On the left is the cell calling result with the cell calling algorithm prior to Cell Ranger 3.0 and on the right is the current Cell Ranger 3.0 result. You can see that low RNA content cells are successfully identified by the new algorithm.
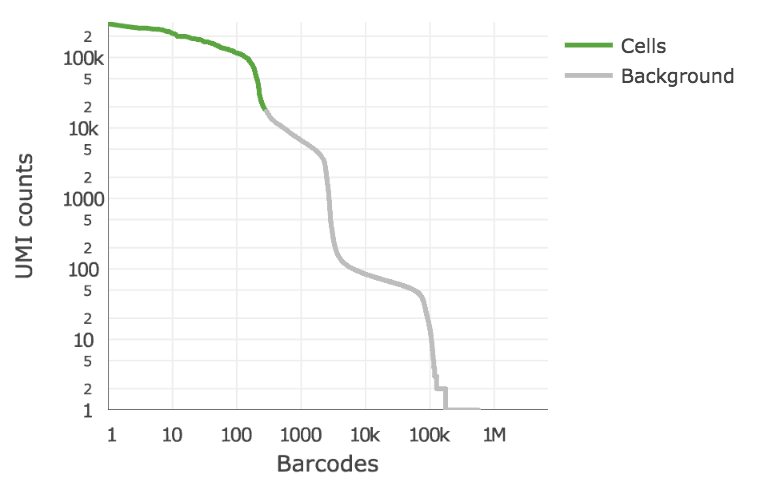
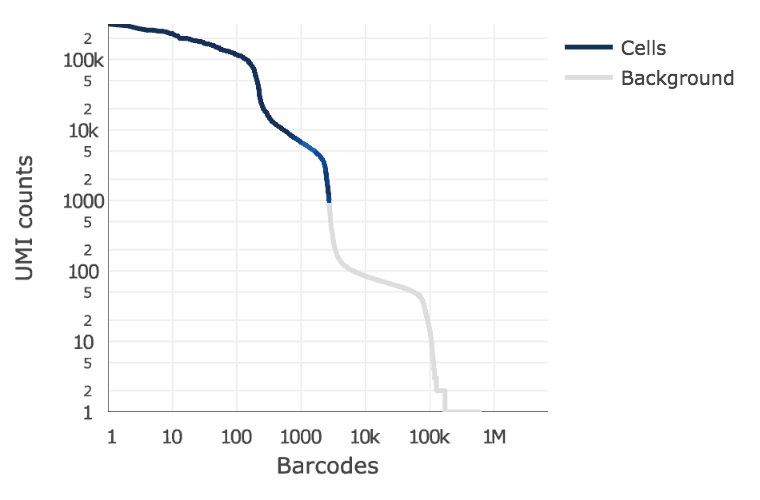
Matrix output
| Type | Description | |
|---|---|---|
| raw_feature_bc_matrix | Folder containing gene-barcode matrices. Contains every barcode from fixed list of known-good barcode sequences that have at least 1 read. This includes background and non-cellular barcodes. | |
| filtered_feature_bc_matrix | Folder containing gene-barcode matrices. Contains only detected cellular barcodes. |
Each of these folders contains three files needed to completely describe each gene x cell matrix:
- matrix.mtx.gz
- features.tsv.gz
- barcode.tsv.gz
Matrix HDF5 output
| Type | Description | |
|---|---|---|
| raw_feature_bc_matrix.h5 | hdf5 file with gene-barcode matrices Contains every barcode from fixed list of known-good barcode sequences that have at least 1 read. This includes background and non-cellular barcodes. | |
| filtered_feature_bc_matrix.h5 | hdf5 file with gene-barcode matrices Contains only detected cellular barcodes. |
HDF5 is a file format designed to preserve a hierarchical, filesystem-like organization of large amounts of data:
(root)
└── matrix [HDF5 group]
├── barcodes
├── data
├── indices
├── indptr
├── shape
└── features [HDF5 group]
├─ _all_tag_keys
├─ target_sets [for Targeted Gene Expression]
│ └─ [target set name]
├─ feature_type
├─ genome
├─ id
├─ name
├─ pattern [Feature Barcode only]
├─ read [Feature Barcode only]
└─ sequence [Feature Barcode only]
The result is a single file completely describing the gene x cell matrix, which can be read into R or Python for downstream processing.
The hdf5 has a number of advantages we’ll talk more about when we get into data analysis.
BAM output
10x Chromium cellular and molecular barcode information for each read is stored as TAG fields:
| Tag | Type | Description |
|---|---|---|
| CB | Z | Chromium cellular barcode sequence that is error-corrected and confirmed against a list of known-good barcode sequences. |
| CR | Z | Chromium cellular barcode sequence as reported by the sequencer. |
| CY | Z | Chromium cellular barcode read quality. Phred scores as reported by sequencer. |
| UB | Z | Chromium molecular barcode sequence that is error-corrected among other molecular barcodes with the same cellular barcode and gene alignment. |
| UR | Z | Chromium molecular barcode sequence as reported by the sequencer. |
| UY | Z | Chromium molecular barcode read quality. Phred scores as reported by sequencer. |
| TR | Z | Trimmed sequence. For the Single Cell 3’ v1 chemistry, this is trailing sequence following the UMI on Read 2. For the Single Cell 3’ v2 chemistry, this is trailing sequence following the cell and molecular barcodes on Read 1. |
The following TAG fields are present if a read maps to the genome and overlaps an exon by at least one base pair. A read may align to multiple transcripts and genes, but it is only considered confidently mapped to the transcriptome it if mapped to a single gene.
| Tag | Type | Description |
|---|---|---|
| TX | Z | Semicolon-separated list of transcripts that are compatible with this alignment. Transcripts are specified with the transcript_id key in the reference GTF attribute column. The format of each entry is [transcript_id],[strand][pos],[cigar], where strand is either + or -, pos is the alignment offset in transcript coordinates, and cigar is the CIGAR string in transcript coordinates. |
| AN | Z | Same as the TX tag, but for reads that are aligned to the antisense strand of annotated transcripts. If introns are included, this tag contains the corresponding antisense gene identifier. |
| GX | Z | Semicolon-separated list of gene IDs that are compatible with this alignment. Gene IDs are specified with the gene_id key in the reference GTF attribute column. |
| GN | Z | Semicolon-separated list of gene names that are compatible with this alignment. Gene names are specified with gene_name key in the reference GTF attribute column. |
| MM | i | Set to 1 if the genome-aligner (STAR) originally gave a MAPQ < 255 (it multi-mapped to the genome) and cellranger changed it to 255 because the read overlapped exactly one gene. |
| RE | A | Single character indicating the region type of this alignment (E = exonic, N = intronic, I = intergenic). |
| pa | i | The number of poly-A nucleotides trimmed from the 3’ end of read 2. Up to 10% mismatches are permitted. |
| ts | i | The number of template switch oligo (TSO) nucleotides trimmed from the 5’ end of read 2. Up to 3 mismatches are permitted. The 30-bp TSO sequence is AAGCAGTGGTATCAACGCAGAGTACATGGG. |
| xf | i | Extra alignment flags. |
The bits to the extra alignment flags are interpreted as follows:
- 1 - The read is confidently mapped to a feature
- 2 - The read maps to a feature that the majority of other reads with this UMI did not
- 4 - This read pair maps to a discordant pair of genes, and is not treated as a UMI count
- 8 - This read is representative for a transcriptomic molecule and can be treated as a UMI count
- 16 - This read maps to exactly one feature, and is identical to bit 8 for transcriptomic reads. Notably, this bit is set when a feature barcode read is treated as a UMI count, while bit 8 is not
- 32 - This read was removed by targeted UMI filtering.
The following are feature barcoding TAG fields which are not aligned to the genome, but processed by the Feature Barcoding read processor. The BAM file will contain unaligned records for these reads, with the following tags representing the Feature Barcode sequence extracted from the read, and the feature reference it was matched to, if any. The BAM read sequence will contain all the bases outside of the cell barcode and UMI regions. V3 ONLY.
| Tag | Type | Description |
|---|---|---|
| fb | Z | Chromium Feature Barcode sequence that is error-corrected and confirmed against known features barcode sequences from the feature reference. |
| fr | Z | Chromium Feature Barcode sequence as reported by the sequencer. |
| fq | Z | Chromium Feature Barcode read quality. Phred scores as reported by sequencer. |
| fx | Z | Feature identifier matched to this Feature Barcode read. Specified in the id column of the feature reference. |
An example read
Cell Ranger Version 6
A01102:107:HHM5TDSXY:3:1128:6659:34601 147 chr1 1014050 255 151M = 1013467 -734 TCGGTGTCAGAGCTGAAGGCGCAGATCACCCAGAAGATCGGCGTGCACGCCTTCCAGCAGCGTCTGGCTGTCCACCCGAGCGGTGTGGCGCTGCAGGACAGGGTCCCCCTTGCCAGCCAGGGCCTGGGCCCCGGCAGCACGGTCCTGCTGG FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF NH:i:1 HI:i:1 AS:i:249 nM:i:2 RG:Z:PBMC2sm:0:1:HHM5TDSXY:3 TX:Z:ENST00000624652,+271,151M;ENST00000624697,+296,151M;ENST00000649529,+146,151M GX:Z:ENSG00000187608 GN:Z:ISG15 fx:Z:ENSG00000187608 RE:A:E xf:i:25 CR:Z:CCGTGGAGTCAGAGGT CY:Z:FFFFFF:FFFFFFFFF CB:Z:CCGTGGAGTCAGAGGT-1 UR:Z:CCACGGGGAT UY:Z:FFFFFFFFFF UB:Z:CCACGGGGAT
10X Genomics sample report
A summary of the alignment and assignment of reads to cells and genes is present in the metrics_summary.csv.
| Metric | Description |
|---|---|
| Estimated Number of Cells | The number of barcodes associated with cell-containing partitions, estimated from the barcode UMI count distribution. |
| Mean Reads per Cell | The total number of sequenced reads divided by the estimated number of cells. |
| Median Genes per Cell | The median number of genes detected (with nonzero UMI counts) across all cell-associated barcodes. |
| Number of Reads | Total number of sequenced reads. |
| Valid Barcodes | Fraction of reads with cell-barcodes that match the whitelist. |
| Sequencing Saturation | The fraction of reads originating from an already-observed UMI. This is a function of library complexity and sequencing depth. More specifically, this is the fraction of confidently mapped, valid cell-barcode, valid UMI reads that had a non-unique (cell-barcode, UMI, gene). This metric was called “cDNA PCR Duplication” in versions of cellranger prior to 1.2. |
| Q30 Bases in Barcode | Fraction of bases with Q-score at least 30 in the cell barcode sequences. This is the i7 index (I1) read for the Single Cell 3’ v1 chemistry and the R1 read for the Single Cell 3’ v2 chemistry. |
| Q30 Bases in RNA Read | Fraction of bases with Q-score at least 30 in the RNA read sequences. This is Illumina R1 for the Single Cell 3’ v1 chemistry and Illumina R2 for the Single Cell 3’ v2 chemistry. |
| Q30 Bases in Sample Index | Fraction of bases with Q-score at least 30 in the sample index sequences. This is the i5 index (I2) read for the Single Cell 3’ v1 chemistry and the i7 index (I1) read for the Single Cell 3’ v2 chemistry. |
| Q30 Bases in UMI | Fraction of bases with Q-score at least 30 in the UMI sequences. This is the R2 read for the Single Cell 3’ v1 chemistry and the R1 read for the Single Cell 3’ v2 chemistry. |
| Reads Mapped to Genome | Fraction of reads that mapped to the genome. |
| Reads Mapped Confidently to Genome | Reads Mapped Confidently to Genome. |
| Reads Mapped Confidently to Intergenic Regions | Fraction of reads that mapped to the intergenic regions of the genome with a high mapping quality score as reported by the aligner. |
| Reads Mapped Confidently to Intronic Regions | Fraction of reads that mapped to the intronic regions of the genome with a high mapping quality score as reported by the aligner. |
| Reads Mapped Confidently to Exonic Regions | Fraction of reads that mapped to the exonic regions of the genome with a high mapping quality score as reported by the aligner. |
| Reads Mapped Confidently to Transcriptome | Fraction of reads that mapped to a unique gene in the transcriptome with a high mapping quality score as reported by the aligner. |
| Reads Mapped Antisense to Gene | Fraction of reads confidently mapped to the transcriptome, but on the opposite strand of their annotated gene. A read is counted as antisense if it has any alignments that are consistent with an exon of a transcript but antisense to it, and has no sense alignments. |
| Fraction Reads in Cells | The fraction of cell-barcoded, confidently mapped reads with cell-associated barcodes. |
| Total Genes Detected | The number of genes with at least one UMI count in any cell. |
| Median UMI Counts per Cell | The median number of total UMI counts across all cell-associated barcodes. |
10X genomics html reports
Cell Ranger does produce a more readable HTML report with the same statistics and some “analysis”.
Exercises
-
Log into tadpole with the username/password
cd /share/workshop/scRNA_workshop/$USER/scrnaseq_example -
Load and review cellranger’s sub-applications and help docs
module load cellranger/7.0.0 -
Review the cellranger-counts.sh script used to map reads in the fastq files.
-
Copy contents of the script to your scrnaseq_example folder and do a test run.
cd /share/workshop/scRNA_workshop/$USER/scrnaseq_example wget https://raw.githubusercontent.com/ucdavis-bioinformatics-training/2022-July-Single-Cell-RNA-Seq-Analysis/main/software_scripts/scripts/cellranger-counts.shupdate the email address in the script if you like.
sbatch cellranger-counts.sh -
Link completed result folders to your scrnaseq_example folders.
cd /share/workshop/scRNA_workshop/$USER/scrnaseq_example ln -s /share/workshop/scRNA_workshop/cellranger.outs/A001-C-007 ./A001-C-007-copy- In the folder A001-C-007-copy, which output folders/files were generated from this script?
- Review the metrics_summary.csv file
- What where the total number of reads in this sample?
- Reads Mapped Confidently to transcriptome?
- Sequencing Saturation?
- Mean Reads per Cell?
- Median UMI Counts per Cell?
- head the files under raw_feature_bc_matrix and filtered_feature_bc_matrix
- Transfer the html file to your computer
- Transfer the matrix files and hdf5 file to your computer. (However, we will be using data from the full datasets for all three samples instead of this subset).
In the intereste of time, the dataset we use for this step is a small subset of the original data. The cellranger summary file is here
Bonus: cellranger features and multi pipeline
Feature barcodes allow you to capture additional information within your cells by using an addition oligo on the GEM beads. This can be from Antibody capture, Crispr guide capture, or a custom capture (like hash tagging).
To do so you need to pass a library csv file and a feature (only 1 feature possible at a time) reference file.
```
cellranger count --id=sample \
--libraries=library.csv \
--transcriptome=/opt/refdata-gex-GRCh38-2020-A \
--feature-ref=feature_ref.csv \
--expect-cells=1000 ```
Library csv file
3 columns
- fastq - path to fastq files
- sample - name of the fastq file
- library_type one of Gene Expression, Custom, Antibody Capture, or CRISPR Guide Capture
fastqs,sample,library_type
/opt/foo/,GEX_sample1,Gene Expression
/opt/foo/,CRISPR_sample1,CRISPR Guide Capture
Feature Reference file
- id - Unique ID
- name - Human-readable name
- read - Which read do I expect to find the feature barcode in
- pattern - The pattern within the read
- sequence - The barcode sequence
- feature_type - Type of feature, same as above
id,name,read,pattern,sequence,feature_type
CD3,CD3_TotalC,R2,^NNNNNNNNNN(BC)NNNNNNNNN,CTCATTGTAACTCCT,Antibody Capture
CD19,CD19_TotalC,R2,^NNNNNNNNNN(BC)NNNNNNNNN,CTGGGCAATTACTCG,Antibody Capture
CD45RA,CD45RA_TotalC,R2,^NNNNNNNNNN(BC)NNNNNNNNN,TCAATCCTTCCGCTT,Antibody Capture
CD4,CD4_TotalC,R2,^NNNNNNNNNN(BC)NNNNNNNNN,TGTTCCCGCTCAACT,Antibody Capture
CD8a,CD8a_TotalC,R2,^NNNNNNNNNN(BC)NNNNNNNNN,GCTGCGCTTTCCATT,Antibody Capture
See Feature Barcode Analysis for more information.
Cellranger multi
Cell Ranger 6.0 introduced the multi pipeline which is required for use with CellPlex, and can can be used to ‘join’ features, V(D)J, and counts into a single analysis.
cellranger multi requires an ID for output and a configuration csv (which really isn’t a csv).
Multi Config CSV
Section: [gene-expression]
| Field | Description |
|---|---|
| reference | Path of folder containing 10x-compatible reference. Required for gene expression and Feature Barcode libraries. |
| cmo-set | Optional. CMO set CSV file, declaring CMO constructs and associated barcodes. |
| target-panel | Optional. Path to a target panel CSV file or name of a 10x Genomics fixed gene panel (pathway, pan-cancer, immunology, neuroscience). |
| no-target-umi-filter | Optional. Disable targeted UMI filtering stage. Default: false. |
| r1-length | Optional. Hard trim the input Read 1 of gene expression libraries to this length before analysis. Default: do not trim Read 1. |
| r2-length | Optional. Hard trim the input Read 2 of gene expression libraries to this length before analysis. Default: do not trim Read 2. |
| chemistry | Optional. Assay configuration. NOTE: by default, the assay configuration is detected automatically, which is the recommended mode. Users usually will not need to specify a chemistry. Options are: ‘auto’ for autodetection, ‘threeprime’ for Single Cell 3’, ‘fiveprime’ for Single Cell 5’, ‘SC3Pv1’ or ‘SC3Pv2’ or ‘SC3Pv3’ for Single Cell 3’ v1/v2/v3, ‘SC5P-PE’ or ‘SC5P-R2’ for Single Cell 5’, paired-end/R2-only, ‘SC-FB’ for Single Cell Antibody-only 3’ v2 or 5’. Default: auto. |
| expect-cells | Optional. Expected number of recovered cells. Default: 3000. |
| force-cells | Optional. Force pipeline to use this number of cells, bypassing cell detection. Default: detect cells using EmptyDrops. |
| include-introns | Optional. Include intronic reads in count. Default: false |
| no-secondary | Optional. Disable secondary analysis, e.g. clustering. Default: false. |
| no-bam | Optional. Do not generate a bam file. Default: false. |
Section: [feature]
| Field | Description |
|---|---|
| reference | Feature reference CSV file, declaring Feature Barcode constructs and associated barcodes. Required for Feature Barcode libraries, otherwise optional. |
| r1-length | Optional. Hard trim the input Read 1 of Feature Barcode libraries to this length before analysis. Default: do not trim Read 1. |
| r2-length | Optional. Hard trim the input Read 2 of Feature Barcode libraries to this length before analysis. Default: do not trim Read 2. |
Section: [libraries] (see also Specifying Input FASTQ Files for cellranger multi)
| Column | Description |
|---|---|
| fastq_id | Required. The Illumina sample name to analyze. This will be as specified in the sample sheet supplied to mkfastq or bcl2fastq. |
| fastqs | Required. The folder containing the FASTQ files to be analyzed. Generally, this will be the fastq_path folder generated by cellranger mkfastq. |
| lanes | Optional. The lanes associated with this sample, separated by. Defaults to using all lanes. |
| feature_types | Required. The underlying feature type of the library, which must be one of ‘Gene Expression’ (3’ and 5’), ‘VDJ’ (5’ only), ‘VDJ-T’ (5’ only), ‘VDJ-B’ (5’ only), ‘Antibody Capture’ (3’ and 5’), ‘CRISPR Guide Capture’ (3’ only), or ‘Multiplexing Capture’ (3’ only). |
| subsample_rate | Optional. The rate at which reads from the provided FASTQ files are sampled. Must be strictly greater than 0 and less than or equal to 1. |
Section: [samples]
| Column | Description |
|---|---|
| sample_id | A name to identify a multiplexed sample. Must be alphanumeric with hyphens and/or underscores, and less than 64 characters. Required for cell multiplexing libraries. |
| cmo_ids | The cell multiplexing oligo IDs used to multiplex this sample, separated by. Required for cell multiplexing libraries. |
| description | Optional. A description for the sample. |