
Last Updated: March 20 2022
Part 5:
Load libraries
library(Seurat)
library(ggplot2)
library(dplyr)
Load the Seurat object
load(file="pca_sample_corrected.RData")
experiment.aggregate
So how many features should we use? Use too few and your leaving out interesting variation that may define cell types, use too many and you add in noise? maybe?
Lets choose the first 25, based on our prior part.
use.pcs = 1:25
Identifying clusters
Seurat implements an graph-based clustering approach. Distances between the cells are calculated based on previously identified PCs.
The default method for identifying k-nearest neighbors has been changed in V4 to annoy (“Approximate Nearest Neighbors Oh Yeah!). This is an approximate nearest-neighbor approach that is widely used for high-dimensional analysis in many fields, including single-cell analysis. Extensive community benchmarking has shown that annoy substantially improves the speed and memory requirements of neighbor discovery, with negligible impact to downstream results.
Seurat prior approach was heavily inspired by recent manuscripts which applied graph-based clustering approaches to scRNAseq data. Briefly, Seurat identified clusters of cells by a shared nearest neighbor (SNN) modularity optimization based clustering algorithm. First calculate k-nearest neighbors (KNN) and construct the SNN graph. Then optimize the modularity function to determine clusters. For a full description of the algorithms, see Waltman and van Eck (2013) The European Physical Journal B. You can switch back to using the previous default setting using nn.method=”rann”.
The FindClusters function implements the neighbor based clustering procedure, and contains a resolution parameter that sets the granularity of the downstream clustering, with increased values leading to a greater number of clusters. I tend to like to perform a series of resolutions, investigate and choose.
?FindNeighbors
experiment.aggregate <- FindNeighbors(experiment.aggregate, reduction="pca", dims = use.pcs)
experiment.aggregate <- FindClusters(
object = experiment.aggregate,
resolution = seq(0.25,4,0.5),
verbose = FALSE
)
Seurat add the clustering information to the metadata beginning with RNA_snn_res. followed by the resolution
head(experiment.aggregate[[]])
Lets first investigate how many clusters each resolution produces and set it to the smallest resolutions of 0.5 (fewest clusters).
sapply(grep("res",colnames(experiment.aggregate@meta.data),value = TRUE),
function(x) length(unique(experiment.aggregate@meta.data[,x])))
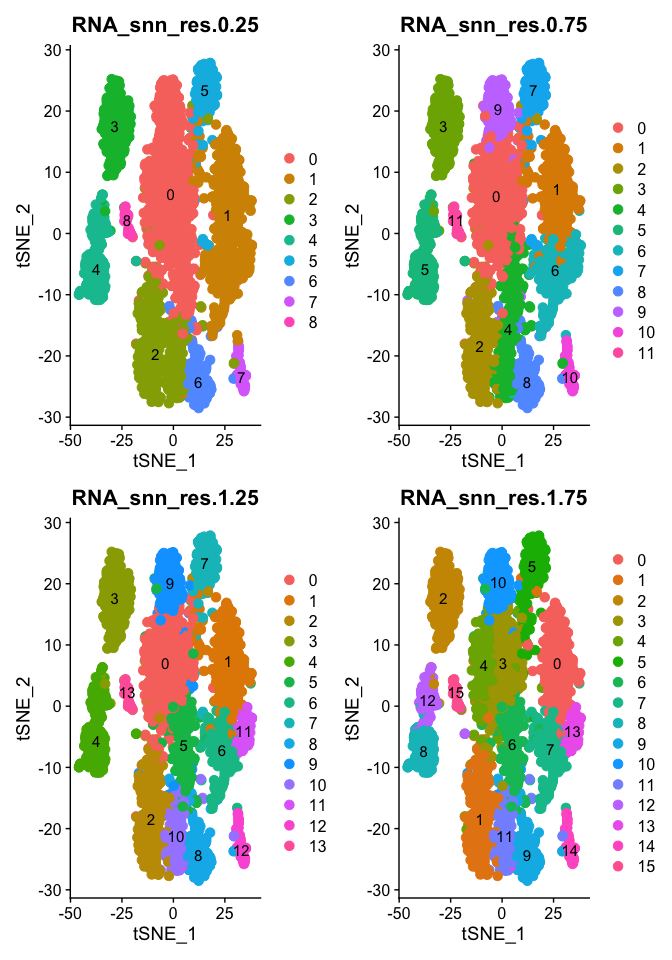
Plot TSNE coloring for each resolution
tSNE dimensionality reduction plots are then used to visualize clustering results. As input to the tSNE, you should use the same PCs as input to the clustering analysis.
experiment.aggregate <- RunTSNE(
object = experiment.aggregate,
reduction.use = "pca",
dims = use.pcs,
do.fast = TRUE)
DimPlot(object = experiment.aggregate, group.by=grep("res",colnames(experiment.aggregate@meta.data),value = TRUE)[1:4], ncol=2 , pt.size=3.0, reduction = "tsne", label = T)
DimPlot(object = experiment.aggregate, group.by=grep("res",colnames(experiment.aggregate@meta.data),value = TRUE)[5:8], ncol=2 , pt.size=3.0, reduction = "tsne", label = T)
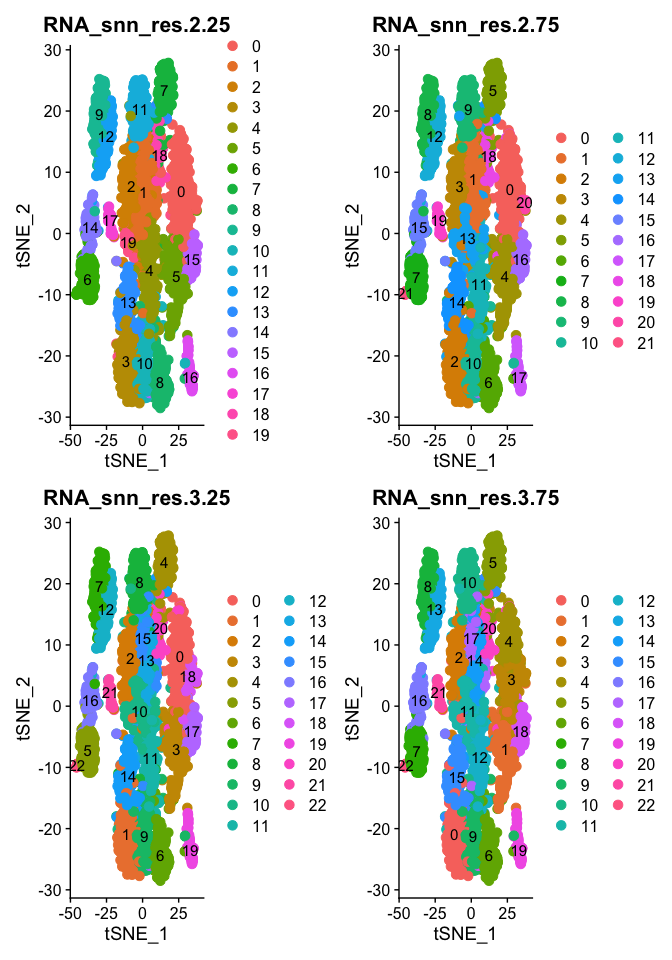
- Try exploring different PCS, so first 5, 10, 15, we used 25, what about 100? How does the clustering change?
Once complete go back to 1:25
Choosing a resolution
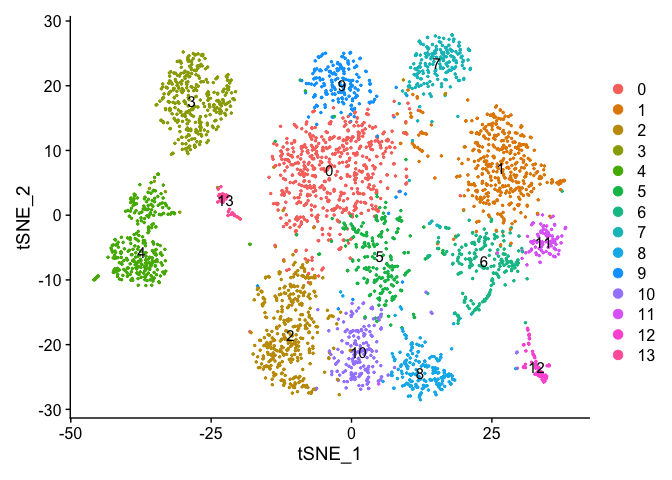
Lets set the default identity to a resolution of 1.25 and produce a table of cluster to sample assignments.
Idents(experiment.aggregate) <- "RNA_snn_res.1.25"
table(Idents(experiment.aggregate),experiment.aggregate$orig.ident)
Plot TSNE coloring by the slot ‘ident’ (default).
DimPlot(object = experiment.aggregate, pt.size=0.5, reduction = "tsne", label = T)
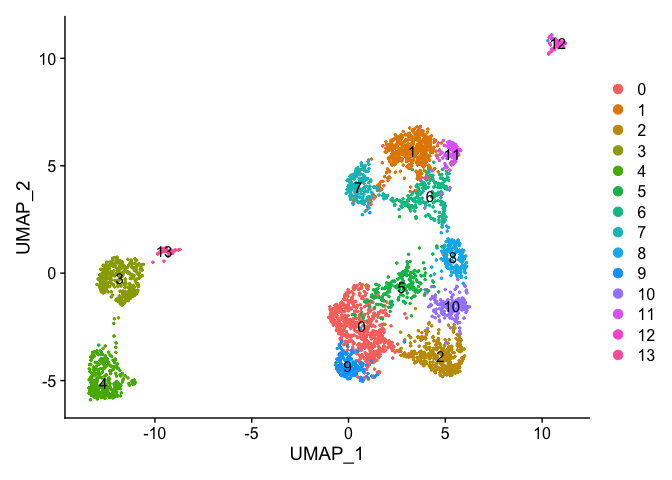
uMAP dimensionality reduction plot.
experiment.aggregate <- RunUMAP(
object = experiment.aggregate,
dims = use.pcs)
Plot uMap coloring by the slot ‘ident’ (default).
DimPlot(object = experiment.aggregate, pt.size=0.5, reduction = "umap", label = T)
Catagorical data can be plotted using the DimPlot function.
TSNE plot by cell cycle
DimPlot(object = experiment.aggregate, pt.size=0.5, group.by = "Phase", reduction = "umap" )
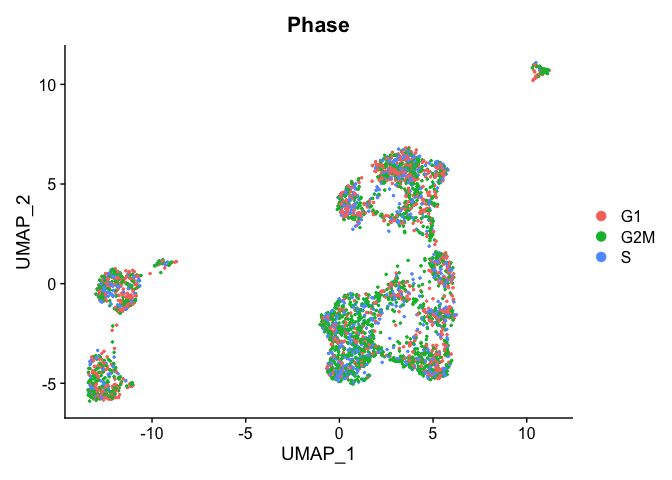
- Try creating a table, of cluster x cell cycle
Can use feature plot to plot our read valued metadata, like nUMI, Feature count, and percent Mito
FeaturePlot can be used to color cells with a ‘feature’, non categorical data, like number of UMIs
FeaturePlot(experiment.aggregate, features = c('nCount_RNA'), pt.size=0.5)
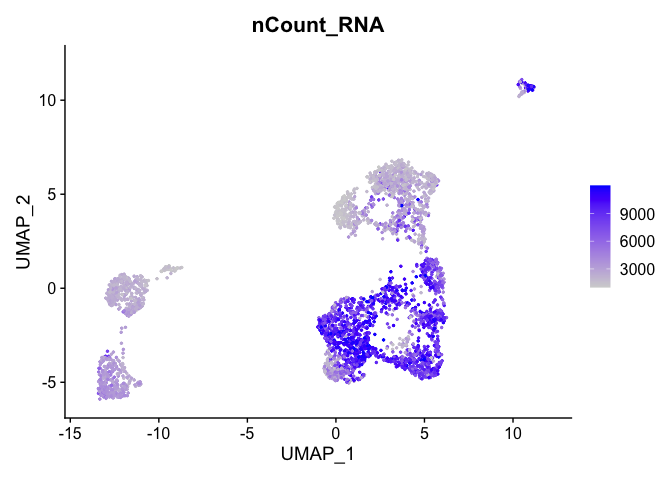 and number of genes present
and number of genes present
FeaturePlot(experiment.aggregate, features = c('nFeature_RNA'), pt.size=0.5)
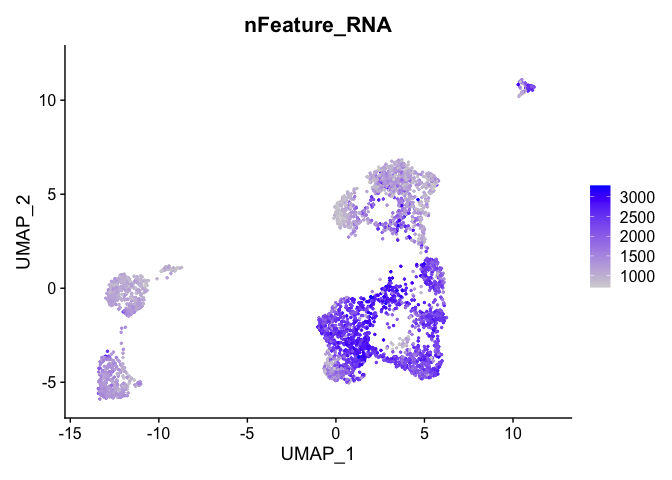
percent mitochondrial
FeaturePlot(experiment.aggregate, features = c('percent.mito'), pt.size=0.5)
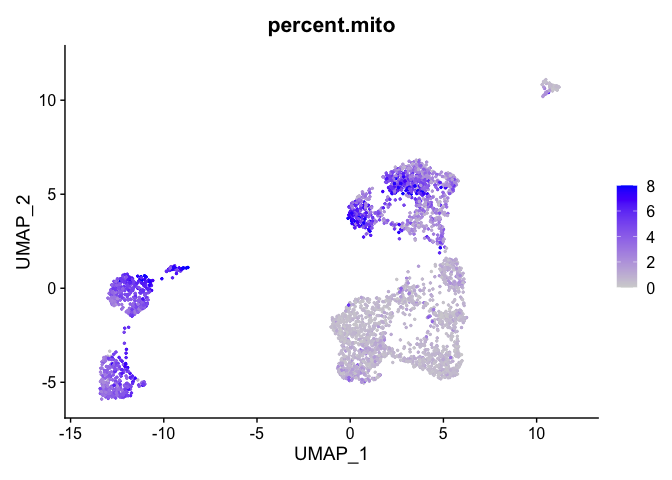
Building a phylogenetic tree relating the ‘average’ cell from each group in default ‘Ident’ (currently “RNA_snn_res.1.25”). Tree is estimated based on a distance matrix constructed in either gene expression space or PCA space.
Idents(experiment.aggregate) <- "RNA_snn_res.1.25"
experiment.aggregate <- BuildClusterTree(
experiment.aggregate, dims = use.pcs)
PlotClusterTree(experiment.aggregate)
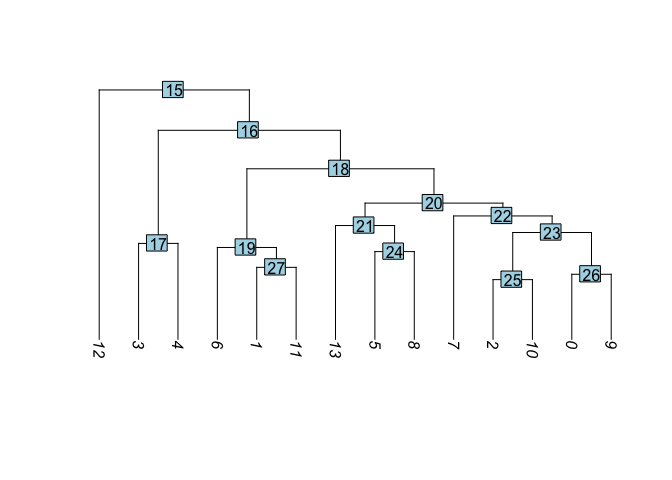
- Create new trees of other data
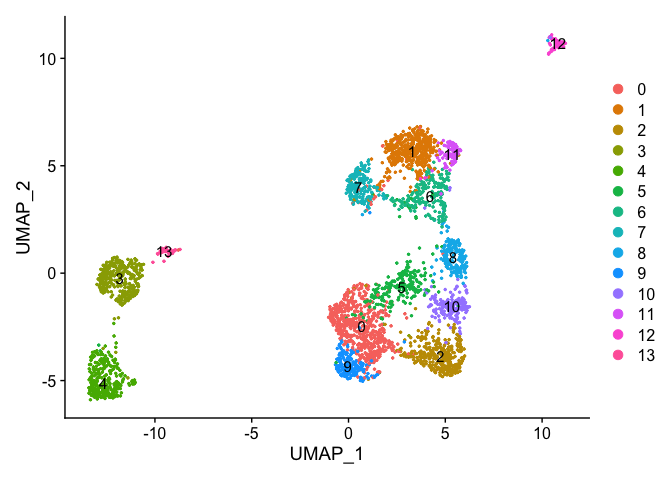
Once complete go back to Res 1.25
DimPlot(object = experiment.aggregate, pt.size=0.5, label = TRUE, reduction = "umap")
DimPlot(experiment.aggregate, pt.size = 0.5, label = TRUE, reduction = "tsne")
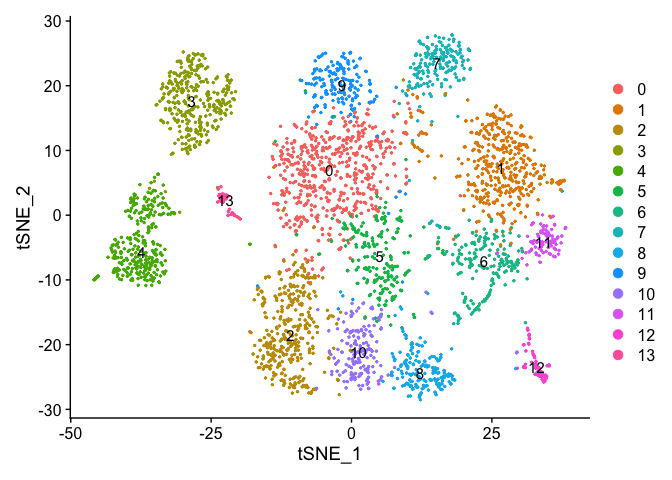
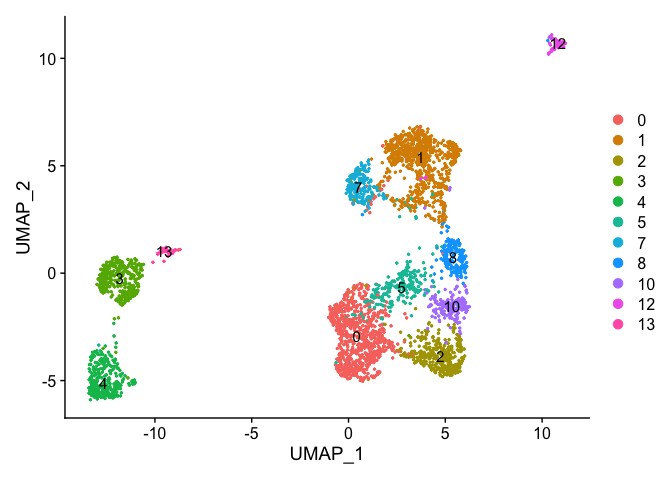
Merging clusters
Merge Clustering results, so lets say clusters 0, and 9 are actually the same cell type and we don’t wish to separate them out as distinct clusters. Same with 1, 6, and 11.
experiment.merged = experiment.aggregate
Idents(experiment.merged) <- "RNA_snn_res.1.25"
experiment.merged <- RenameIdents(
object = experiment.merged,
'9' = '0',
'6' = '1',
'11' = '1'
)
table(Idents(experiment.merged))
DimPlot(object = experiment.merged, pt.size=0.5, label = T, reduction = "umap")
DimPlot(experiment.merged, pt.size = 0.5, label = TRUE, reduction = "tsne" )
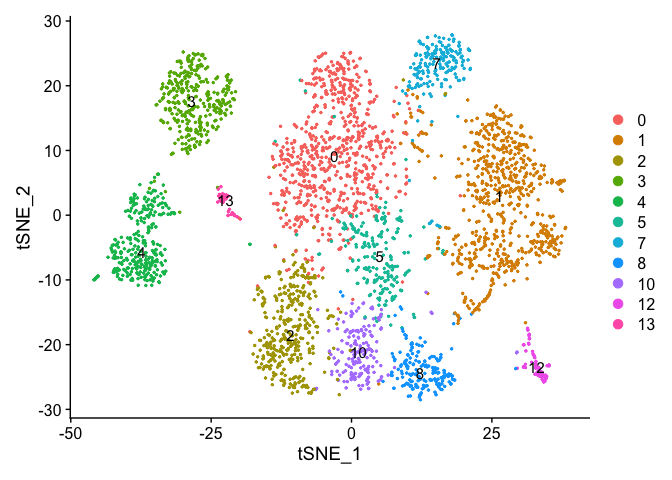
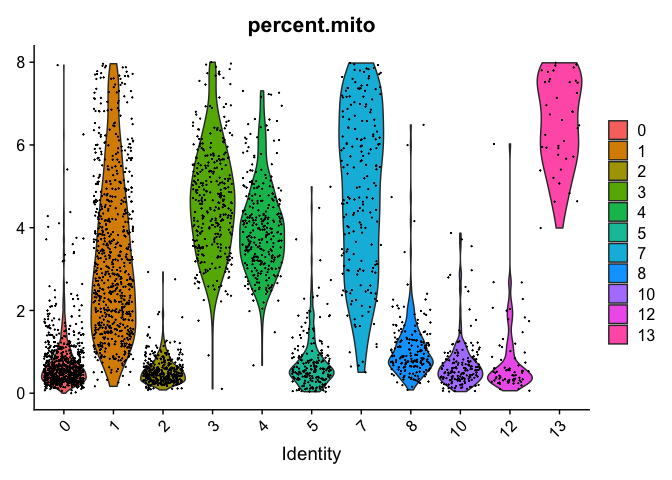
VlnPlot(object = experiment.merged, features = "percent.mito", pt.size = 0.05)
Reording the clusters
In order to reorder the clusters for plotting purposes take a look at the levels of the Ident, which indicates the ordering, then relevel as desired.
experiment.examples <- experiment.merged
levels(experiment.examples@active.ident)
experiment.examples@active.ident <- relevel(experiment.examples@active.ident, "12")
levels(experiment.examples@active.ident)
# now cluster 12 is the "first" factor
DimPlot(object = experiment.examples, pt.size=0.5, label = T, reduction = "umap")
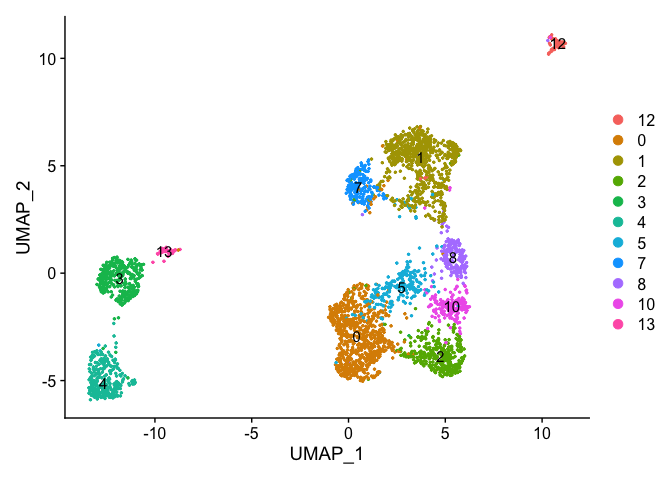
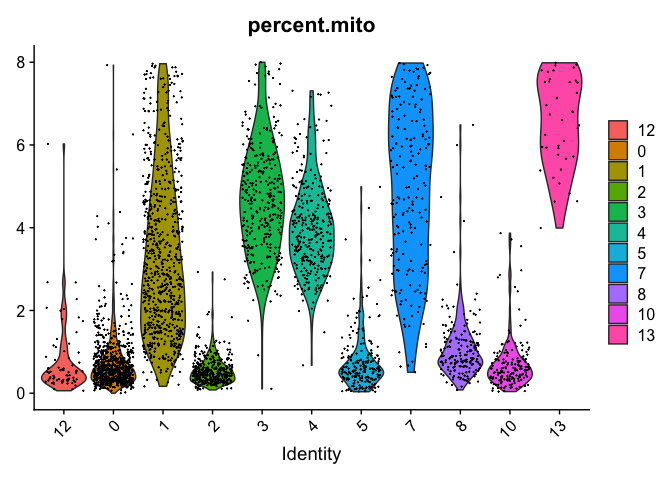
VlnPlot(object = experiment.examples, features = "percent.mito", pt.size = 0.05)
# relevel all the factors to the order I want
Idents(experiment.examples) <- factor(experiment.examples@active.ident, levels=c("12","3","4","13","0","1","2","5","7", "8", "10"))
levels(experiment.examples@active.ident)
DimPlot(object = experiment.examples, pt.size=0.5, label = T, reduction = "umap")
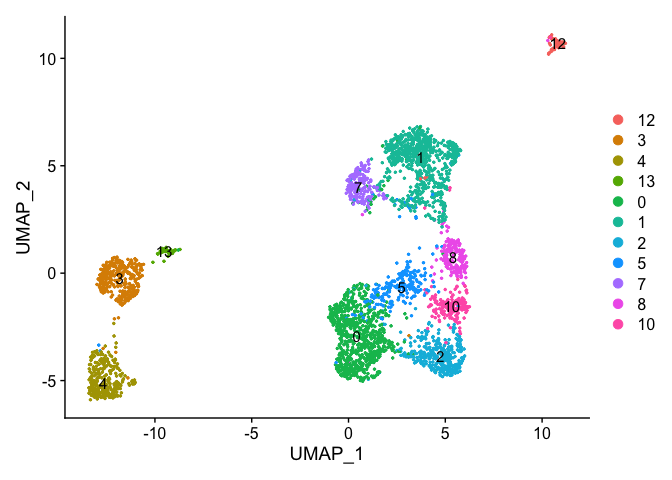
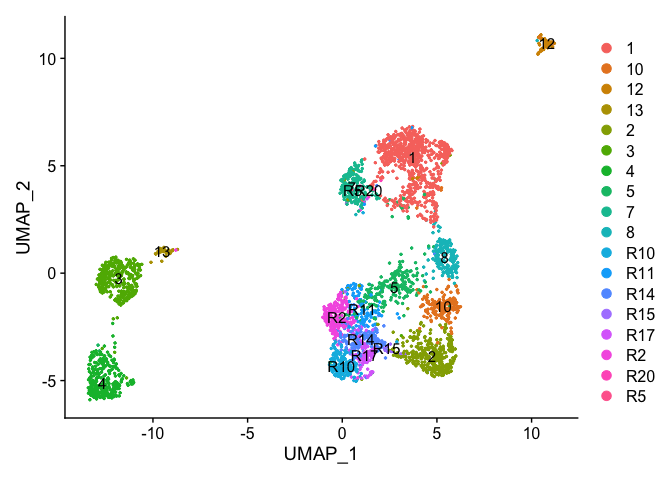
Re-assign clustering result (subclustering only cluster 0) to clustering for resolution 3.75 (@ reslution 0.25) [adding a R prefix]
newIdent = as.character(Idents(experiment.examples))
newIdent[newIdent == '0'] = paste0("R",as.character(experiment.examples$RNA_snn_res.3.75[newIdent == '0']))
Idents(experiment.examples) <- as.factor(newIdent)
table(Idents(experiment.examples))
DimPlot(object = experiment.examples, pt.size=0.5, label = T, reduction = "umap")
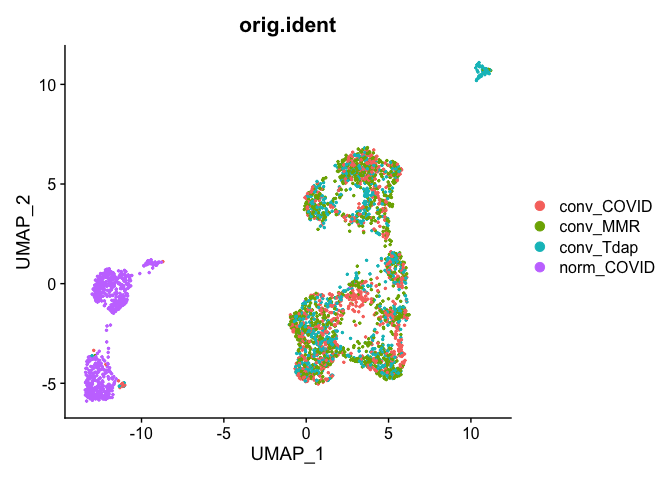
Plot UMAP coloring by the slot ‘orig.ident’ (sample names) with alpha colors turned on. A pretty picture
DimPlot(object = experiment.aggregate, group.by="orig.ident", pt.size=0.5, reduction = "umap", shuffle = TRUE)
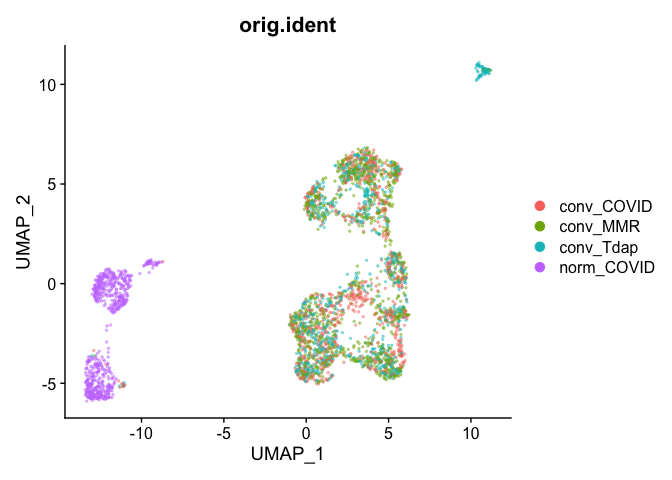
## Pretty umap using alpha
alpha.use <- 2/5
p <- DimPlot(object = experiment.aggregate, group.by="orig.ident", pt.size=0.5, reduction = "umap", shuffle = TRUE)
p$layers[[1]]$mapping$alpha <- alpha.use
p + scale_alpha_continuous(range = alpha.use, guide = F)
Removing cells assigned to clusters from a plot, So here plot all clusters but cluster 6 (contaminant?)
# create a new tmp object with those removed
experiment.aggregate.tmp <- experiment.aggregate[,-which(Idents(experiment.aggregate) %in% c("7"))]
dim(experiment.aggregate)
dim(experiment.aggregate.tmp)
DimPlot(object = experiment.aggregate.tmp, pt.size=0.5, reduction = "umap", label = T)
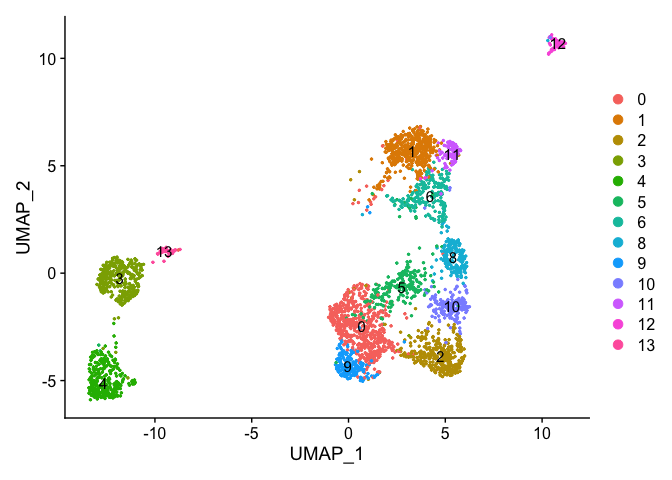
Identifying Marker Genes
Seurat can help you find markers that define clusters via differential expression.
FindMarkers identifies markers for a cluster relative to all other clusters.
FindAllMarkers does so for all clusters
FindAllMarkersNode defines all markers that split a Node from the cluster tree
?FindMarkers
markers = FindMarkers(experiment.aggregate, ident.1=c(3,7), ident.2 = c(4,5))
head(markers)
dim(markers)
table(markers$avg_log2FC > 0)
table(markers$p_val_adj < 0.05 & markers$avg_log2FC > 0)
pct.1 and pct.2 are the proportion of cells with expression above 0 in ident.1 and ident.2 respectively. p_val is the raw p_value associated with the differntial expression test with adjusted value in p_val_adj. avg_logFC is the average log fold change difference between the two groups.
avg_diff (lines 130, 193 and) appears to be the difference in log(x = mean(x = exp(x = x) - 1) + 1) between groups. It doesn’t seem like this should work out to be the signed ratio of pct.1 to pct.2 so I must be missing something. It doesn’t seem to be related at all to how the p-values are calculated so maybe it doesn’t matter so much, and the sign is probably going to be pretty robust to how expression is measured.
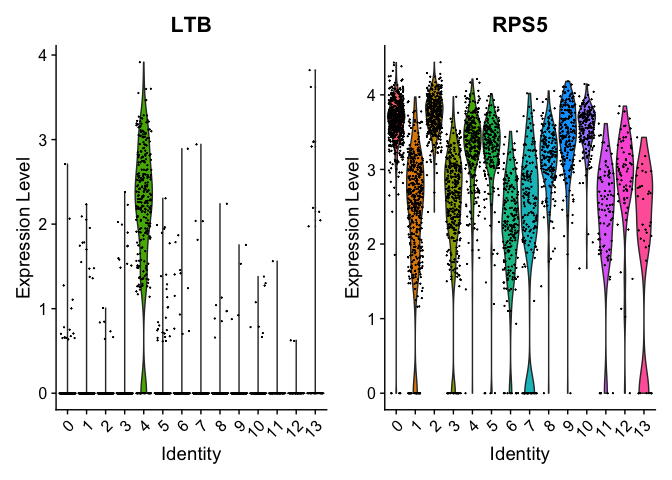
Can use a violin plot to visualize the expression pattern of some markers
VlnPlot(object = experiment.aggregate, features = rownames(markers)[1:2], pt.size = 0.05)
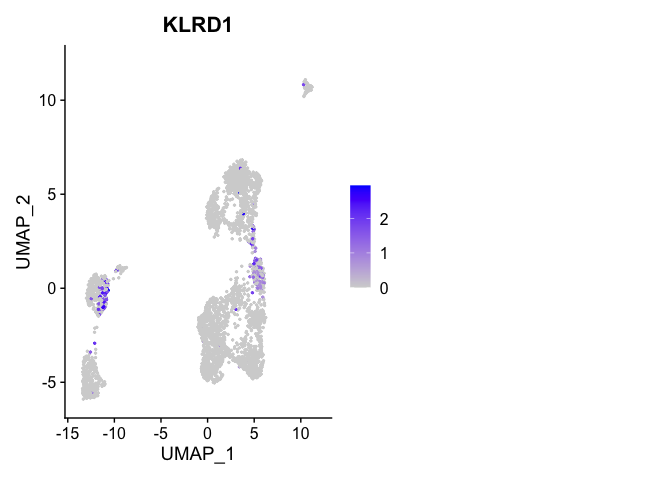
Or a feature plot
FeaturePlot(
experiment.aggregate,
"KLRD1",
cols = c("lightgrey", "blue"),
ncol = 2
)
FindAllMarkers can be used to automate the process across all genes.
markers_all <- FindAllMarkers(
object = experiment.merged,
only.pos = TRUE,
min.pct = 0.25,
thresh.use = 0.25
)
dim(markers_all)
head(markers_all)
table(table(markers_all$gene))
markers_all_single <- markers_all[markers_all$gene %in% names(table(markers_all$gene))[table(markers_all$gene) == 1],]
dim(markers_all_single)
table(table(markers_all_single$gene))
table(markers_all_single$cluster)
head(markers_all_single)
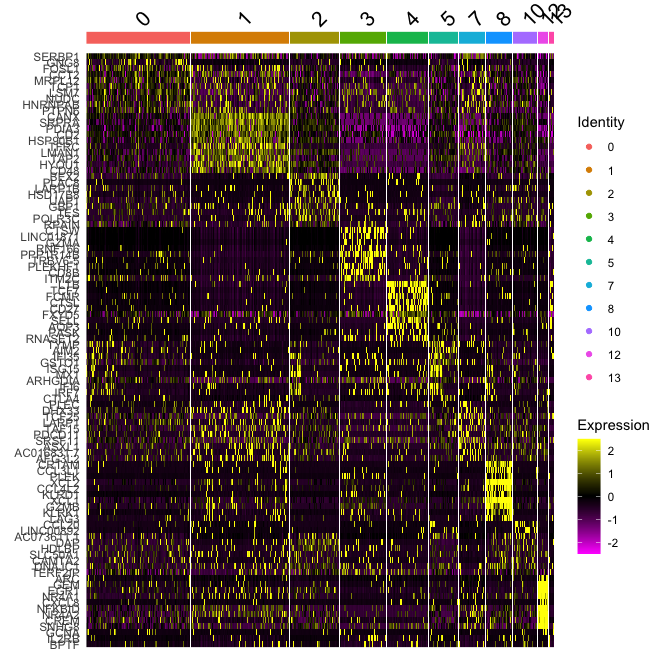
Plot a heatmap of genes by cluster for the top 10 marker genes per cluster
top10 <- markers_all_single %>% group_by(cluster) %>% top_n(10, avg_log2FC)
DoHeatmap(
object = experiment.merged,
features = top10$gene
)
# Get expression of genes for cells in and out of each cluster
getGeneClusterMeans <- function(gene, cluster){
x <- GetAssayData(experiment.merged)[gene,]
m <- tapply(x, ifelse(Idents(experiment.merged) == cluster, 1, 0), mean)
mean.in.cluster <- m[2]
mean.out.of.cluster <- m[1]
return(list(mean.in.cluster = mean.in.cluster, mean.out.of.cluster = mean.out.of.cluster))
}
## for sake of time only using first six (head)
means <- mapply(getGeneClusterMeans, head(markers_all[,"gene"]), head(markers_all[,"cluster"]))
means <- matrix(unlist(means), ncol = 2, byrow = T)
colnames(means) <- c("mean.in.cluster", "mean.out.of.cluster")
rownames(means) <- head(markers_all[,"gene"])
markers_all2 <- cbind(head(markers_all), means)
head(markers_all2)
Finishing up clusters.
At this point in time you should use the tree, markers, domain knowledge, and goals to finalize your clusters. This may mean adjusting PCA to use, mergers clusters together, choosing a new resolutions, etc. When finished you can further name it cluster by something more informative. Ex.
experiment.clusters <- experiment.aggregate
experiment.clusters <- RenameIdents(
object = experiment.clusters,
'0' = 'cell_type_A',
'1' = 'cell_type_B',
'2' = 'cell_type_C'
)
# and so on
DimPlot(object = experiment.clusters, pt.size=0.5, label = T, reduction = "tsne")
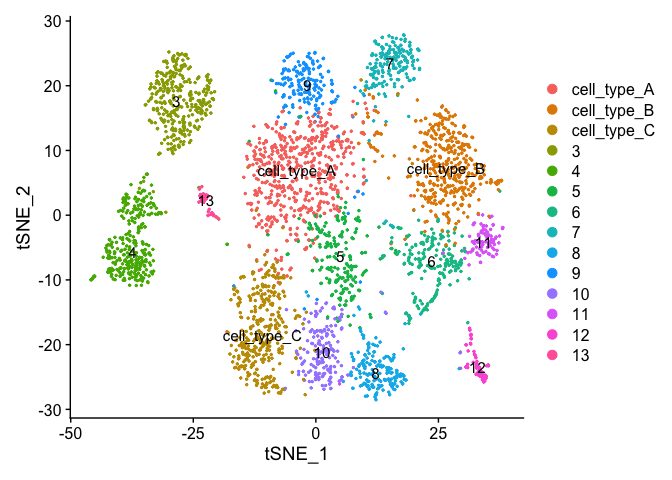
Right now our results ONLY exist in the Ident data object, lets save it to our metadata table so we don’t accidentally loose it.
experiment.merged$finalcluster <- Idents(experiment.merged)
head(experiment.merged[[]])
table(experiment.merged$finalcluster, experiment.merged$orig.ident)
Subsetting samples and plotting
If you want to look at the representation of just one sample, or sets of samples
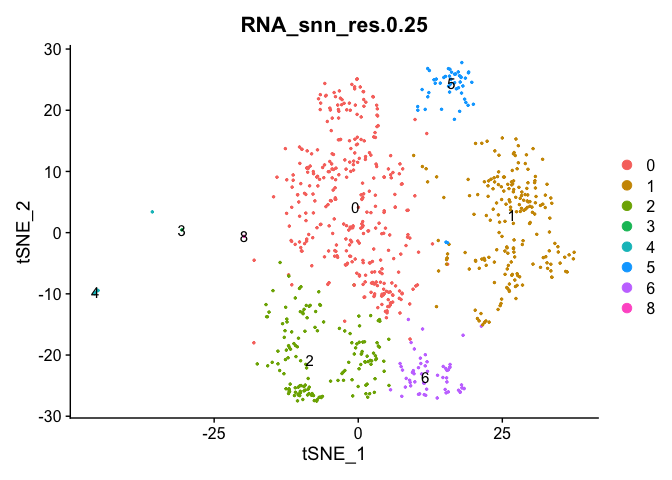
experiment.sample1 <- subset(experiment.merged, orig.ident == "conv_COVID")
DimPlot(object = experiment.sample1, group.by = "RNA_snn_res.0.25", pt.size=0.5, label = TRUE, reduction = "tsne")
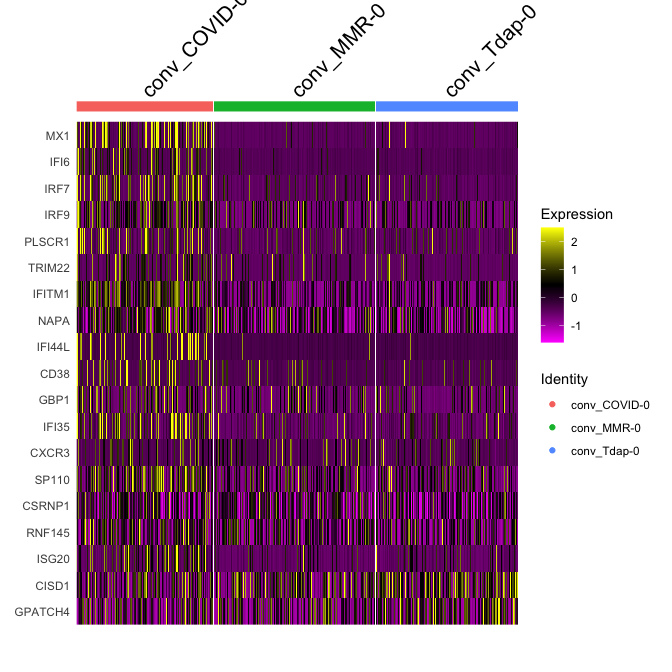
Adding in a new metadata column representing samples within clusters. So differential expression of PBMC2 vs PBMC3 within cluster 7
experiment.merged$samplecluster = paste(experiment.merged$orig.ident,experiment.merged$finalcluster,sep = '-')
# set the identity to the new variable
Idents(experiment.merged) <- "samplecluster"
markers.comp <- FindMarkers(experiment.merged, ident.1 = c("conv_COVID-0","conv_MMR-0"), ident.2= "conv_Tdap-0")
head(markers.comp)
experiment.subset <- subset(experiment.merged, samplecluster %in% c( "conv_COVID-0", "conv_MMR-0", "conv_Tdap-0" ))
DoHeatmap(experiment.subset, features = head(rownames(markers.comp),20))
Idents(experiment.merged) <- "finalcluster"
And last lets save all the Seurat objects in our session.
save(list=grep('experiment', ls(), value = TRUE), file="clusters_seurat_object.RData")
Get the next Rmd file
download.file("https://raw.githubusercontent.com/ucdavis-bioinformatics-training/2022-March-Single-Cell-RNA-Seq-Analysis/main/data_analysis/scRNA_Workshop-PART6.Rmd", "scRNA_Workshop-PART6.Rmd")
Session Information
sessionInfo()