
Introduction to Single Cell RNA-Seq Part 2: QA and filtering
Set up workspace
First, we need to load the required libraries.
library(Seurat)
library(ggplot2)
library(tidyr)
library(kableExtra)
If you are continuing directly from part 1, the experiment.aggregate object is likely already in your workspace. In case you cleared your workspace at the end of the previous section, or are working on this project at a later date after re-starting R, you can use the readRDS function to read your saved Seurat object from part 1.
experiment.aggregate <- readRDS("scRNA_workshop-01.rds")
experiment.aggregate
## An object of class Seurat
## 36601 features across 9456 samples within 1 assay
## Active assay: RNA (36601 features, 0 variable features)
The seed is used to initialize pseudo-random functions. Some of the functions we will be using have pseudo-random elements. Setting a common seed ensures that all of us will get the same results, and that the results will remain stable when re-run.
set.seed(12345)
Mitochondrial gene expression
Filtering on the expression of genes from the mitochondrial genome is not appropriate in all cell types. However, in many tissues, low-quality / dying cells may exhibit extensive mitochondrial contamination. Even when not filtering on mitochondrial expression, the data can be interesting or informative.
The PercentageFeatureSet function calculates the proportion of counts originating from a set of features. Genes in the human mitochondrial genome begin with ‘MT’, while those in the mouse mitochondrial genome begin with ‘mt’. These naming conventions make calculating percent mitochondrial very straightforward.
experiment.aggregate$percent_MT <- PercentageFeatureSet(experiment.aggregate, pattern = "^MT-")
summary(experiment.aggregate$percent_MT)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0000 0.2802 0.5604 0.8282 1.0841 14.2037
In this workshop, we are using the filtered feature barcode matrix. While this lowers the likelihood of encountering barcodes that are not cell-associated within our expression matrix, it is still good practice to perform quality assurance on the experiment.
Display metadata by quantile
Using a few nested functions, we can produce prettier, more detailed, versions of the simple exploratory summary statistics we generated for the available metadata in the last section. In the code below, 10% quantile tables are produced for each metadata value, separated by sample identity.
kable(do.call("cbind", tapply(experiment.aggregate$nFeature_RNA,
Idents(experiment.aggregate),
quantile, probs = seq(0,1,0.1))),
caption = "10% Quantiles of Genes/Cell by Sample") %>% kable_styling()
| A001-C-007 | A001-C-104 | B001-A-301 | |
|---|---|---|---|
| 0% | 404.0 | 397.0 | 416.0 |
| 10% | 494.0 | 505.0 | 577.0 |
| 20% | 573.0 | 581.0 | 733.0 |
| 30% | 676.1 | 677.0 | 907.0 |
| 40% | 782.0 | 791.0 | 1105.0 |
| 50% | 927.0 | 959.0 | 1331.0 |
| 60% | 1127.4 | 1126.8 | 1564.0 |
| 70% | 1379.3 | 1358.0 | 1810.3 |
| 80% | 1795.4 | 1718.4 | 2119.0 |
| 90% | 2589.6 | 2344.1 | 2567.0 |
| 100% | 12063.0 | 12064.0 | 8812.0 |
kable(do.call("cbind", tapply(experiment.aggregate$nCount_RNA,
Idents(experiment.aggregate),
quantile, probs = seq(0,1,0.1))),
caption = "10% Quantiles of UMI/Cell by Sample") %>% kable_styling()
| A001-C-007 | A001-C-104 | B001-A-301 | |
|---|---|---|---|
| 0% | 500.0 | 500.0 | 500.0 |
| 10% | 575.0 | 588.0 | 698.0 |
| 20% | 683.8 | 693.0 | 909.0 |
| 30% | 824.2 | 821.0 | 1179.9 |
| 40% | 978.8 | 995.4 | 1514.6 |
| 50% | 1201.0 | 1231.0 | 1913.0 |
| 60% | 1493.0 | 1514.0 | 2399.0 |
| 70% | 1919.8 | 1905.6 | 2960.1 |
| 80% | 2688.4 | 2603.8 | 3704.0 |
| 90% | 4409.0 | 4051.5 | 5087.1 |
| 100% | 150805.0 | 149096.0 | 89743.0 |
kable(round(do.call("cbind", tapply(experiment.aggregate$percent_MT,
Idents(experiment.aggregate),
quantile, probs = seq(0,1,0.1))),
digits = 3),
caption = "10% Quantiles of Percent Mitochondrial by Sample") %>% kable_styling()
| A001-C-007 | A001-C-104 | B001-A-301 | |
|---|---|---|---|
| 0% | 0.000 | 0.000 | 0.000 |
| 10% | 0.266 | 0.350 | 0.118 |
| 20% | 0.369 | 0.510 | 0.164 |
| 30% | 0.474 | 0.677 | 0.211 |
| 40% | 0.582 | 0.851 | 0.263 |
| 50% | 0.705 | 1.043 | 0.323 |
| 60% | 0.865 | 1.281 | 0.404 |
| 70% | 1.062 | 1.539 | 0.512 |
| 80% | 1.334 | 1.911 | 0.681 |
| 90% | 1.722 | 2.730 | 0.947 |
| 100% | 14.204 | 13.172 | 3.481 |
Visualize distribution of metadata values
Seurat has a number of convenient built-in functions for visualizing metadata. These functions produce ggplot objects, which can easily be modified using ggplot2. Of course, all of these visualizations can be reproduced with custom code as well, and we will include some examples of both modifying Seurat plots and generating plots from scratch as the analysis continues.
Violin plots
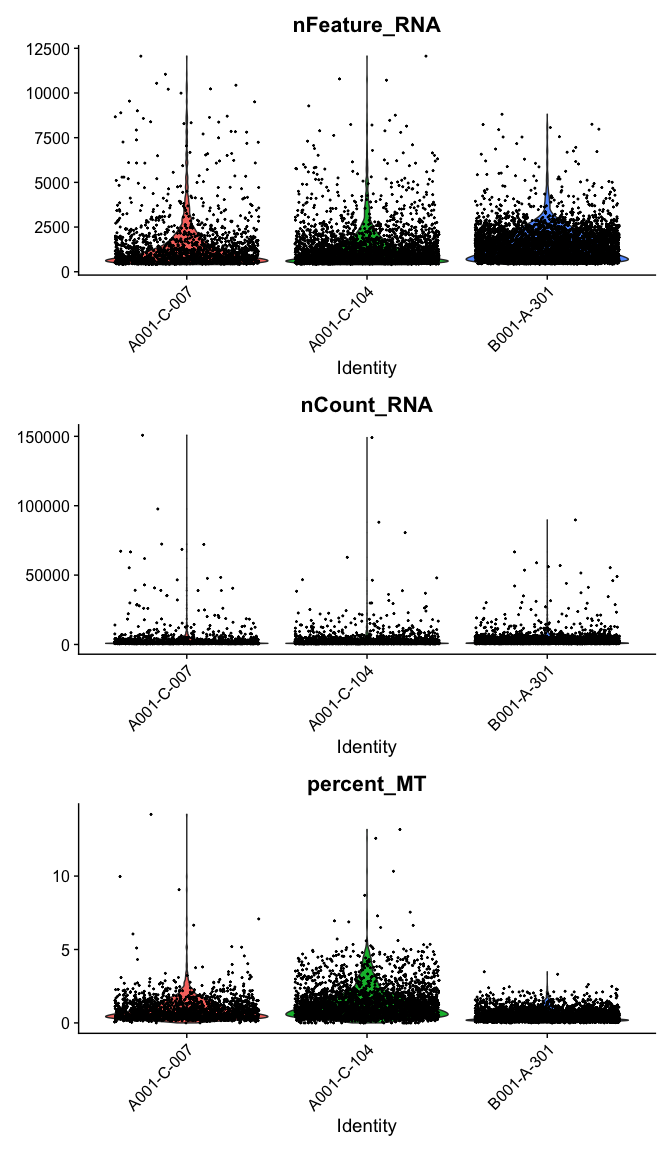
The VlnPlot function produces a composite plot with one panel for each element of the “features” vector. The data are grouped by the provided identity; by default, this is the active identity of the object, which can be accessed using the Idents() function, or in the “active.ident” slot.
VlnPlot(experiment.aggregate,
features = c("nFeature_RNA", "nCount_RNA","percent_MT"),
ncol = 1,
pt.size = 0.3)
Modifying Seurat plots
Modifying the ggplot objects produced by a Seurat plotting function works best on individual panels. Therefore, to recreate the function above with modifications, we can use lapply to create a list of plots. In some cases it may be more appropriate to create the plots individually so that different modifications can be applied to each plot.
lapply(c("nFeature_RNA", "nCount_RNA","percent_MT"), function(feature){
VlnPlot(experiment.aggregate,
features = feature,
pt.size = 0.01) +
scale_fill_viridis_d(option = "mako") # default colors are not colorblind-friendly
})
## [[1]]
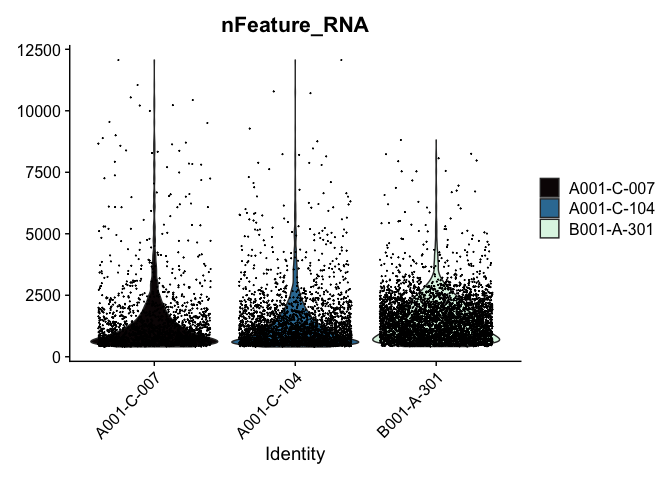
##
## [[2]]
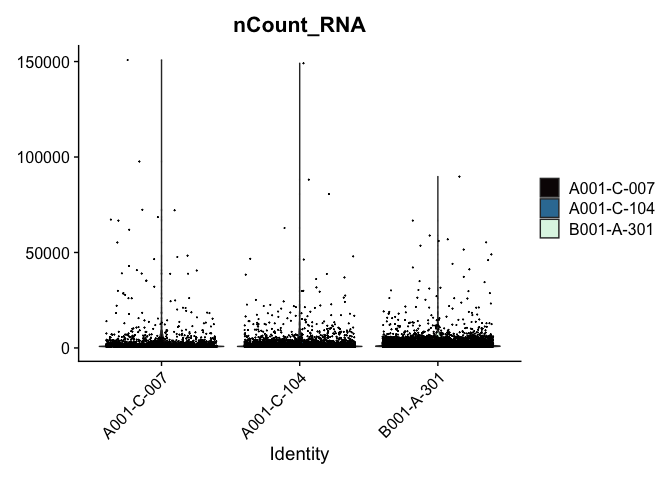
##
## [[3]]
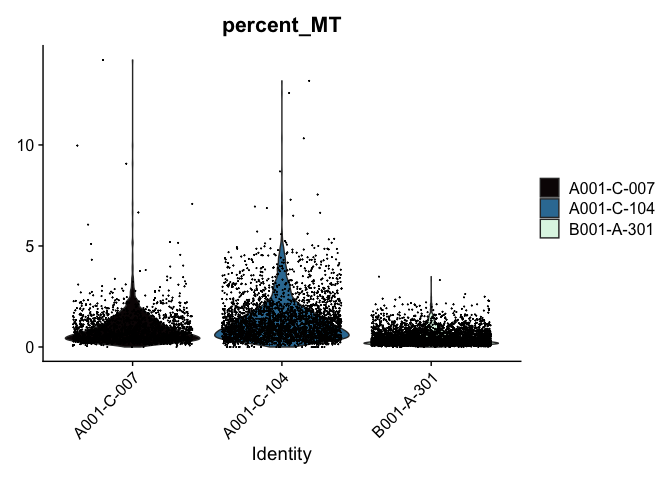
VlnPlot(experiment.aggregate, features = "nCount_RNA", pt.size = 0.01) +
scale_y_continuous(trans = "log10") +
scale_fill_viridis_d(option = "mako") +
ggtitle("log10(nCount_RNA)")
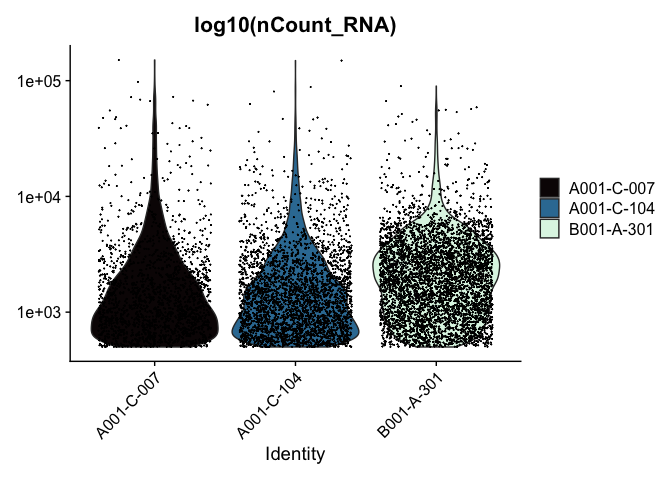
These can later be stitched together with another library, like patchwork, or cowplot.
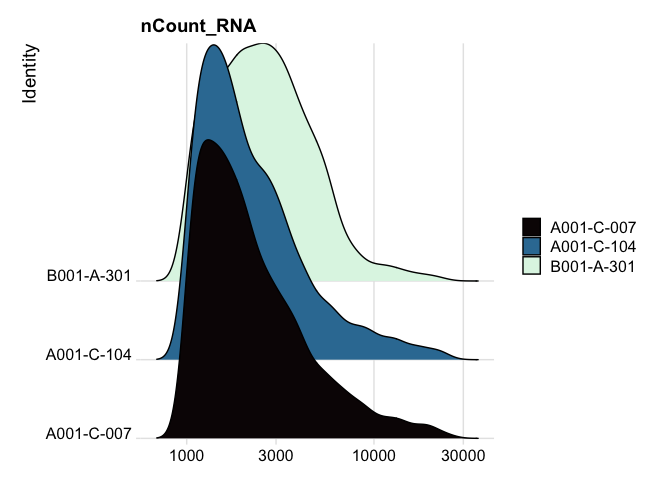
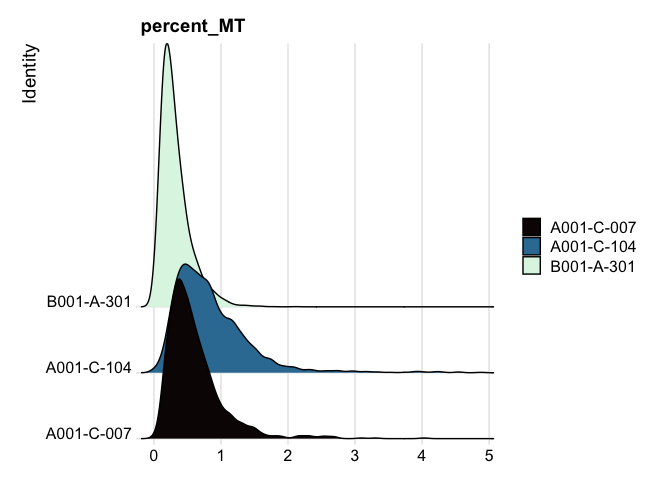
Ridge plots
Ridge plots are very similar in appearance to violin plots turned on their sides. In some cases it may be more appropriate to create the plots individually so that appropriate transformations can be applied to each plot.
RidgePlot(experiment.aggregate, features="nFeature_RNA") +
scale_fill_viridis_d(option = "mako")
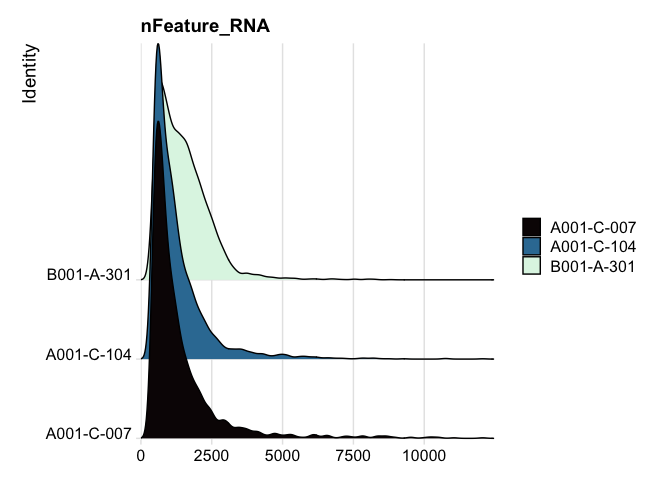
RidgePlot(experiment.aggregate, features="nCount_RNA") +
scale_x_continuous(trans = "log10") + # "un-squish" the distribution
scale_fill_viridis_d(option = "mako")
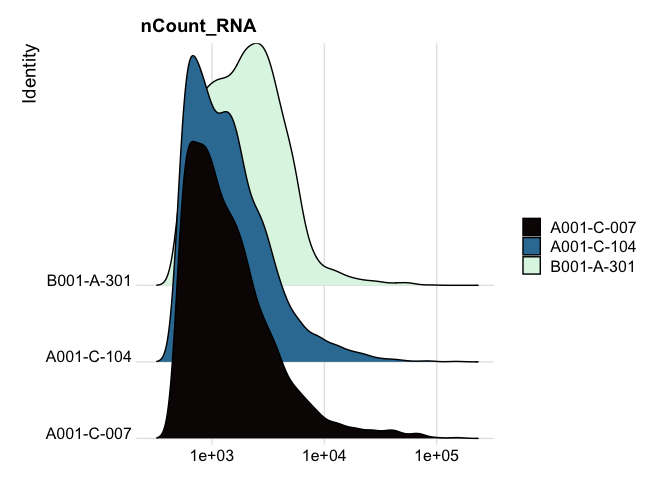
RidgePlot(experiment.aggregate, features="percent_MT") +
scale_fill_viridis_d(option = "mako") +
coord_cartesian(xlim = c(0, 10)) # zoom in on the lower end of the distribution
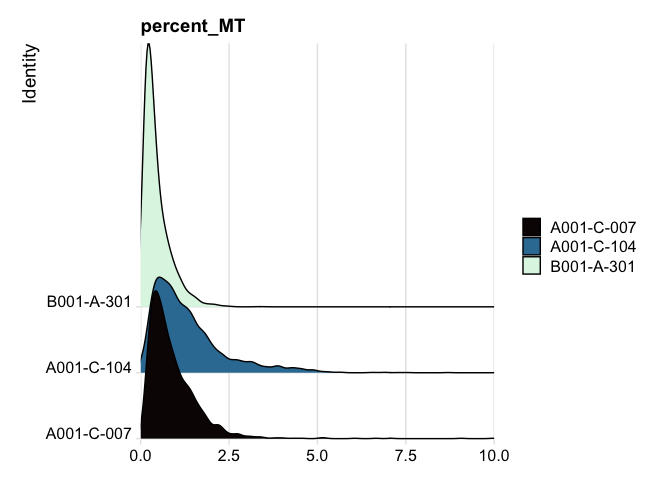
Custom plots
The Seurat built-in functions are useful and easy to interact with, but sometimes you may wish to visualize something for which a plotting function does not already exist. For example, we might want to see how many cells are expressing each gene over some UMI threshold.
The code below produces a ranked plot similar to the barcode inflection plots from the last section. On the x-axis are the genes arranged from most ubiquitously expressed to rarest. In a single cell dataset, many genes are expessed in a relatively small number of cells, or not at all. The y-axis displays the number of cells in which each gene is expressed.
Note: This function is SLOW. You may want to skip this code block or run it while you take a break for a few minutes.
# retrieve count data
counts <- GetAssayData(experiment.aggregate)
# order genes from most to least ubiquitous
ranked.genes <- names(sort(Matrix::rowSums(counts >= 3), decreasing = TRUE))
# drop genes not expressed in any cell
ranked.genes <- ranked.genes[ranked.genes %in% names(which(Matrix::rowSums(counts >= 3) >= 1))]
# get number of cells in which gene is expressed for each sample
cell.counts <- sapply(ranked.genes, function(gene){
tapply(counts[gene,], experiment.aggregate$orig.ident, function(x){
sum(x >= 3)
})
})
cell.counts <- as.data.frame(t(cell.counts))
cell.counts$gene <- rownames(cell.counts)
cell.counts$rank <- seq(1:dim(cell.counts)[1])
cell.counts %>%
pivot_longer(cols = 1:3, names_to = "sample", values_to = "count") %>%
ggplot(mapping = aes(x = rank, y = count, color = sample)) +
scale_x_continuous(trans = "log10") +
scale_y_continuous(trans = "log10") +
geom_point(size=0.2) +
scale_color_viridis_d(option = "mako") +
theme_classic() +
theme(legend.title = element_blank())
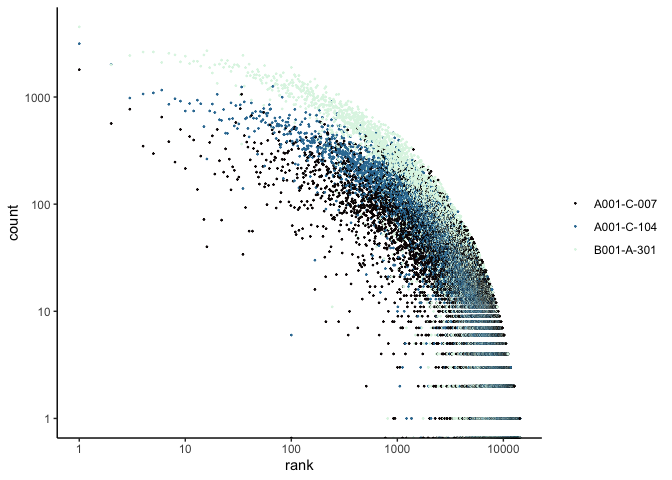
Scatter plots
Scatter plots allow us to visualize the relationships between the metadata variables.
# mitochondrial vs UMI
FeatureScatter(experiment.aggregate,
feature1 = "nCount_RNA",
feature2 = "percent_MT",
shuffle = TRUE) +
scale_color_viridis_d(option = "mako")
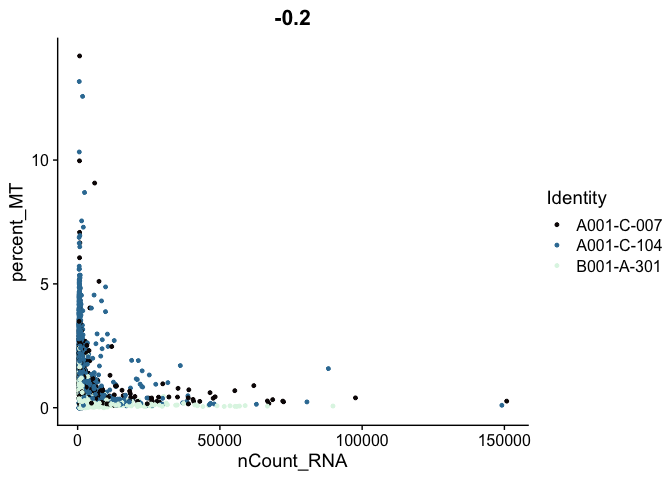
# mitochondrial vs genes
FeatureScatter(experiment.aggregate,
feature1 = "nFeature_RNA",
feature2 = "percent_MT",
shuffle = TRUE) +
scale_color_viridis_d(option = "mako")
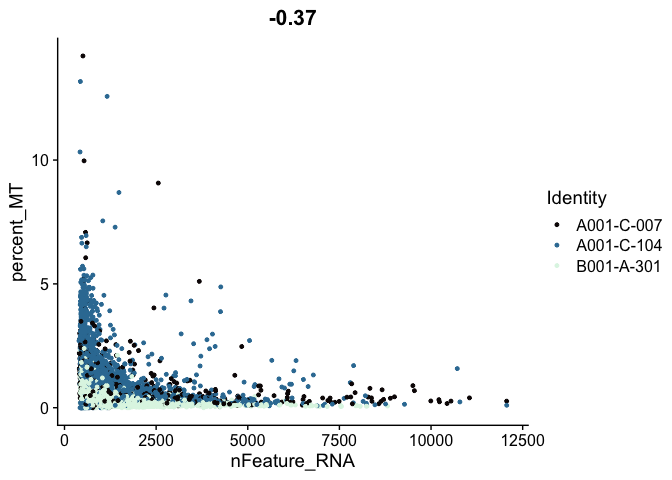
# genes vs UMI
FeatureScatter(experiment.aggregate,
feature1 = "nCount_RNA",
feature2 = "nFeature_RNA",
shuffle = TRUE) +
scale_color_viridis_d(option = "mako")
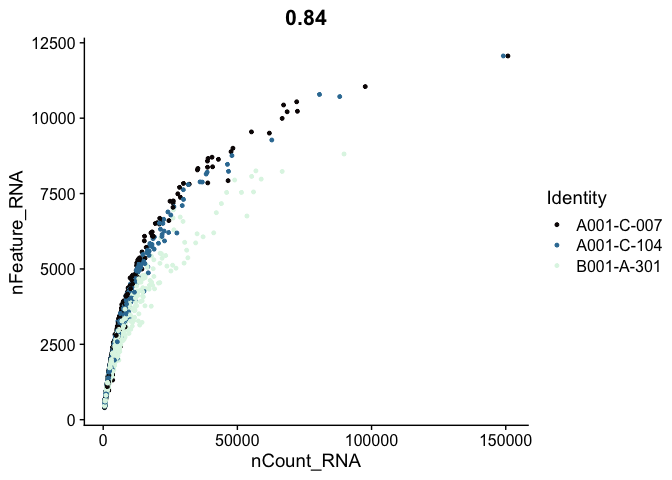
Cell filtering
The goal of cell filtering is to remove cells with anomolous expression profiles, typically low UMI cells, which may correspond to low-quality cells or background barcodes that made it through the Cell Ranger filtration algorithm. It may also be appropriate to remove outlier cells with extremely high UMI counts. In this case, the proposed cut-offs on the high end of the distributions are quite conservative, in part to reduce the size of the object and speed up analysis during the workshop.
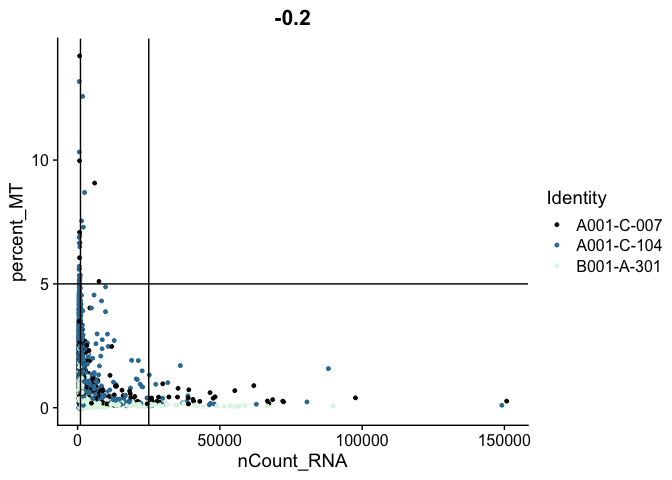
The plots below display proposed filtering cut-offs.
FeatureScatter(experiment.aggregate,
feature1 = "nCount_RNA",
feature2 = "percent_MT",
shuffle = TRUE) +
geom_vline(xintercept = c(1000, 25000)) +
geom_hline(yintercept = 5) +
scale_color_viridis_d(option = "mako")
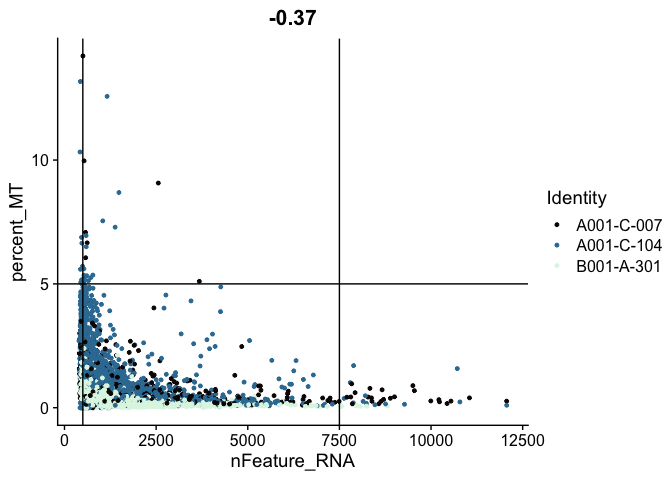
FeatureScatter(experiment.aggregate,
feature1 = "nFeature_RNA",
feature2 = "percent_MT",
shuffle = TRUE) +
geom_vline(xintercept = c(500, 7500)) +
geom_hline(yintercept = 5) +
scale_color_viridis_d(option = "mako")
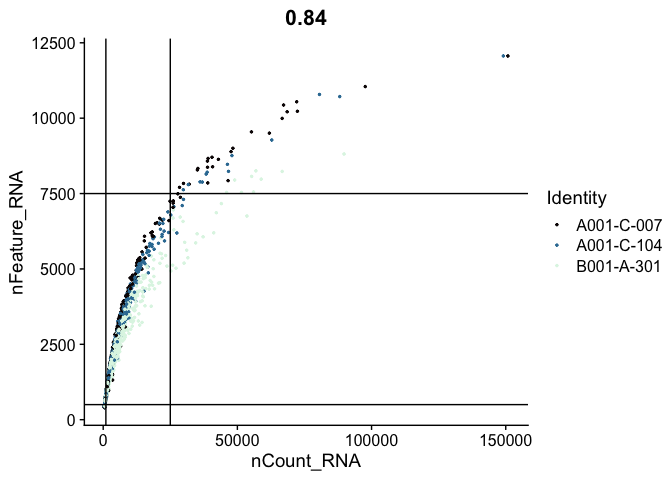
FeatureScatter(experiment.aggregate,
feature1 = "nCount_RNA",
feature2 = "nFeature_RNA",
pt.size = 0.5,
shuffle = TRUE) +
geom_vline(xintercept = c(1000, 25000)) +
geom_hline(yintercept = c(500, 7500)) +
scale_color_viridis_d(option = "mako")
These filters can be put in place with the subset function.
table(experiment.aggregate$orig.ident)
##
## A001-C-007 A001-C-104 B001-A-301
## 1798 3144 4514
# mitochondrial filter
experiment.filter <- subset(experiment.aggregate, percent_MT <= 5)
# UMI filter
experiment.filter <- subset(experiment.filter, nCount_RNA >= 1000 & nCount_RNA <= 25000)
# gene filter
experiment.filter <- subset(experiment.filter, nFeature_RNA >= 500 & nFeature_RNA <= 7500)
# filtering results
experiment.filter
## An object of class Seurat
## 36601 features across 6313 samples within 1 assay
## Active assay: RNA (36601 features, 0 variable features)
table(experiment.filter$orig.ident)
##
## A001-C-007 A001-C-104 B001-A-301
## 1023 1859 3431
# ridge plots
RidgePlot(experiment.filter, features="nFeature_RNA") +
scale_fill_viridis_d(option = "mako")
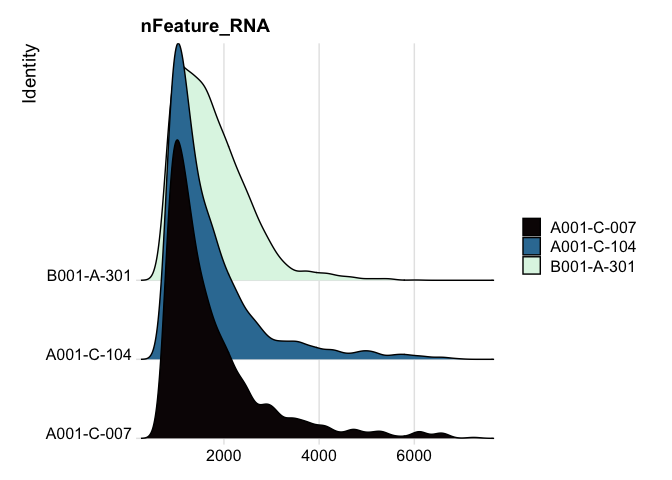
RidgePlot(experiment.filter, features="nCount_RNA") +
scale_x_continuous(trans = "log10") +
scale_fill_viridis_d(option = "mako")
RidgePlot(experiment.filter, features="percent_MT") +
scale_fill_viridis_d(option = "mako")
# use filtered results from now on
experiment.aggregate <- experiment.filter
Play with the filtering parameters, and see how the results change. Is there a set of parameters you feel is more appropriate? Why?
Feature filtering
When creating the base Seurat object, we had the opportunity filter out some genes using the “min.cells” argument. At the time, we set that to 0. Since we didn’t filter our features then, we can apply a filter at this point. If we had filtered when the object was created, this would be an opportunity to be more aggressive. The custom code below provides a function that filters genes requiring a min.umi in at least min.cells, or takes a user-provided list of genes.
# define function
FilterGenes <- function(object, min.umi = NA, min.cells = NA, genes = NULL) {
genes.use = NA
if (!is.null(genes)) {
genes.use = intersect(rownames(object), genes)
} else if (min.cells & min.umi) {
num.cells = Matrix::rowSums(GetAssayData(object) >= min.umi)
genes.use = names(num.cells[which(num.cells >= min.cells)])
}
object = object[genes.use,]
object = LogSeuratCommand(object = object)
return(object)
}
# apply filter
experiment.filter <- FilterGenes(object = experiment.aggregate, min.umi = 2, min.cells = 10)
# filtering results
experiment.filter
## An object of class Seurat
## 11292 features across 6313 samples within 1 assay
## Active assay: RNA (11292 features, 0 variable features)
experiment.aggregate <- experiment.filter
Prepare for the next section
Save object
saveRDS(experiment.aggregate, file="scRNA_workshop-02.rds")
Download Rmd
download.file("https://raw.githubusercontent.com/ucdavis-bioinformatics-training/2023-December-Single-Cell-RNA-Seq-Analysis/main/data_analysis/03-normalize_scale.Rmd", "03-normalize_scale.Rmd")
Session Information
sessionInfo()
## R version 4.2.2 (2022-10-31)
## Platform: x86_64-apple-darwin17.0 (64-bit)
## Running under: macOS Big Sur ... 10.16
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] kableExtra_1.3.4 tidyr_1.2.1 ggplot2_3.4.0 SeuratObject_4.1.3
## [5] Seurat_4.3.0
##
## loaded via a namespace (and not attached):
## [1] ggbeeswarm_0.6.0 Rtsne_0.16 colorspace_2.0-3
## [4] deldir_1.0-6 ellipsis_0.3.2 ggridges_0.5.4
## [7] rstudioapi_0.14 spatstat.data_3.0-0 farver_2.1.1
## [10] leiden_0.4.3 listenv_0.8.0 ggrepel_0.9.2
## [13] fansi_1.0.3 xml2_1.3.3 codetools_0.2-18
## [16] splines_4.2.2 cachem_1.0.6 knitr_1.41
## [19] polyclip_1.10-4 jsonlite_1.8.4 ica_1.0-3
## [22] cluster_2.1.4 png_0.1-8 uwot_0.1.14
## [25] shiny_1.7.3 sctransform_0.3.5 spatstat.sparse_3.0-0
## [28] compiler_4.2.2 httr_1.4.4 assertthat_0.2.1
## [31] Matrix_1.5-3 fastmap_1.1.0 lazyeval_0.2.2
## [34] cli_3.4.1 later_1.3.0 htmltools_0.5.3
## [37] tools_4.2.2 igraph_1.3.5 gtable_0.3.1
## [40] glue_1.6.2 RANN_2.6.1 reshape2_1.4.4
## [43] dplyr_1.0.10 Rcpp_1.0.9 scattermore_0.8
## [46] jquerylib_0.1.4 vctrs_0.5.1 svglite_2.1.0
## [49] nlme_3.1-160 spatstat.explore_3.0-5 progressr_0.11.0
## [52] lmtest_0.9-40 spatstat.random_3.0-1 xfun_0.35
## [55] stringr_1.4.1 globals_0.16.2 rvest_1.0.3
## [58] mime_0.12 miniUI_0.1.1.1 lifecycle_1.0.3
## [61] irlba_2.3.5.1 goftest_1.2-3 future_1.29.0
## [64] MASS_7.3-58.1 zoo_1.8-11 scales_1.2.1
## [67] promises_1.2.0.1 spatstat.utils_3.0-1 parallel_4.2.2
## [70] RColorBrewer_1.1-3 yaml_2.3.6 reticulate_1.28
## [73] pbapply_1.6-0 gridExtra_2.3 ggrastr_1.0.1
## [76] sass_0.4.4 stringi_1.7.8 highr_0.9
## [79] systemfonts_1.0.4 rlang_1.0.6 pkgconfig_2.0.3
## [82] matrixStats_0.63.0 evaluate_0.18 lattice_0.20-45
## [85] tensor_1.5 ROCR_1.0-11 purrr_0.3.5
## [88] labeling_0.4.2 patchwork_1.1.2 htmlwidgets_1.5.4
## [91] cowplot_1.1.1 tidyselect_1.2.0 parallelly_1.32.1
## [94] RcppAnnoy_0.0.20 plyr_1.8.8 magrittr_2.0.3
## [97] R6_2.5.1 generics_0.1.3 DBI_1.1.3
## [100] withr_2.5.0 pillar_1.8.1 fitdistrplus_1.1-8
## [103] survival_3.4-0 abind_1.4-5 sp_1.5-1
## [106] tibble_3.1.8 future.apply_1.10.0 crayon_1.5.2
## [109] KernSmooth_2.23-20 utf8_1.2.2 spatstat.geom_3.0-3
## [112] plotly_4.10.1 rmarkdown_2.18 grid_4.2.2
## [115] data.table_1.14.6 webshot_0.5.4 digest_0.6.30
## [118] xtable_1.8-4 httpuv_1.6.6 munsell_0.5.0
## [121] beeswarm_0.4.0 viridisLite_0.4.1 vipor_0.4.5
## [124] bslib_0.4.1