
Introduction to Single Cell RNA-Seq Part 6: Clustering and cell type assignment
Clustering and cell type assignment are critical steps in many single cell (or single nucleus) experiments. The power of single cell experiments is to capture the heterogeneity within samples as well as between them. Clustering permits the user to organize cells into clusters that correspond to biologically and experimentally relevant populations.
Set up workspace
library(Seurat)
library(kableExtra)
library(tidyr)
library(dplyr)
library(ggplot2)
library(HGNChelper)
library(ComplexHeatmap)
set.seed(12345)
experiment.aggregate <- readRDS("scRNA_workshop-04.rds")
experiment.aggregate
Construct network
Seurat implements an graph-based clustering approach. Distances between the cells are calculated based on previously identified PCs.
The default method for identifying k-nearest neighbors is annoy, an approximate nearest-neighbor approach that is widely used for high-dimensional analysis in many fields, including single-cell analysis. Extensive community benchmarking has shown that annoy substantially improves the speed and memory requirements of neighbor discovery, with negligible impact to downstream results.
experiment.aggregate <- FindNeighbors(experiment.aggregate, reduction = "pca", dims = 1:50)
Find clusters
The FindClusters function implements the neighbor based clustering procedure, and contains a resolution parameter that sets the granularity of the downstream clustering, with increased values leading to a greater number of clusters. This code produces a series of resolutions for us to investigate and choose from.
The clustering resolution parameter is unit-less and somewhat arbitrary. The resolutions used here were selected to produce a useable number of clusters in the example experiment.
experiment.aggregate <- FindClusters(experiment.aggregate,
resolution = seq(0.1, 0.4, 0.1))
Seurat adds the clustering information to the metadata table. Each FindClusters call generates a new column named with the assay, followed by “_snn_res.”, and the resolution.
cluster.resolutions <- grep("res", colnames(experiment.aggregate@meta.data), value = TRUE)
head(experiment.aggregate@meta.data[,cluster.resolutions]) %>%
kable(caption = 'Cluster identities are added to the meta.data slot.') %>%
kable_styling("striped")
| RNA_snn_res.0.1 | RNA_snn_res.0.2 | RNA_snn_res.0.3 | RNA_snn_res.0.4 | |
|---|---|---|---|---|
| AAACCCAAGTTATGGA_A001-C-007 | 1 | 1 | 5 | 5 |
| AAACGCTTCTCTGCTG_A001-C-007 | 7 | 8 | 10 | 9 |
| AAAGAACGTGCTTATG_A001-C-007 | 1 | 1 | 5 | 5 |
| AAAGAACGTTTCGCTC_A001-C-007 | 3 | 3 | 3 | 4 |
| AAAGGATTCATTACCT_A001-C-007 | 3 | 3 | 3 | 4 |
| AAAGTGACACGCTTAA_A001-C-007 | 1 | 1 | 5 | 5 |
Explore clustering resolutions
The number of clusters produced increases with the clustering resolution.
sapply(cluster.resolutions, function(res){
length(levels(experiment.aggregate@meta.data[,res]))
})
Visualize clustering
Dimensionality reduction plots can be used to visualize the clustering results. On these plots, we can see how each clustering resolution aligns with patterns in the data revealed by dimensionality reductions.
UMAP
# UMAP colored by cluster
lapply(cluster.resolutions, function(res){
DimPlot(experiment.aggregate,
group.by = res,
reduction = "umap",
shuffle = TRUE) +
scale_color_viridis_d(option = "turbo")
})
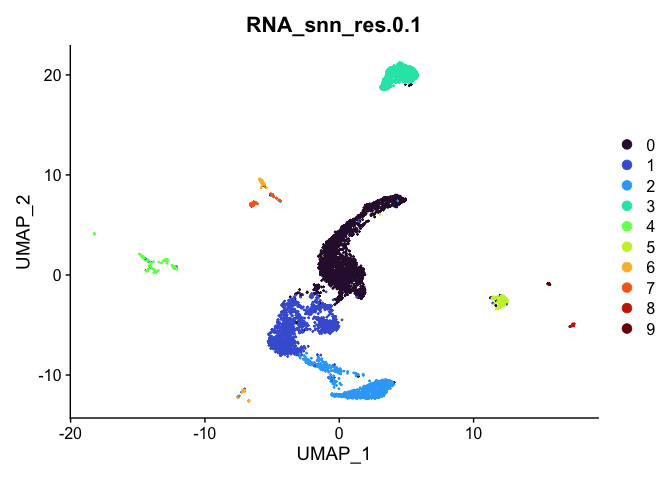
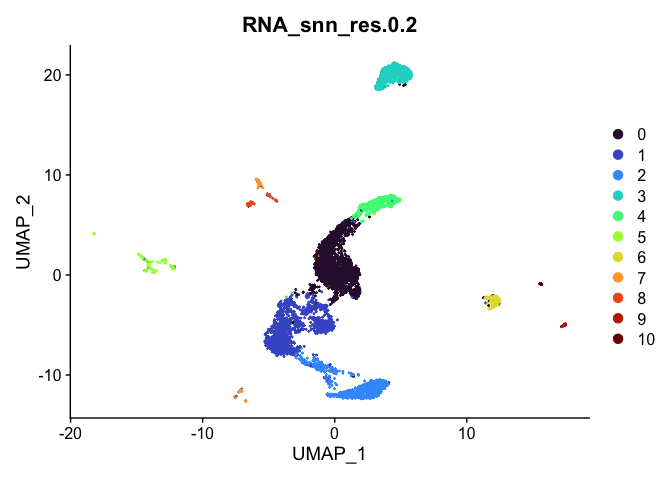
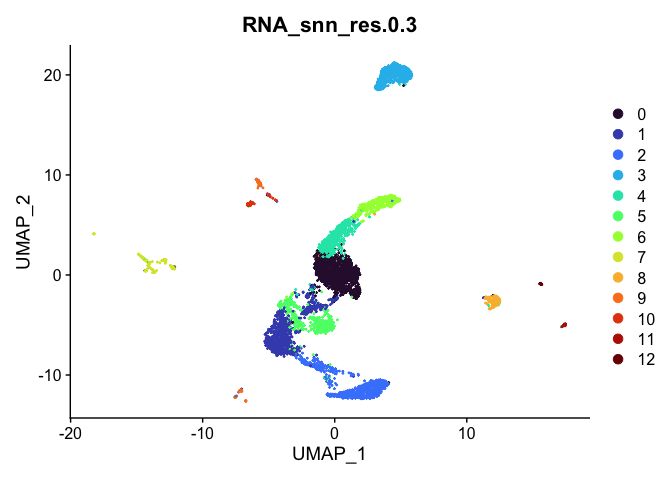
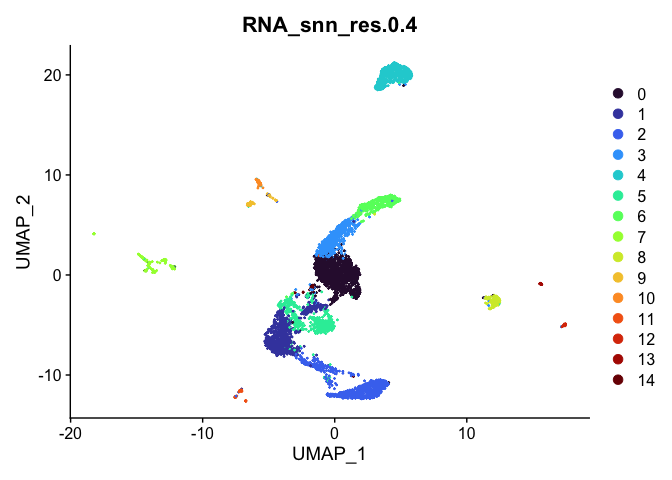
Investigate the relationship between cluster identity and sample identity
lapply(cluster.resolutions, function(res){
tmp = experiment.aggregate@meta.data[,c(res, "group")]
colnames(tmp) = c("cluster", "group")
ggplot(tmp, aes(x = cluster, fill = group)) +
geom_bar() +
scale_fill_viridis_d(option = "mako") +
theme_classic()
})
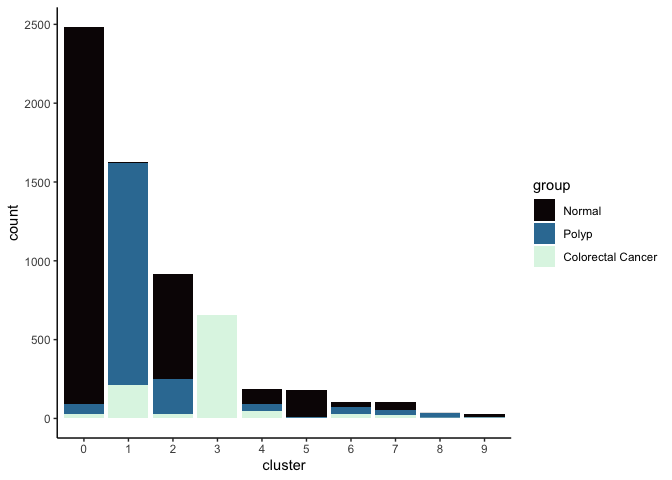
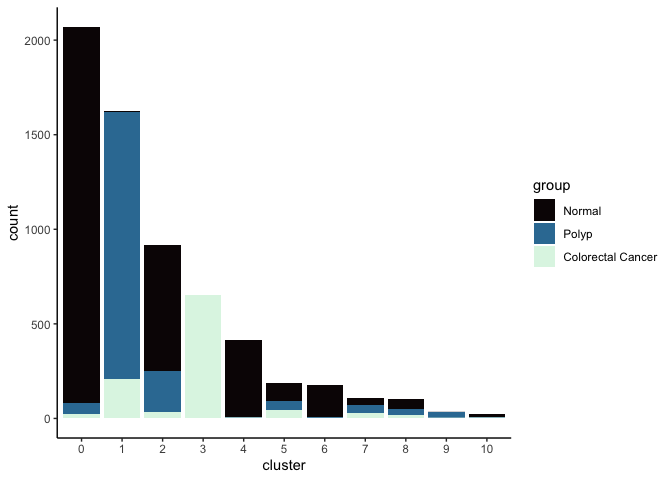
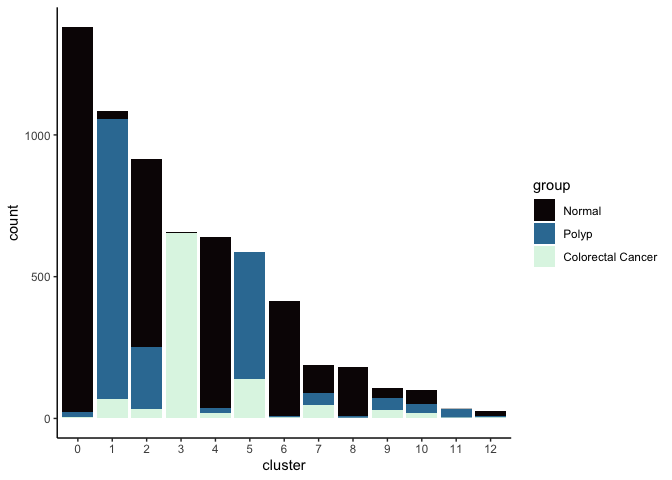
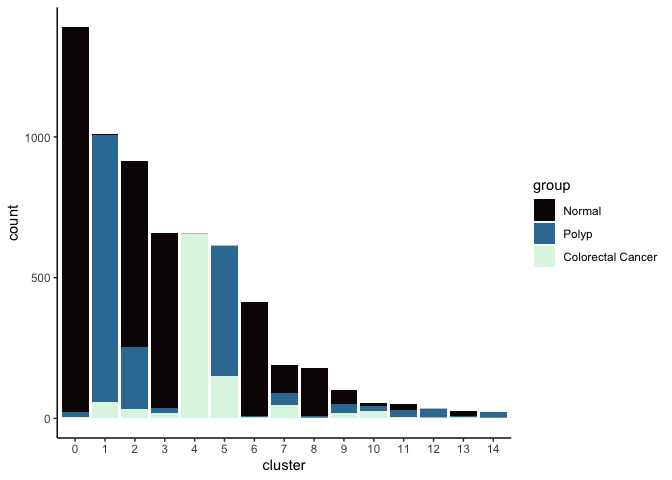
Investigate the relationship between cluster identity and metadata values
Here, example plots are displayed for the lowest resolution in order to save space. To see plots for each resolution, use lapply().
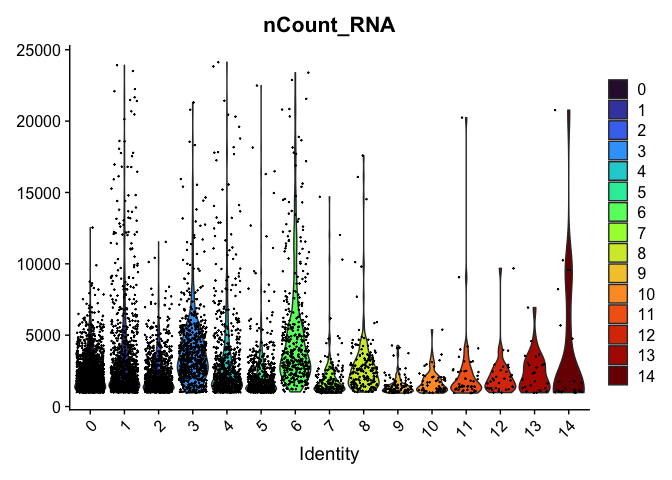
VlnPlot(experiment.aggregate,
group.by = "RNA_snn_res.0.4",
features = "nCount_RNA",
pt.size = 0.1) +
scale_fill_viridis_d(option = "turbo")
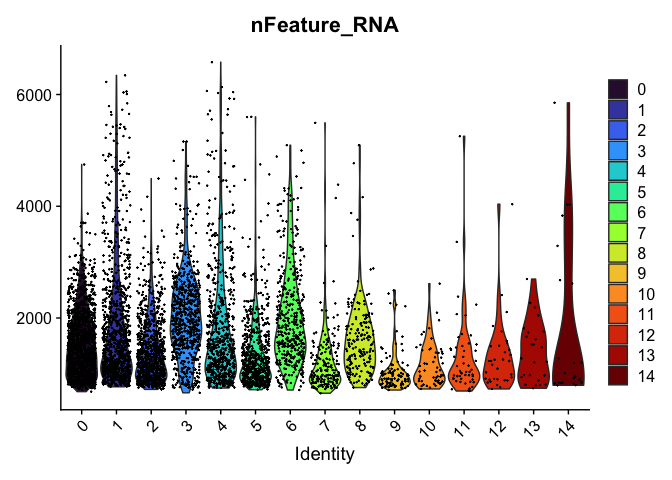
VlnPlot(experiment.aggregate,
group.by = "RNA_snn_res.0.4",
features = "nFeature_RNA",
pt.size = 0.1) +
scale_fill_viridis_d(option = "turbo")
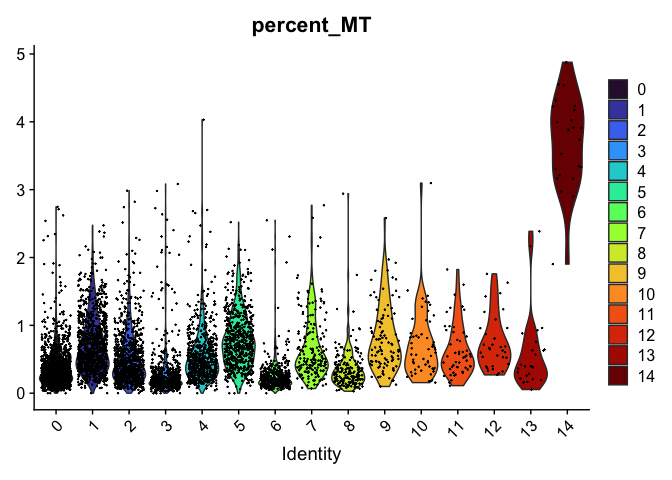
VlnPlot(experiment.aggregate,
group.by = "RNA_snn_res.0.4",
features = "percent_MT",
pt.size = 0.1) +
scale_fill_viridis_d(option = "turbo")
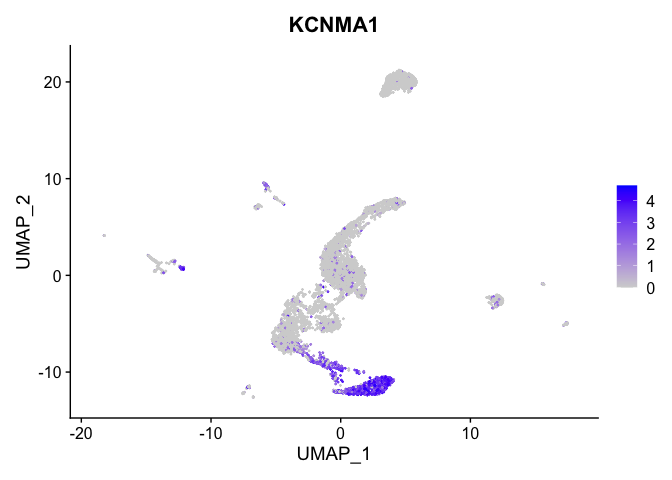
Visualize expression of genes of interest
FeaturePlot(experiment.aggregate,
reduction = "umap",
features = "KCNMA1")
VlnPlot(experiment.aggregate,
group.by = "RNA_snn_res.0.4",
features = "KCNMA1",
pt.size = 0.1) +
scale_fill_viridis_d(option = "turbo")
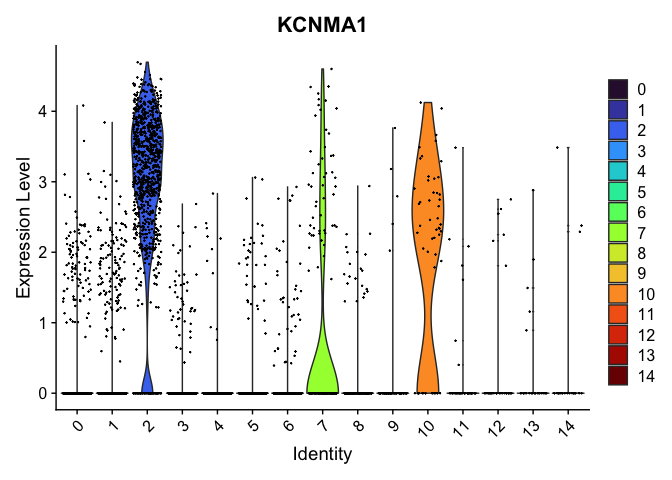
Select a resolution
For now, let’s use resolution 0.4. Over the remainder of this section, we will refine the clustering further.
Idents(experiment.aggregate) <- "RNA_snn_res.0.4"
Visualize cluster tree
Building a phylogenetic tree relating the ‘average’ cell from each group in default ‘Ident’ (currently “RNA_snn_res.0.1”). This tree is estimated based on a distance matrix constructed in either gene expression space or PCA space.
experiment.aggregate <- BuildClusterTree(experiment.aggregate, dims = 1:50)
PlotClusterTree(experiment.aggregate)
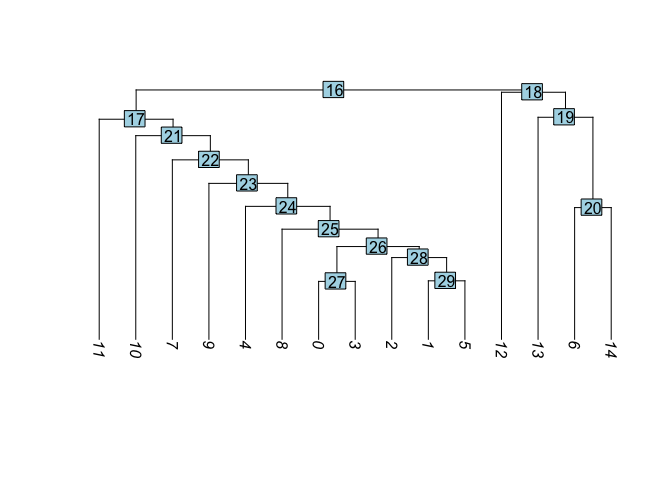
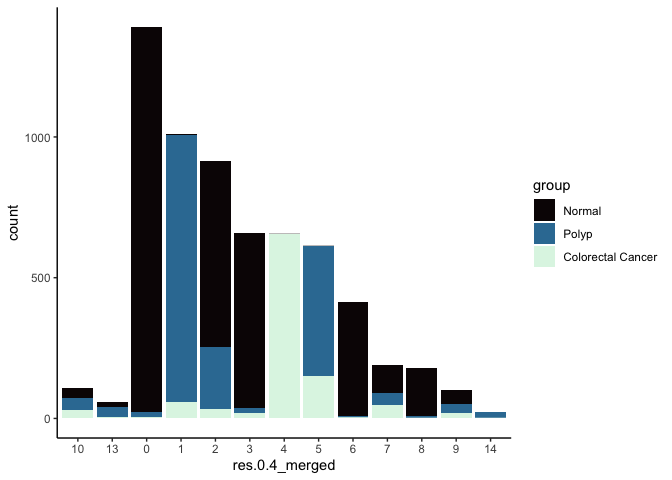
Merge clusters
In many experiments, the clustering resolution does not need to be uniform across all of the cell types present. While for some cell types of interest fine detail may be desirable, for others, simply grouping them into a larger parent cluster is sufficient. Merging cluster is very straightforward.
experiment.aggregate <- RenameIdents(experiment.aggregate,
'11' = '10',
'12' = '13')
experiment.aggregate$res.0.4_merged <- Idents(experiment.aggregate)
table(experiment.aggregate$res.0.4_merged)
experiment.aggregate@meta.data %>%
ggplot(aes(x = res.0.4_merged, fill = group)) +
geom_bar() +
scale_fill_viridis_d(option = "mako") +
theme_classic()
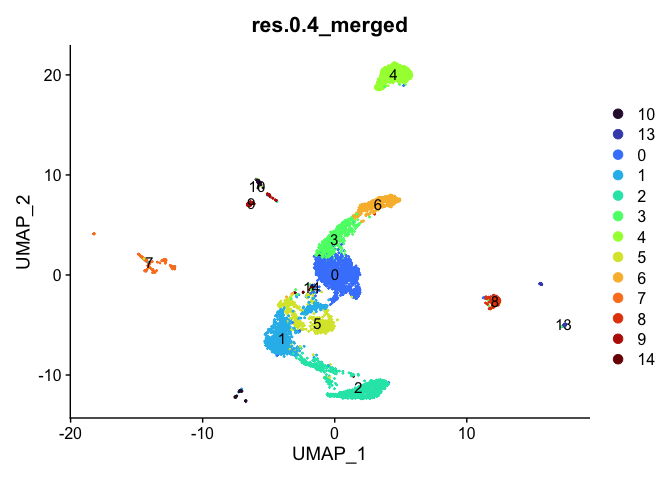
DimPlot(experiment.aggregate,
reduction = "umap",
group.by = "res.0.4_merged",
label = TRUE) +
scale_color_viridis_d(option = "turbo")
VlnPlot(experiment.aggregate,
group.by = "res.0.4_merged",
features = "KCNMA1") +
scale_fill_viridis_d(option = "turbo")
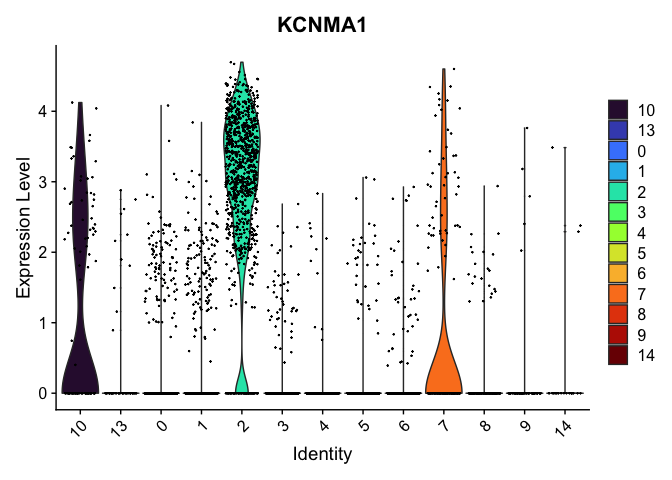
Reorder the clusters
Merging the clusters changed the order in which they appear on a plot. In order to reorder the clusters for plotting purposes take a look at the levels of the identity, then re-level as desired.
levels(experiment.aggregate$res.0.4_merged)
# move one cluster to the first position
experiment.aggregate$res.0.4_merged <- relevel(experiment.aggregate$res.0.4_merged, "0")
levels(experiment.aggregate$res.0.4_merged)
# the color assigned to some clusters will change
VlnPlot(experiment.aggregate,
group.by = "res.0.4_merged",
features = "CAPN9",
pt.size = 0.1) +
scale_fill_viridis_d(option = "turbo")
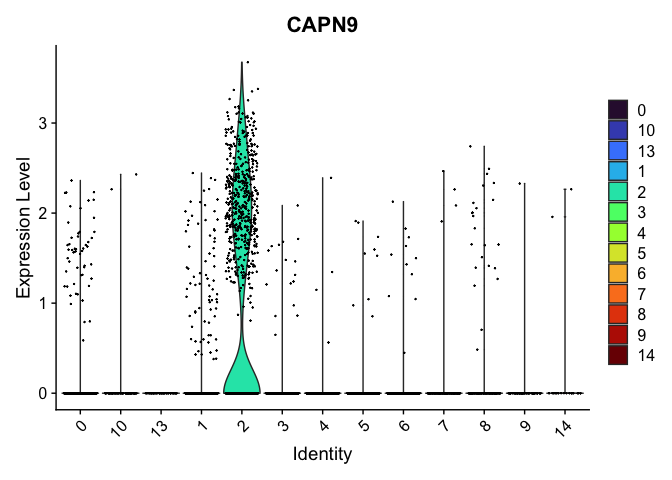
# re-level entire factor
new.order <- as.character(sort(as.numeric(levels(experiment.aggregate$res.0.4_merged))))
experiment.aggregate$res.0.4_merged <- factor(experiment.aggregate$res.0.4_merged, levels = new.order)
levels(experiment.aggregate$res.0.4_merged)
VlnPlot(experiment.aggregate,
group.by = "res.0.4_merged",
features = "MYRIP",
pt.size = 0.1) +
scale_fill_viridis_d(option = "turbo")
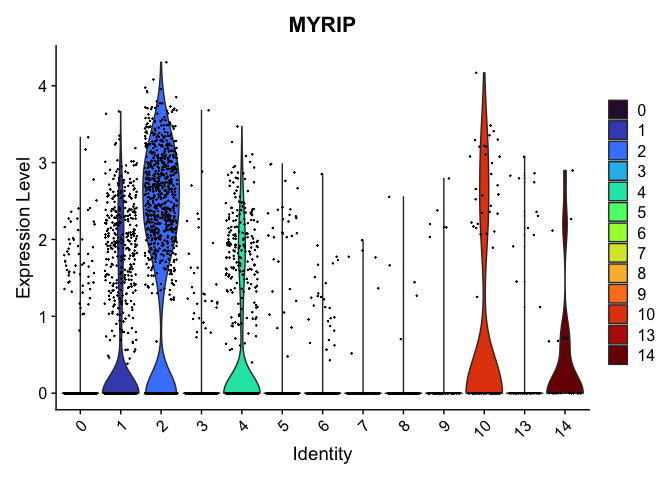
Subcluster
While merging clusters reduces the resolution in some parts of the experiment, sub-clustering has the opposite effect. Let’s produce sub-clusters for cluster 5.
experiment.aggregate <- FindSubCluster(experiment.aggregate,
graph.name = "RNA_snn",
cluster = 5,
subcluster.name = "subcluster")
experiment.aggregate$subcluster <- factor(experiment.aggregate$subcluster,
levels = c(as.character(0:4),
"5_0", "5_1", "5_2", "5_3",
as.character(c(6:10, 13, 14))))
DimPlot(experiment.aggregate,
reduction = "umap",
group.by = "subcluster",
shuffle = TRUE) +
scale_color_viridis_d(option = "turbo")
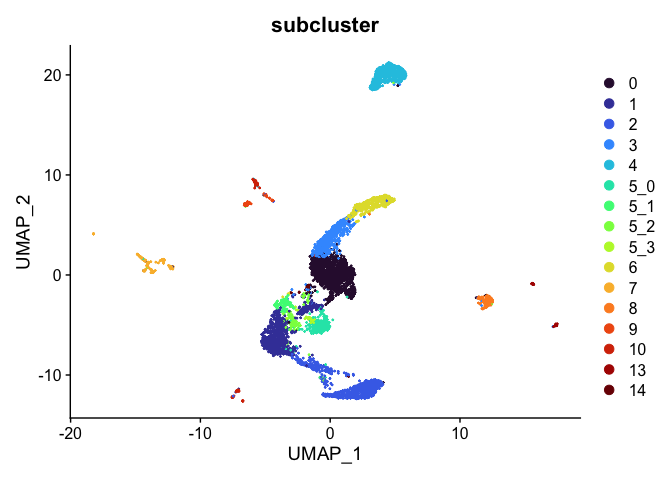
sort(unique(experiment.aggregate$subcluster))
Subset experiment by cluster identity
After exploring and refining the cluster resolution, we may have identified some clusters that are composed of cells we aren’t interested in. For example, if we have identified a cluster likely composed of contaminants, this cluster can be removed from the analysis. Alternatively, if a group of clusters have been identified as particularly of interest, these can be isolated and re-analyzed.
# remove cluster 13
Idents(experiment.aggregate) <- experiment.aggregate$subcluster
experiment.tmp <- subset(experiment.aggregate, subcluster != "13")
DimPlot(experiment.tmp,
reduction = "umap",
group.by = "subcluster",
shuffle = TRUE) +
scale_color_viridis_d(option = "turbo")
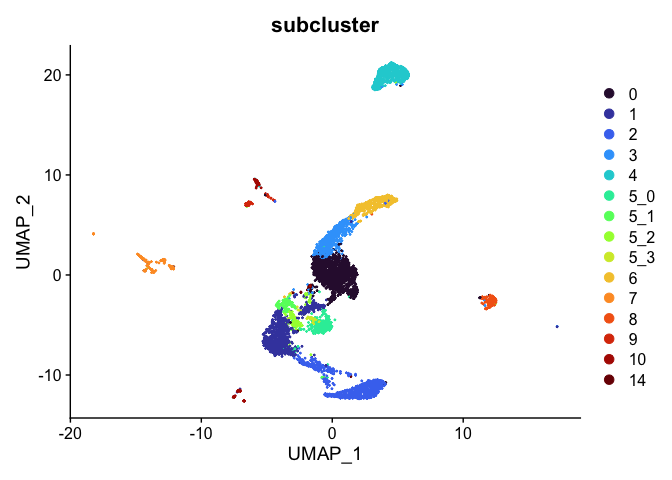
# retain cells belonging only to specified clusters
experiment.tmp <- subset(experiment.aggregate, subcluster %in% c("1", "2", "5_0", "5_1", "5_2", "5_3", "7"))
DimPlot(experiment.tmp,
reduction = "umap",
group.by = "subcluster",
shuffle = TRUE) +
scale_color_viridis_d(option = "turbo")
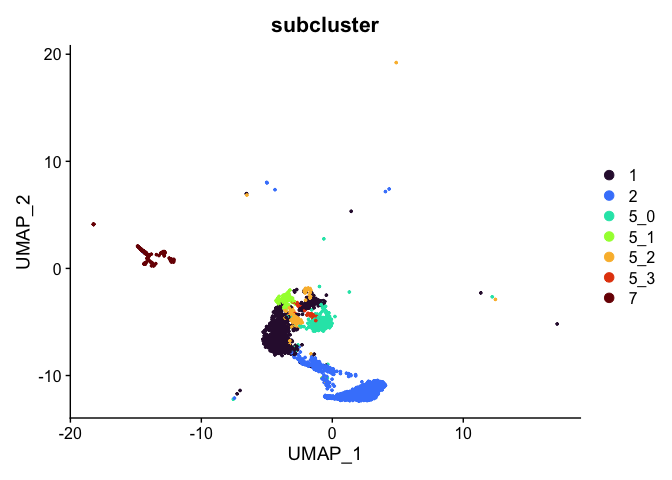
Identify marker genes
Seurat provides several functions that can help you find markers that define clusters via differential expression:
-
FindMarkersidentifies markers for a cluster relative to all other clusters -
FindAllMarkersperforms the find markers operation for all clusters -
FindAllMarkersNodedefines all markers that split a node from the cluster tree
FindMarkers
markers <- FindMarkers(experiment.aggregate,
group.by = "subcluster",
ident.1 = "1")
length(which(markers$p_val_adj < 0.05)) # how many are significant?
head(markers) %>%
kable() %>%
kable_styling("striped")
| p_val | avg_log2FC | pct.1 | pct.2 | p_val_adj | |
|---|---|---|---|---|---|
| CEMIP | 0 | 4.492942 | 0.621 | 0.056 | 0 |
| GRM8 | 0 | 3.071393 | 0.636 | 0.101 | 0 |
| AGBL4 | 0 | 3.094973 | 0.611 | 0.103 | 0 |
| EDAR | 0 | 4.399116 | 0.383 | 0.023 | 0 |
| CASC19 | 0 | 3.217203 | 0.532 | 0.081 | 0 |
| NKD1 | 0 | 3.053094 | 0.529 | 0.085 | 0 |
The “pct.1” and “pct.2” columns record the proportion of cells with normalized expression above 0 in ident.1 and ident.2, respectively. The “p_val” is the raw p-value associated with the differential expression test, while the BH-adjusted value is found in “p_val_adj”. Finally, “avg_logFC” is the average log fold change difference between the two groups.
Marker genes identified this way can be visualized in violin plots, feature plots, and heat maps.
view.markers <- c(rownames(markers[markers$avg_log2FC > 0,])[1],
rownames(markers[markers$avg_log2FC < 0,])[1])
lapply(view.markers, function(marker){
VlnPlot(experiment.aggregate,
group.by = "subcluster",
features = marker) +
scale_fill_viridis_d(option = "turbo")
})
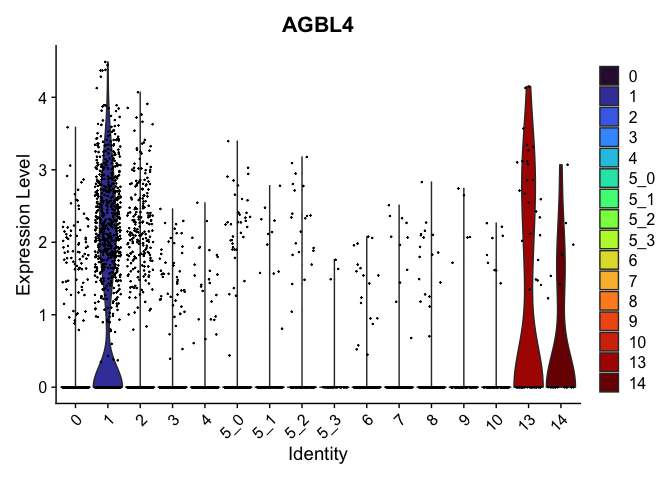
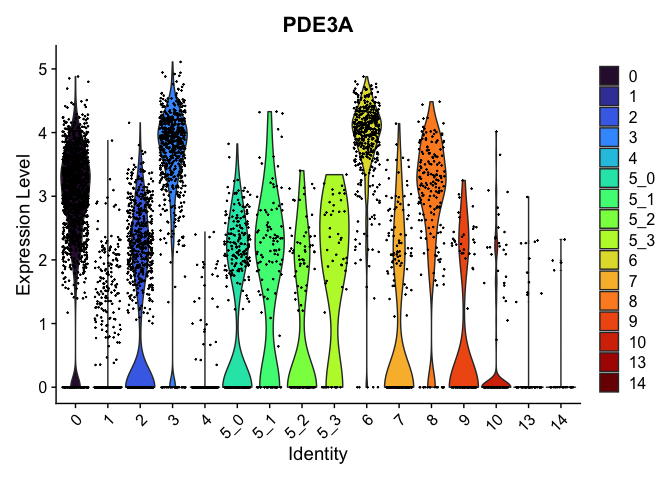
FeaturePlot(experiment.aggregate,
features = view.markers,
ncol = 2)
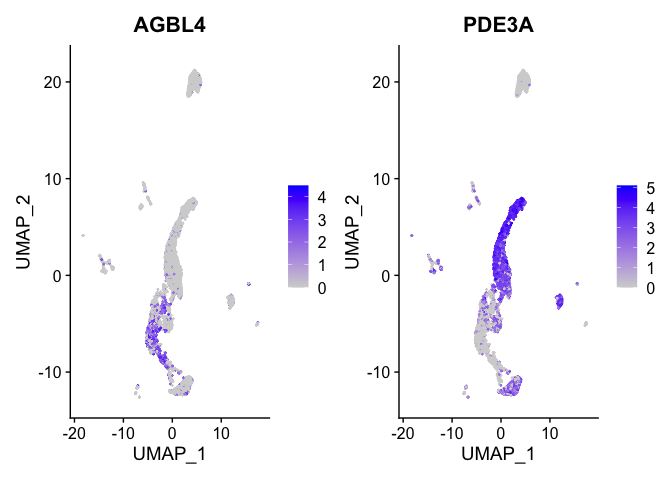
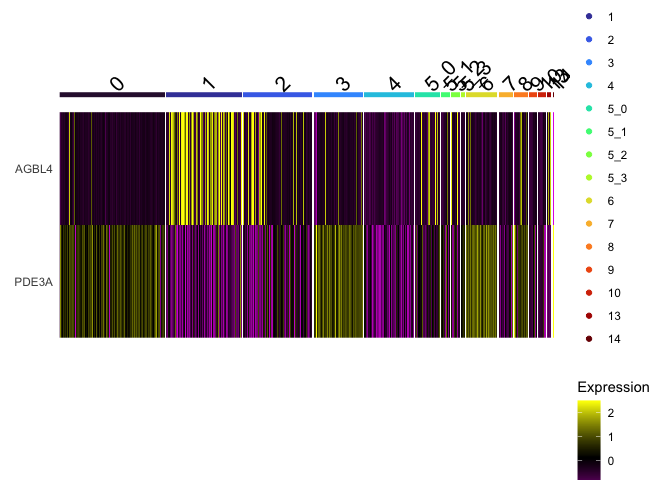
DoHeatmap(experiment.aggregate,
group.by = "subcluster",
features = view.markers,
group.colors = viridis::turbo(length(levels(experiment.aggregate$subcluster))))
Improved heatmap
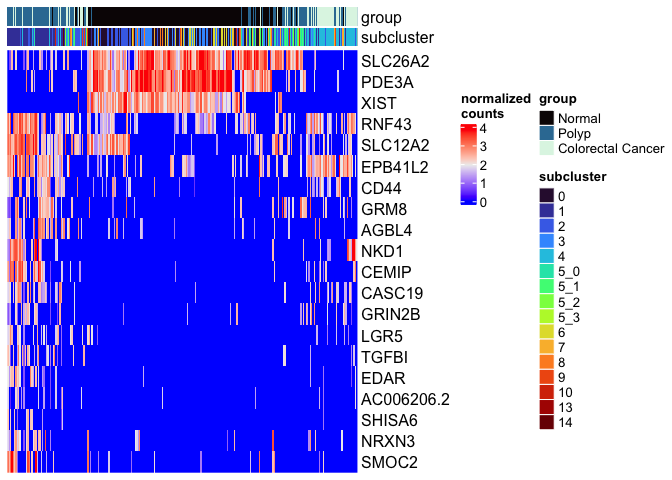
The Seurat DoHeatmap function provided by Seurat provides a convenient look at expression of selected genes. The ComplexHeatmap library generates heat maps with a much finer level of control.
cluster.colors <- viridis::turbo(length(levels(experiment.aggregate$subcluster)))
names(cluster.colors) <- levels(experiment.aggregate$subcluster)
group.colors <- viridis::mako(length(levels(experiment.aggregate$group)))
names(group.colors) <- levels(experiment.aggregate$group)
top.annotation <- columnAnnotation(df = experiment.aggregate@meta.data[,c("group", "subcluster")],
col = list(group = group.colors,
subcluster = cluster.colors))
mat <- as.matrix(GetAssayData(experiment.aggregate[rownames(markers)[1:20],],
slot = "data"))
Heatmap(mat,
name = "normalized\ncounts",
show_row_dend = FALSE,
show_column_dend = FALSE,
show_column_names = FALSE,
top_annotation = top.annotation)
FindAllMarkers
FindAllMarkers can be used to automate this process across all clusters.
Idents(experiment.aggregate) <- "subcluster"
markers <- FindAllMarkers(experiment.aggregate,
only.pos = TRUE,
min.pct = 0.25,
thresh.use = 0.25)
tapply(markers$p_val_adj, markers$cluster, function(x){
length(x < 0.05)
})
head(markers) %>%
kable() %>%
kable_styling("striped")
| p_val | avg_log2FC | pct.1 | pct.2 | p_val_adj | cluster | gene | |
|---|---|---|---|---|---|---|---|
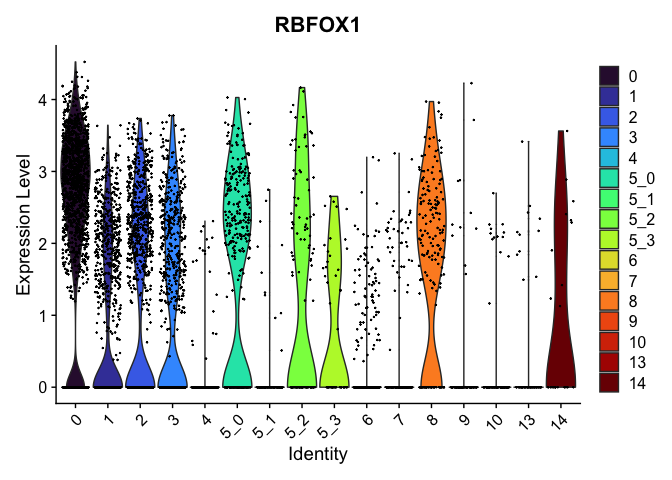
| RBFOX1 | 0 | 2.025116 | 0.855 | 0.409 | 0 | 0 | RBFOX1 |
| NXPE1 | 0 | 1.711350 | 0.958 | 0.597 | 0 | 0 | NXPE1 |
| ADAMTSL1 | 0 | 1.578448 | 0.911 | 0.512 | 0 | 0 | ADAMTSL1 |
| XIST | 0 | 1.523203 | 0.850 | 0.359 | 0 | 0 | XIST |
| HNF1A-AS1 | 0 | 1.379945 | 0.879 | 0.563 | 0 | 0 | HNF1A-AS1 |
| SATB2 | 0 | 1.181755 | 0.937 | 0.665 | 0 | 0 | SATB2 |
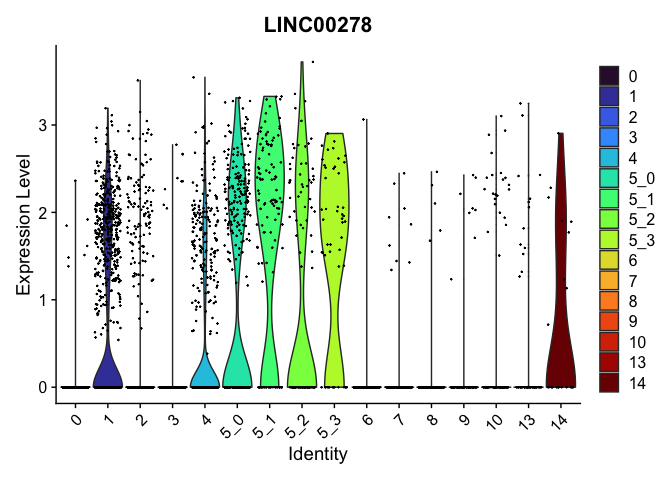
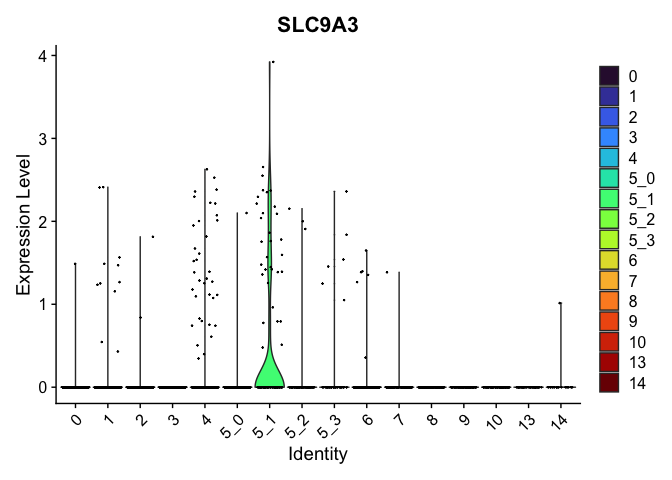
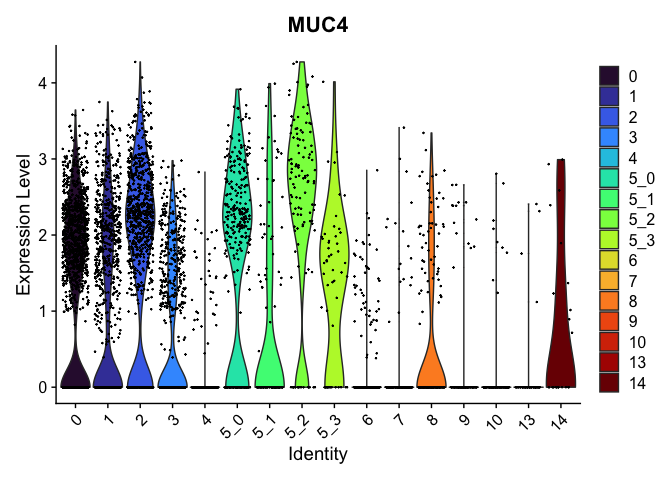
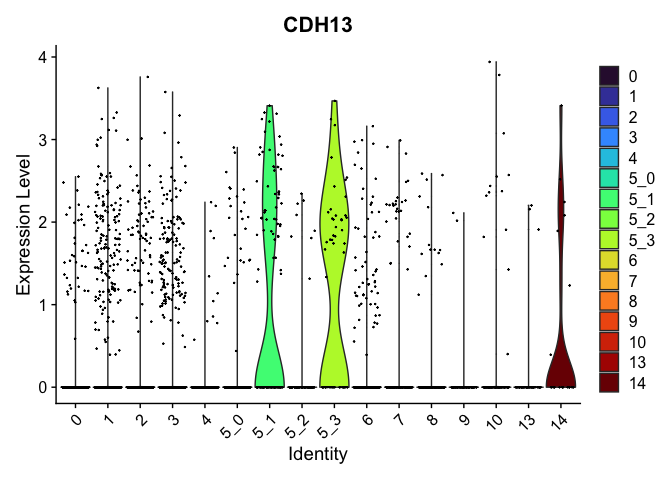
view.markers <- tapply(markers$gene, markers$cluster, function(x){head(x,1)})
# violin plots
lapply(view.markers, function(marker){
VlnPlot(experiment.aggregate,
group.by = "subcluster",
features = marker) +
scale_fill_viridis_d(option = "turbo")
})
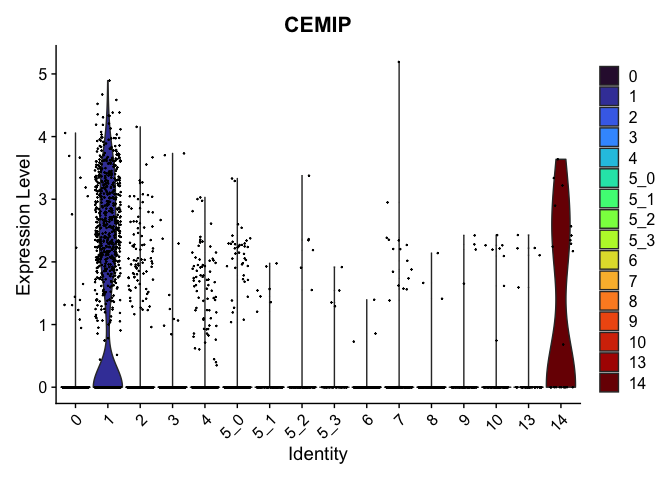
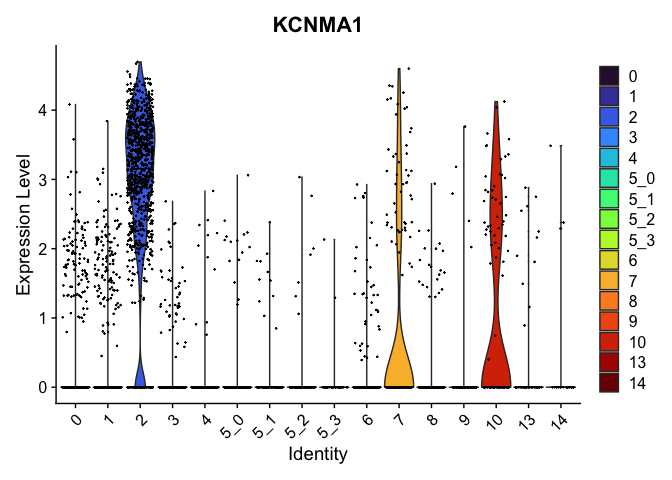
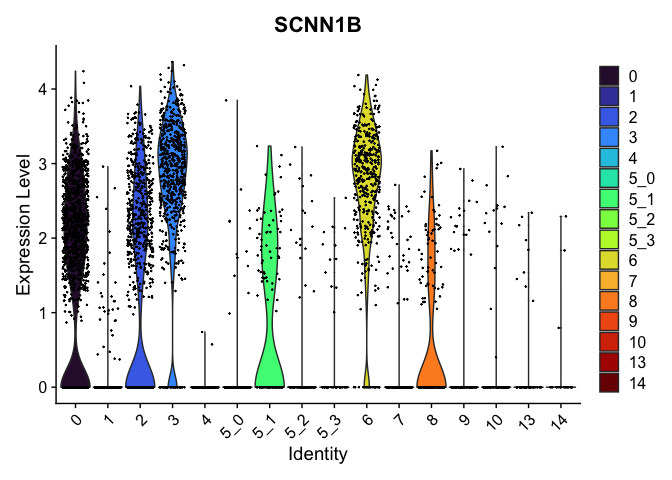
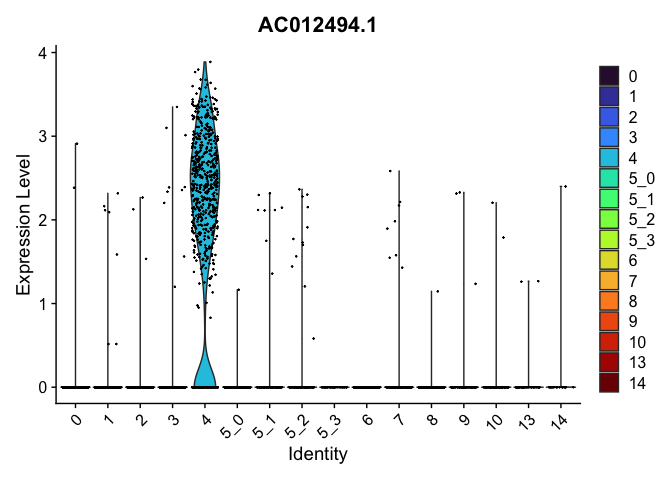
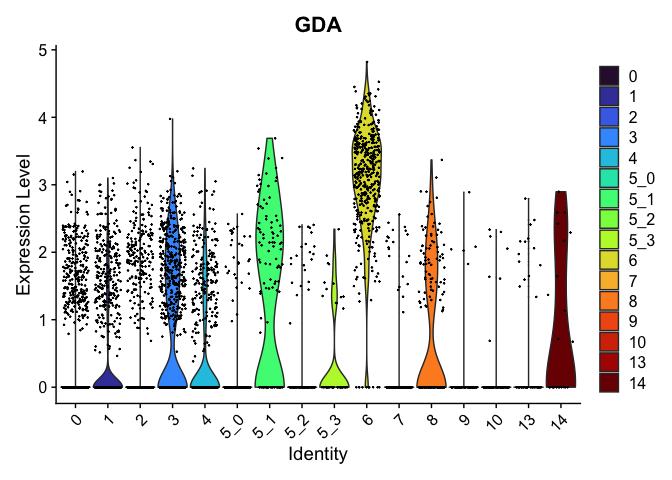
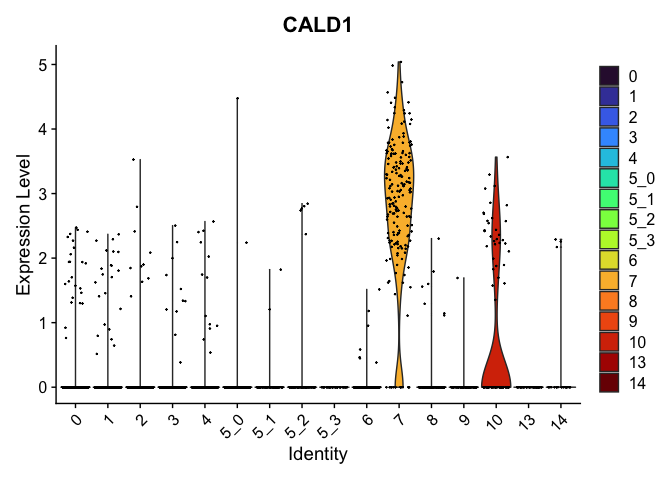
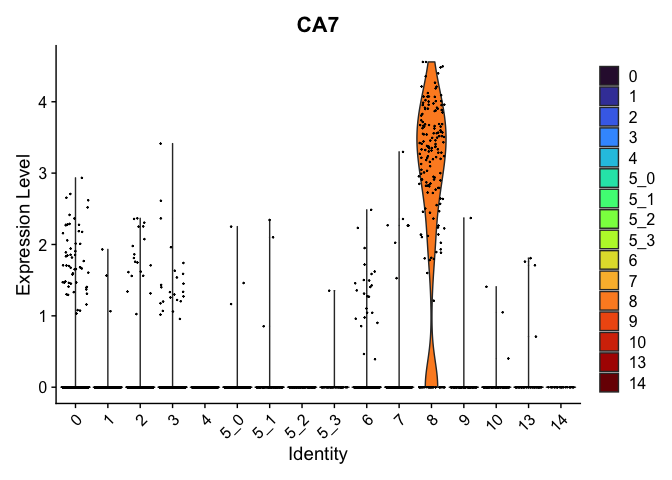
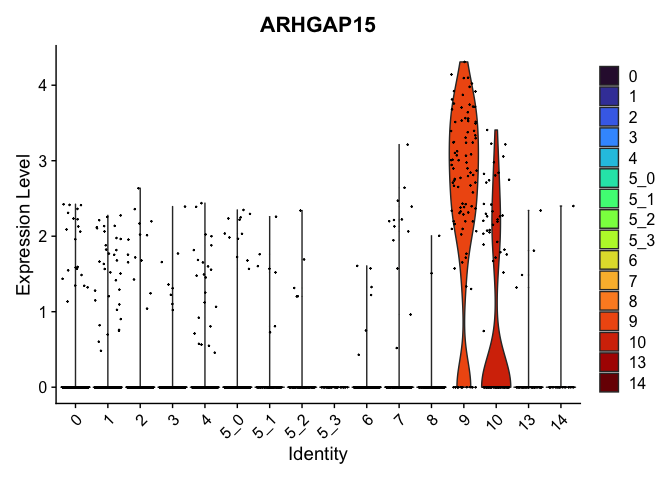
# feature plots
lapply(view.markers, function(marker){
FeaturePlot(experiment.aggregate,
features = marker)
})
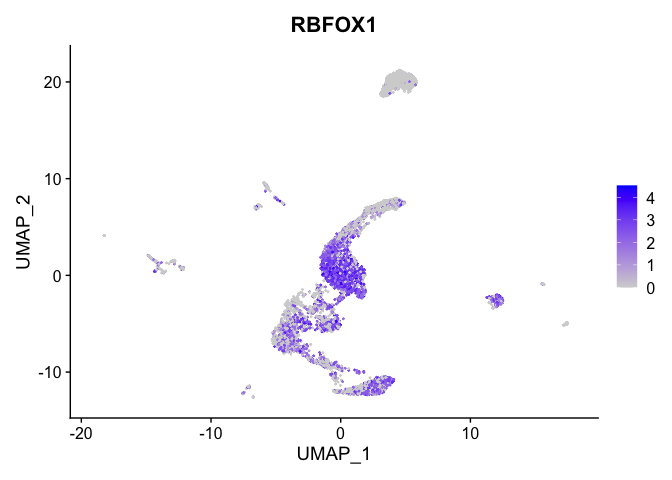
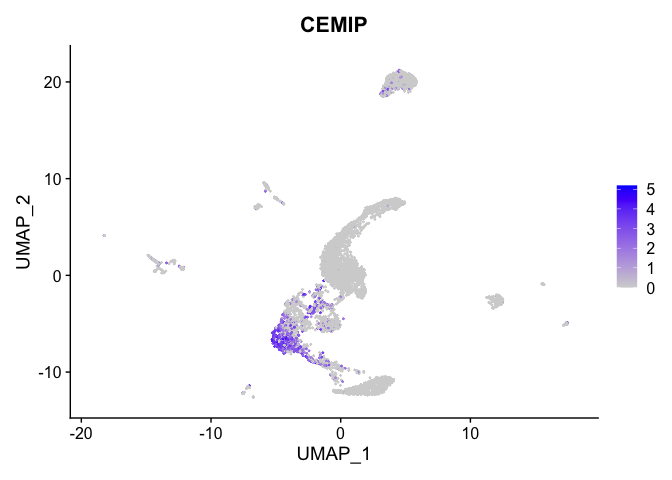
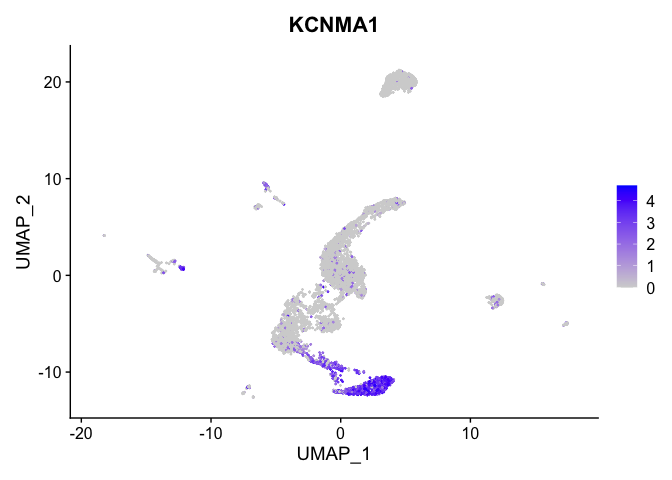
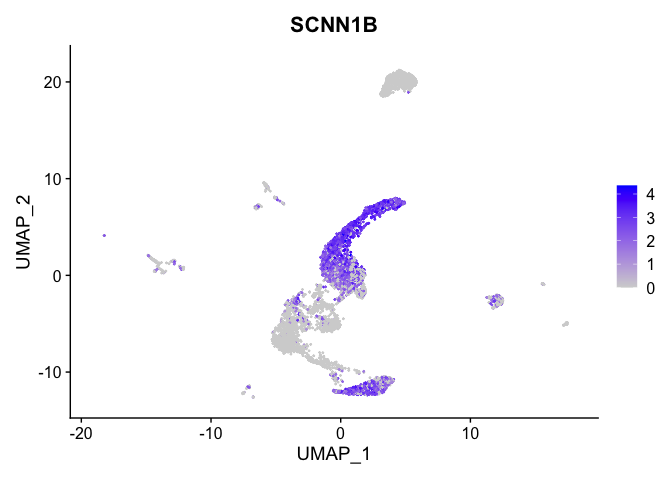
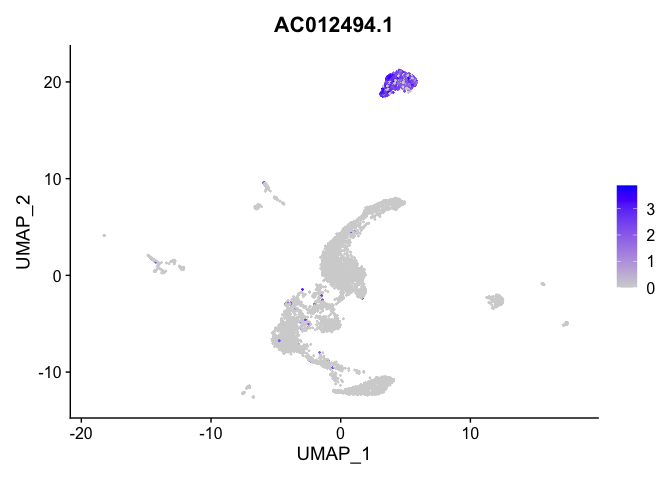
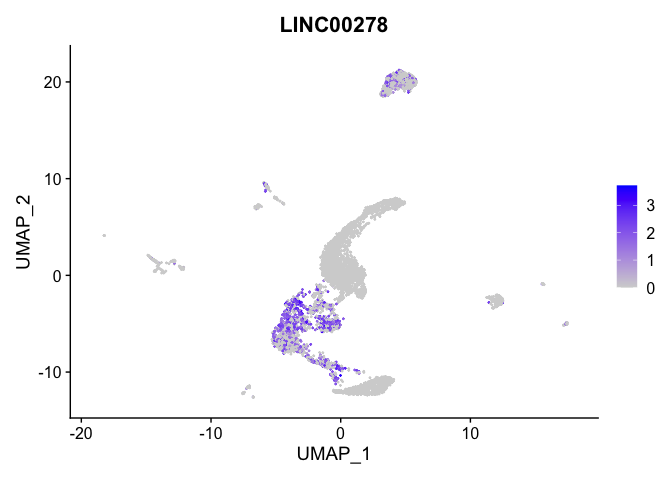
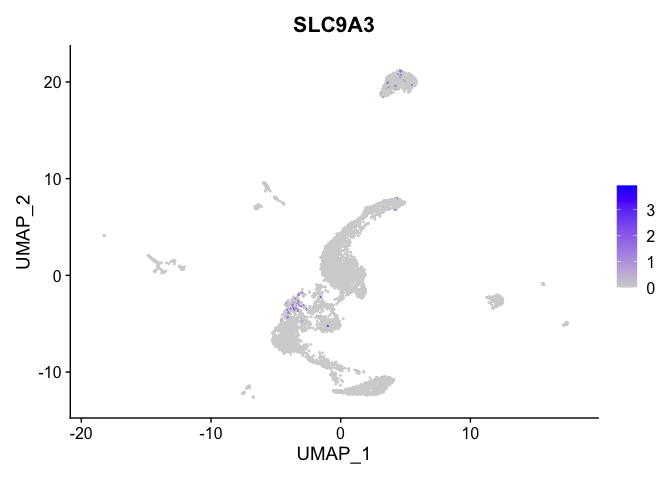
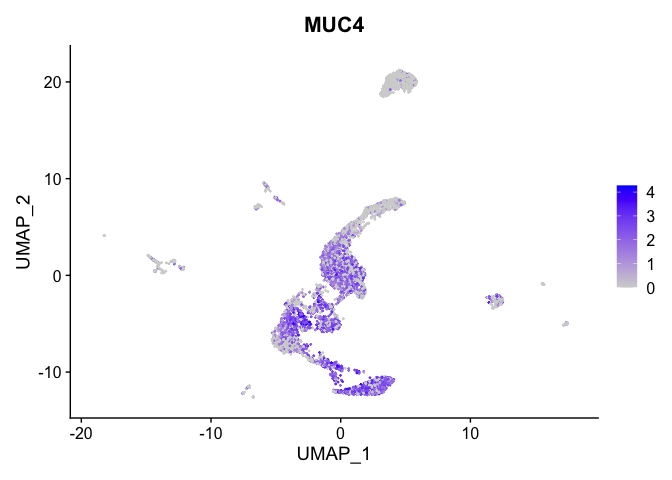
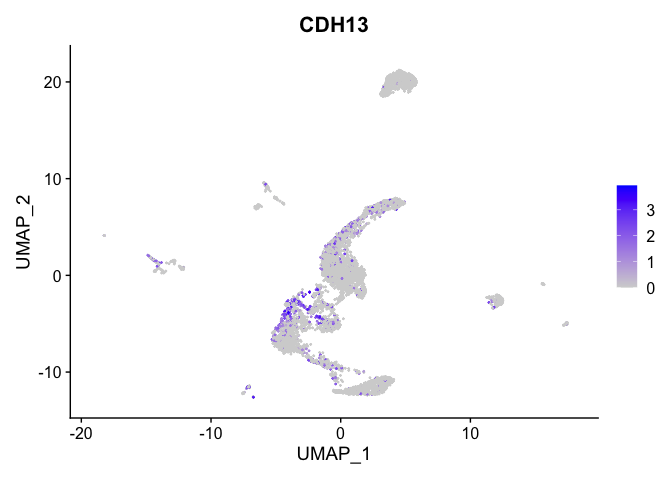
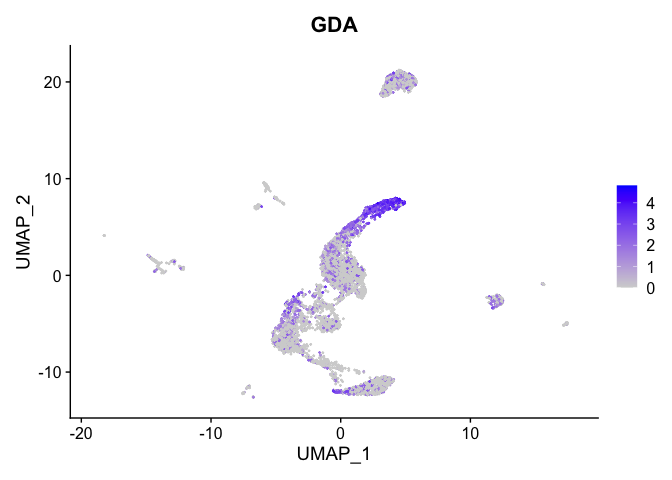
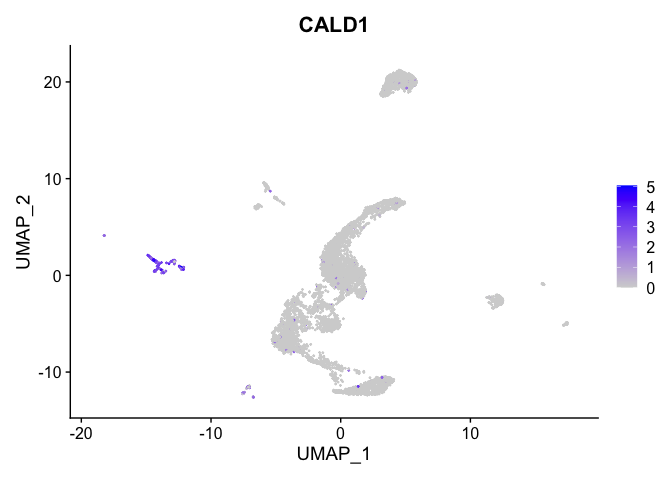
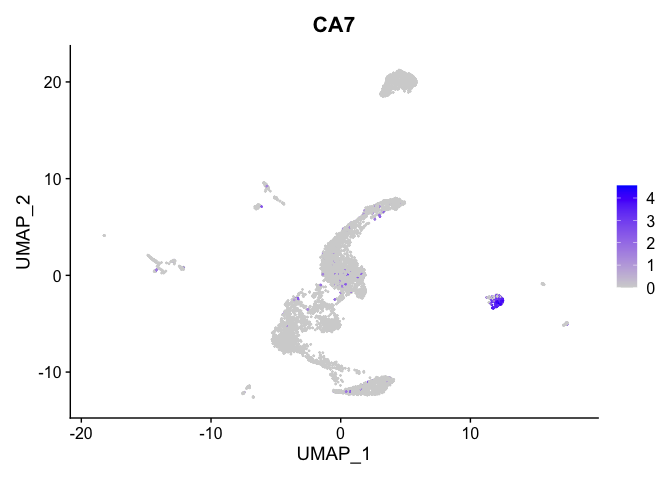
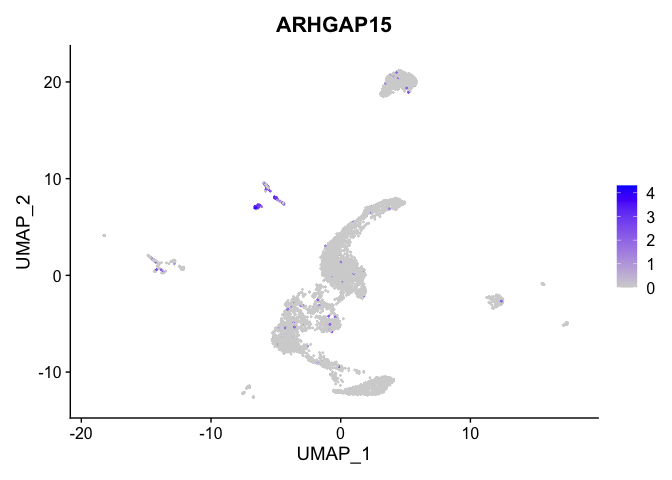
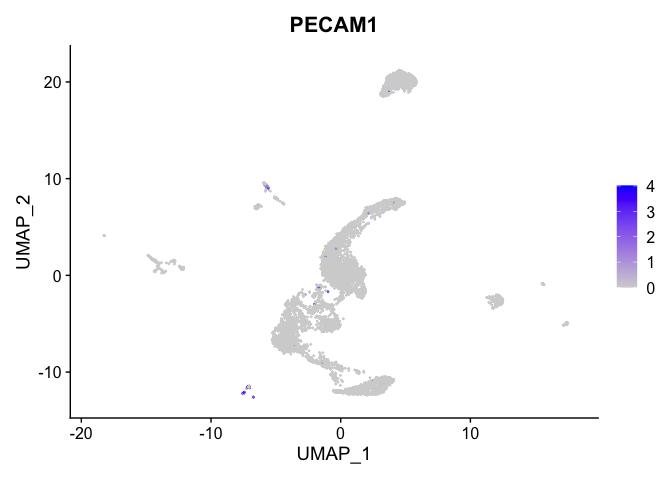
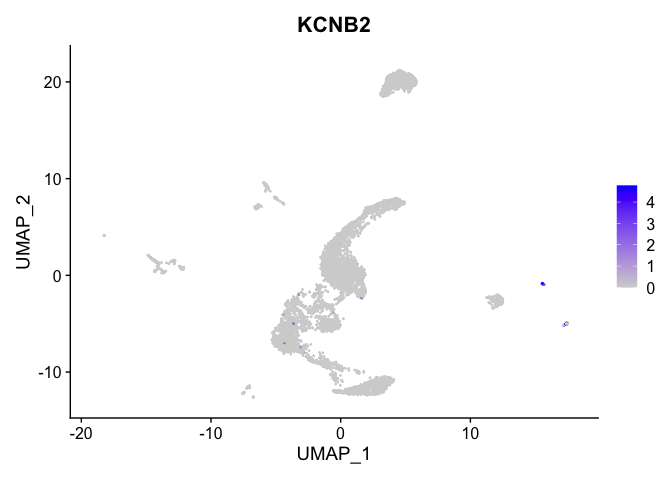
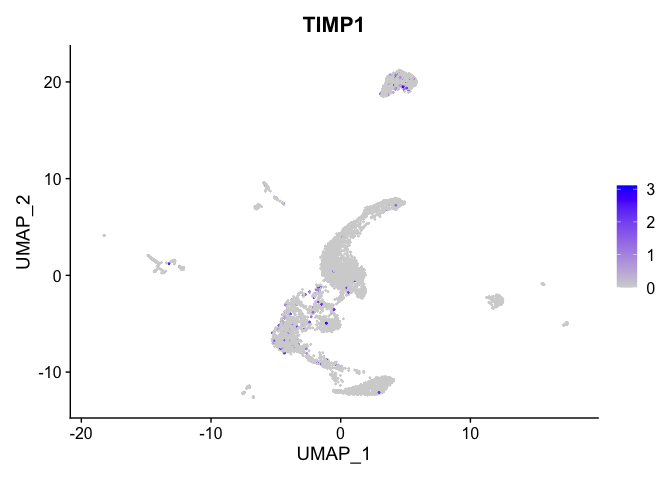
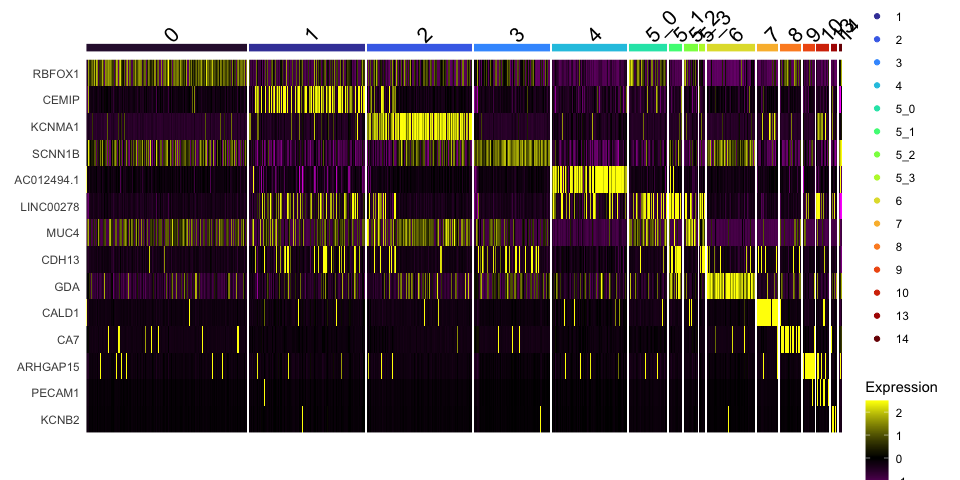
# heat map
DoHeatmap(experiment.aggregate,
group.by = "subcluster",
features = view.markers,
group.colors = viridis::turbo(length(unique(experiment.aggregate$subcluster))))
# ComplexHeatmap
mat <- as.matrix(GetAssayData(experiment.aggregate[view.markers,],
slot = "data"))
Heatmap(mat,
name = "normalized\ncounts",
show_row_dend = FALSE,
show_column_dend = FALSE,
show_column_names = FALSE,
column_split = experiment.aggregate$subcluster,
top_annotation = top.annotation)
Calculate mean marker expression within clusters
You may want to get an idea of the mean expression of markers in a cluster or group of clusters. The percent expressing is provided by FindMarkers and FindAllMarkers, along with the average log fold change, but not the expression value itself. The function below calculates a mean for the supplied marker in the named cluster(s) and all other groups. Please note that this function accesses the active identity.
# ensure active identity is set to desired clustering resolution
Idents(experiment.aggregate) <- experiment.aggregate$subcluster
# define function
getGeneClusterMeans <- function(feature, idents){
x = GetAssayData(experiment.aggregate)[feature,]
m = tapply(x, Idents(experiment.aggregate) %in% idents, mean)
names(m) = c("mean.out.of.idents", "mean.in.idents")
return(m[c(2,1)])
}
# calculate means for a single marker
getGeneClusterMeans("SMOC2", c("1"))
# add means to marker table (example using subset)
markers.small <- markers[view.markers,]
means <- matrix(mapply(getGeneClusterMeans, view.markers, markers.small$cluster), ncol = 2, byrow = TRUE)
colnames(means) <- c("mean.in.cluster", "mean.out.of.cluster")
rownames(means) <- view.markers
markers.small <- cbind(markers.small, means)
markers.small[,c("cluster", "mean.in.cluster", "mean.out.of.cluster", "avg_log2FC", "p_val_adj")] %>%
kable() %>%
kable_styling("striped")
| cluster | mean.in.cluster | mean.out.of.cluster | avg_log2FC | p_val_adj | |
|---|---|---|---|---|---|
| RBFOX1 | 0 | 2.4572798 | 0.9039857 | 2.0251164 | 0 |
| CEMIP | 1 | 1.6549190 | 0.1118442 | 4.4929424 | 0 |
| KCNMA1 | 2 | 2.9307725 | 0.1803269 | 5.0215860 | 0 |
| SCNN1B | 0 | 1.5462679 | 0.9425927 | 0.3043462 | 0 |
| AC012494.1 | 4 | 1.9860483 | 0.0205298 | 7.0988436 | 0 |
| LINC00278 | 1 | 0.7379974 | 0.2781939 | 1.1216293 | 0 |
| SLC9A3 | 5_1 | 0.4735995 | 0.0159515 | 5.3313107 | 0 |
| MUC4 | 0 | 1.3083395 | 0.9080246 | 0.2813731 | 0 |
| CDH13 | 5_1 | 1.0662439 | 0.1748105 | 3.0403457 | 0 |
| HDAC9 | 5_1 | 0.9376478 | 0.2505221 | 1.9565171 | 0 |
| CALD1 | 7 | 2.7875189 | 0.0426053 | 7.1782150 | 0 |
| NOTCH2 | 8 | 2.7919023 | 0.1491101 | 5.5240290 | 0 |
| ARHGAP15 | 9 | 2.4875120 | 0.0532663 | 6.7278361 | 0 |
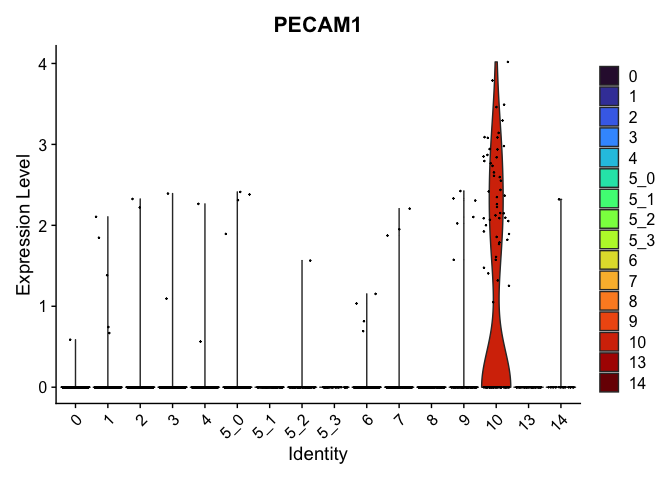
| PECAM1 | 10 | 1.1234271 | 0.0086313 | 7.7152901 | 0 |
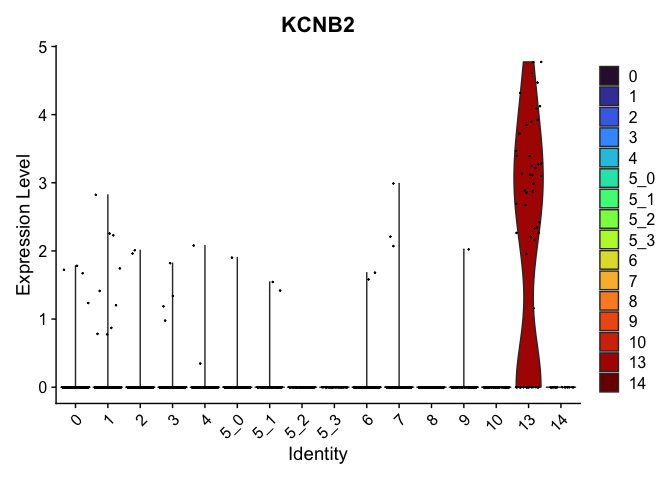
| KCNB2 | 13 | 2.0897079 | 0.0079379 | 9.7517535 | 0 |
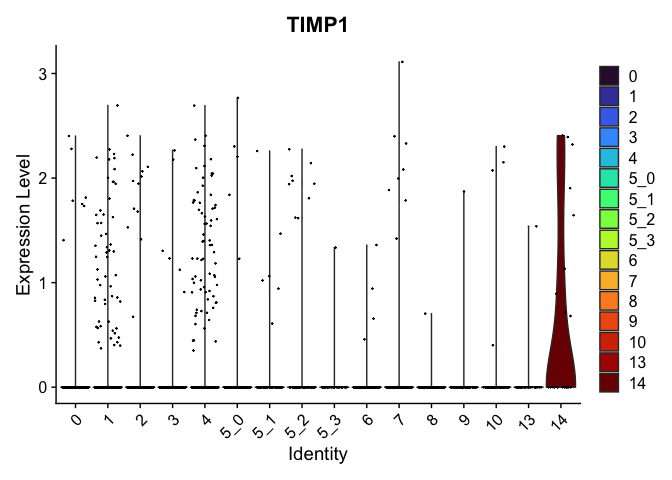
| TIMP1 | 14 | 0.6126504 | 0.0439210 | 4.0030332 | 0 |
Advanced visualizations
Researchers may use the tree, markers, domain knowledge, and goals to identify useful clusters. This may mean adjusting PCA to use, choosing a new resolution, merging clusters together, sub-clustering, sub-setting, etc. You may also want to use automated cell type identification at this point, which will be discussed in the next section.
Address overplotting
Single cell and single nucleus experiments may include so many cells that dimensionality reduction plots sometimes suffer from overplotting, where individual points are difficult to see. The following code addresses this by adjusting the size and opacity of the points.
alpha.use <- 0.4
p <- DimPlot(experiment.aggregate,
group.by="subcluster",
pt.size=0.5,
reduction = "umap",
shuffle = TRUE) +
scale_color_viridis_d(option = "turbo")
p$layers[[1]]$mapping$alpha <- alpha.use
p + scale_alpha_continuous(range = alpha.use, guide = FALSE)
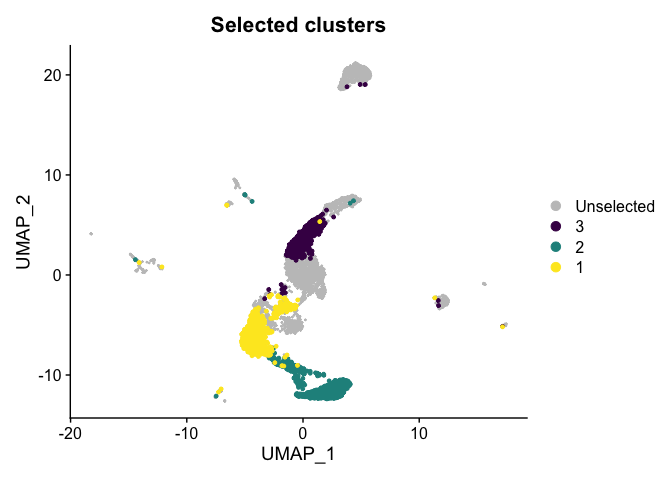
Highlight a subset
DimPlot(experiment.aggregate,
group.by = "subcluster",
cells.highlight = CellsByIdentities(experiment.aggregate, idents = c("1", "2", "3")),
cols.highlight = c(viridis::viridis(3))) +
ggtitle("Selected clusters")
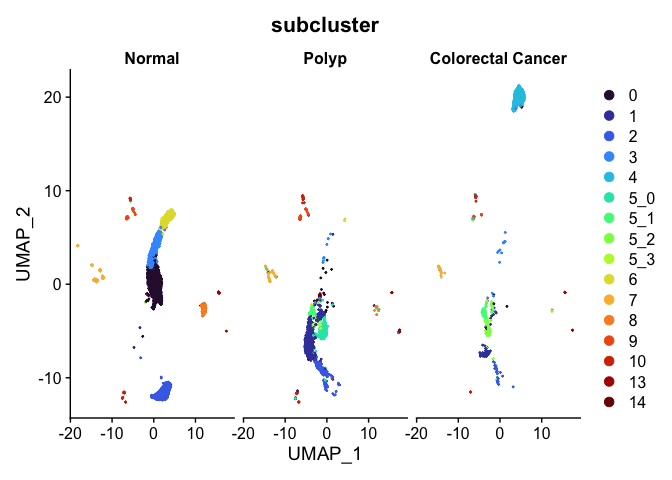
Split dimensionality reduction plots
DimPlot(experiment.aggregate,
group.by = "subcluster",
split.by = "group") +
scale_color_viridis_d(option = "turbo")
Plot a subset of cells
Note that the object itself is unchanged by the subsetting operation.
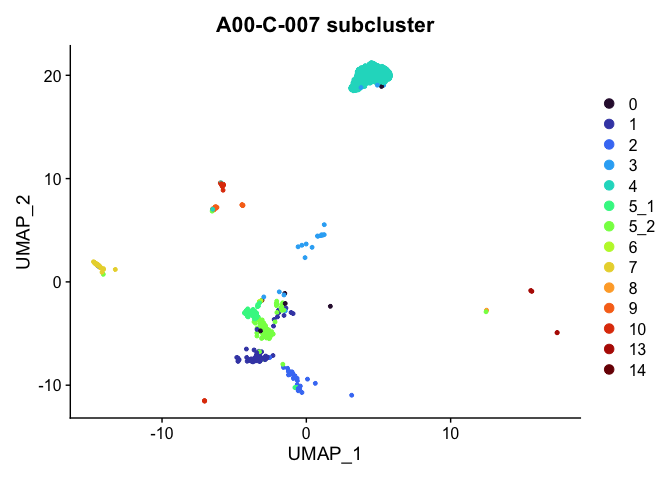
DimPlot(experiment.aggregate,
group.by = "subcluster",
reduction = "umap",
cells = Cells(experiment.aggregate)[experiment.aggregate$orig.ident %in% "A001-C-007"]) +
scale_color_viridis_d(option = "turbo") +
ggtitle("A00-C-007 subcluster")
Automated cell type detection
ScType is one of many available automated cell type detection algorithms. It has the advantage of being fast and flexible; it can be used with the large human and mouse cell type database provided by the authors, with a user-defined database, or with some combination of the two.
In this section, we will use ScType to assign our clusters from Seurat to a cell type based on a hierarchical external database. The database supplied with the package is human but users can supply their own data. More details are available on Github.
Source ScType functions from Github
The source() functions in the code box below run scripts stored in the ScType GitHub repository. These scripts add two additional functions, gene_sets_prepare() and sctype_score(), to the global environment.
source("https://raw.githubusercontent.com/IanevskiAleksandr/sc-type/master/R/gene_sets_prepare.R")
source("https://raw.githubusercontent.com/IanevskiAleksandr/sc-type/master/R/sctype_score_.R")
Create marker database
The authors of ScType have provided an extensive database of human and mouse cell type markers in the following tissues:
- Immune system
- Pancreas
- Liver
- Eye
- Kidney
- Brain
- Lung
- Adrenal
- Heart
- Intestine
- Muscle
- Placenta
- Spleen
- Stomach
- Thymus
To set up the database for ScType, we run the gene_sets_prepare() function on a URL pointing to the full database, specifying the tissue subset to retrieve.
db.URL <- "https://raw.githubusercontent.com/IanevskiAleksandr/sc-type/master/ScTypeDB_full.xlsx"
tissue <- "Intestine"
gs.list <- gene_sets_prepare(db.URL, cell_type = "Intestine")
View(gs.list)
The database is composed of two lists (negative and positive) of cell type markers for the specified tissue. In this case, no negative markers have been provided, so the vectors of gene names in that part of the database are empty (length 0).
In addition to using the database supplied with the package, or substituting another database, it is possible to augment the provided database by changing the provided markers for an existing cell type, or adding another cell type to the object.
Let’s add a cell type and associated markers (markers from PanglaoDB).
gs.list$gs_positive$`Tuft cells` <- c("SUCNR1", "FABP1", "POU2F3", "SIGLECF", "CDHR2", "AVIL", "ESPN", "LRMP", "TRPM5", "DCLK1", "TAS1R3", "SOX9", "TUBB5", "CAMK2B", "GNAT3", "IL25", "PLCB2", "GFI1B", "ATOH1", "CD24A", "ASIC5", "KLF3", "KLF6", "DRD3", "NRADD", "GNG13", "NREP", "RGS2", "RAC2", "PTGS1", "IRF7", "FFAR3", "ALOX5", "TSLP", "IL4RA", "IL13RA1", "IL17RB", "PTPRC")
gs.list$gs_negative$`Tuft cells` <- NULL
Score cells
ScType scores every cell, summarizing the transformed and weighted expression of markers for each cell type. This generates a matrix with the dimensions cell types x cells.
es.max <- sctype_score(GetAssayData(experiment.aggregate, layer = "scale"),
scaled = TRUE,
gs = gs.list$gs_positive,
gs2 = gs.list$gs_negative)
# cell type scores of first cell
es.max[,1]
Score clusters
The “ScType score” of each cluster is calculated by summing the cell-level scores within each cluster. The cell type with the largest (positive) score is the most highly enriched cell type for that cluster.
clusters <- sort(unique(experiment.aggregate$subcluster))
tmp <- lapply(clusters, function(cluster){
es.max.cluster = sort(rowSums(es.max[, experiment.aggregate$subcluster == cluster]), decreasing = TRUE)
out = head(data.frame(subcluster = cluster,
ScType = names(es.max.cluster),
scores = es.max.cluster,
ncells = sum(experiment.aggregate$subcluster == cluster)))
out$rank = 1:length(out$scores)
return(out)
})
cluster.ScType <- do.call("rbind", tmp)
cluster.ScType %>%
pivot_wider(id_cols = subcluster,
names_from = ScType,
values_from = scores) %>%
kable() %>%
kable_styling(bootstrap_options = c("striped"), fixed_thead = TRUE)
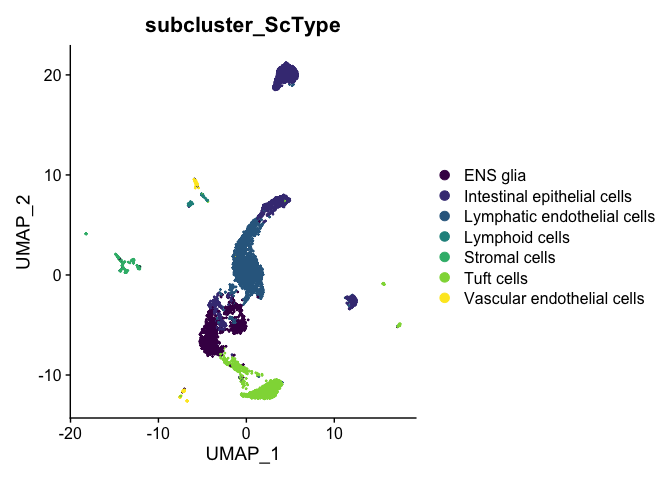
| subcluster | Lymphatic endothelial cells | ENS glia | Lymphoid cells | Vascular endothelial cells | Smooth muscle cells | Stromal cells | Intestinal epithelial cells | Tuft cells |
|---|---|---|---|---|---|---|---|---|
| 0 | 63.3898475 | -10.989658 | -102.3898472 | -107.653784 | -121.581411 | -132.402777 | NA | NA |
| 1 | 16.2827734 | 59.078725 | -49.9188110 | -48.799502 | -86.591059 | NA | -73.8491565 | NA |
| 2 | NA | -13.276428 | -93.9934571 | -57.218099 | 157.702670 | -92.469406 | NA | 234.68964 |
| 3 | 136.8070556 | -55.682447 | -34.7475138 | -50.998283 | NA | -33.896438 | NA | -50.15324 |
| 4 | NA | -12.641656 | -18.4670491 | 28.967538 | -40.548555 | -32.596855 | 136.5868558 | NA |
| 5_0 | 5.6125848 | 7.635946 | -30.7812363 | -34.664302 | -85.843664 | -44.329471 | NA | NA |
| 5_1 | 10.0200260 | NA | 5.4386675 | -7.988753 | NA | -8.264155 | 82.0453510 | 25.48921 |
| 5_2 | -17.0017682 | -8.432776 | -9.1732053 | -11.226220 | NA | -9.981352 | -1.6643326 | NA |
| 5_3 | 25.4537227 | -1.156749 | -5.6889118 | -5.063386 | NA | -7.022599 | NA | -10.69587 |
| 6 | 84.9356495 | NA | -15.1909103 | -37.889131 | NA | -30.310748 | 262.0270174 | 240.41732 |
| 7 | 33.5274002 | 19.229131 | 2.4685436 | 24.056031 | 513.372529 | 538.392998 | NA | NA |
| 8 | NA | 10.178259 | -16.7005497 | -2.699479 | NA | -17.729215 | 538.1786695 | -30.89682 |
| 9 | 0.6974037 | 28.218189 | 330.4094902 | 24.560271 | NA | -17.921440 | NA | 107.87937 |
| 10 | -8.9357191 | 11.774279 | 0.5720622 | 227.698970 | NA | -10.345356 | NA | 59.46269 |
| 13 | -10.8861167 | 14.900876 | -0.5725128 | -5.977856 | NA | -8.817908 | NA | 304.47051 |
| 14 | 10.5955721 | 1.745013 | NA | -2.670358 | -6.344036 | NA | -0.8258375 | 10.12950 |
cluster.ScType.top <- cluster.ScType %>%
filter(rank == 1) %>%
select(subcluster, ncells, ScType, scores)
rownames(cluster.ScType.top) <- cluster.ScType.top$subcluster
cluster.ScType.top <- cluster.ScType.top %>%
rename("score" = scores)
Once the scores have been calculated for each cluster, they can be added to the Seurat object.
subcluster.ScType <- cluster.ScType.top[experiment.aggregate$subcluster, "ScType"]
experiment.aggregate <- AddMetaData(experiment.aggregate,
metadata = subcluster.ScType,
col.name = "subcluster_ScType")
DimPlot(experiment.aggregate,
reduction = "umap",
group.by = "subcluster_ScType",
shuffle = TRUE) +
scale_color_viridis_d()
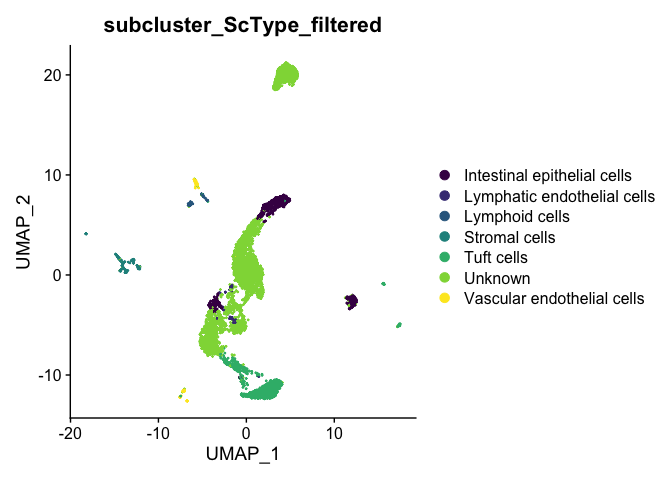
The ScType developer suggests that assignments with a score less than (number of cells in cluster)/4 are low confidence and should be set to unknown:
cluster.ScType.top <- cluster.ScType.top %>%
mutate(ScType_filtered = ifelse(score >= ncells / 4, ScType, "Unknown"))
subcluster.ScType.filtered <- cluster.ScType.top[experiment.aggregate$subcluster, "ScType_filtered"]
experiment.aggregate <- AddMetaData(experiment.aggregate,
metadata = subcluster.ScType.filtered,
col.name = "subcluster_ScType_filtered")
DimPlot(experiment.aggregate,
reduction = "umap",
group.by = "subcluster_ScType_filtered",
shuffle = TRUE) +
scale_color_viridis_d()
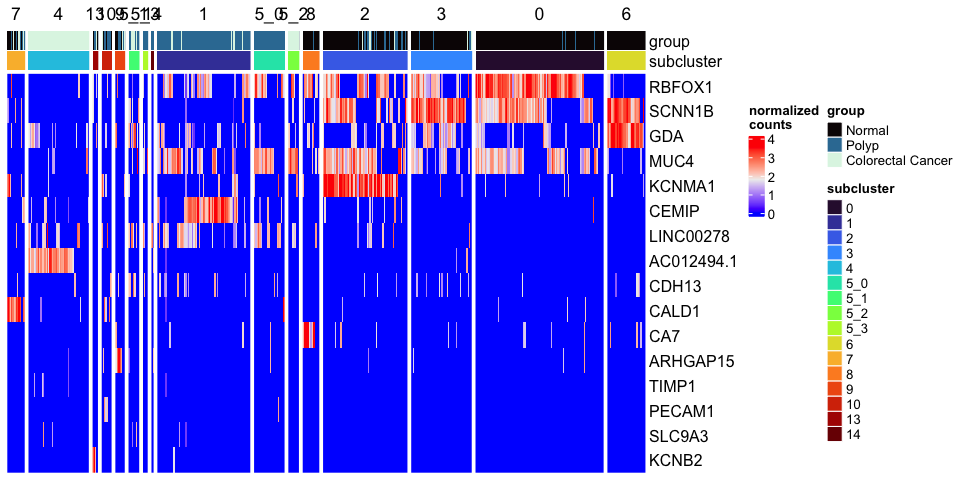
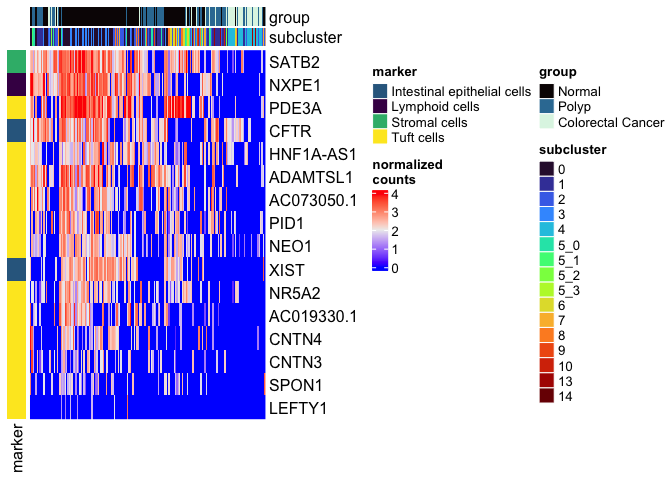
types <- grep("Unknown", unique(experiment.aggregate$subcluster_ScType_filtered), value = TRUE, invert = TRUE)
type.markers <- unlist(lapply(gs.list$gs_positive[types], function(m){
rownames(markers[which(m %in% rownames(markers)),])
}))
type.markers <- type.markers[!duplicated(type.markers)]
type.markers.df <- data.frame(marker = type.markers,
type = gsub('[0-9]', '', names(type.markers)))
type.colors <- viridis::viridis(length(unique(type.markers.df$type)))
names(type.colors) <- unique(type.markers.df$type)
left.annotation <- rowAnnotation("marker" = type.markers.df$type, col = list(marker = type.colors))
mat <- as.matrix(GetAssayData(experiment.aggregate,
slot = "data")[type.markers.df$marker,])
Heatmap(mat,
name = "normalized\ncounts",
top_annotation = top.annotation,
left_annotation = left.annotation,
show_column_dend = FALSE,
show_column_names = FALSE,
show_row_dend = FALSE)
Prepare for the next section
Save the Seurat object and download the next Rmd file
# set the finalcluster to subcluster
experiment.aggregate$finalcluster <- experiment.aggregate$subcluster
# save object
saveRDS(experiment.aggregate, file="scRNA_workshop-05.rds")
Download the Rmd file
download.file("https://raw.githubusercontent.com/ucdavis-bioinformatics-training/2023-December-Single-Cell-RNA-Seq-Analysis/main/data_analysis/06-de_enrichment.Rmd", "06-de_enrichment.Rmd")
Session Information
sessionInfo()