
Introduction to Single Cell RNA-Seq Part 4: Dimensionality reduction
Single cell (or nucleus) data are extremely high-dimensional. In order to reduce the complexity of analysis and remove sources of noise, dimensionality reduction is an important step in the analysis workflow. In this section, we will be using two dimension reduction methods: PCA and UMAP.
Set up workspace
library(Seurat)
library(ggplot2)
experiment.aggregate <- readRDS(file="scRNA_workshop-03.rds")
experiment.aggregate
set.seed(12345)
Perform dimensionality reduction with PCA
Principal Components Analysis (PCA) is a widely-used dimension reduction method. Each PC is a vector in the reduced-dimensional space that is orthogonal to all preceding PCs. The first of these explains the largest amount of variation and each subsequent PC explains slightly less than the preceding component. PCA is performed on the scaled data, and therefore uses only the variable features.
?RunPCA
experiment.aggregate <- RunPCA(experiment.aggregate, npcs = 100)
While it is theoretically possible to calculate as many PCs as there are features in the data, typically 100 PCs is more than sufficient. In fact, many of these PCs may explain negligible amounts of variation. Seurat provides a number of ways to visualize the PCA results.
Principal components plot
The PCA biplot is a scatter plot showing the placement of each cell on two selected components. By default, the first and second PC are used, but any two calculted PCs may be specified.
At this point in the analysis, since we are no longer performing QA and filtering, we can move to examining relationships between cells on a per-group rather than per-sample basis.
DimPlot(experiment.aggregate,
group.by = "group",
reduction = "pca",
shuffle = TRUE) +
scale_color_viridis_d(option = "mako")
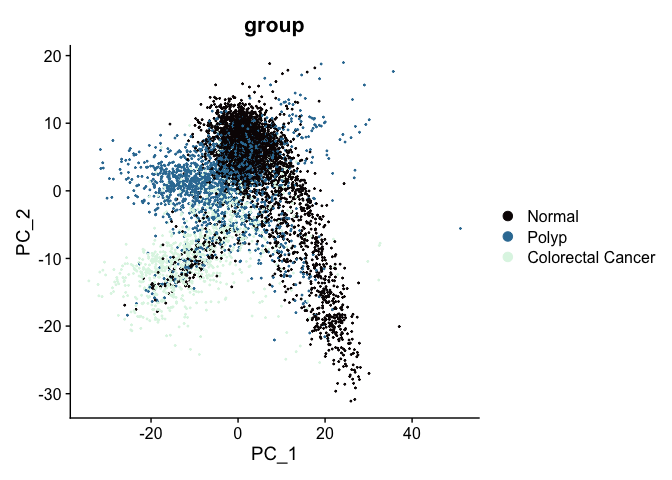
The axes are unit-less; points (cells or nuclei) that are farther apart are more dissimilar on the displayed PC than points that are closer together.
PCA loadings
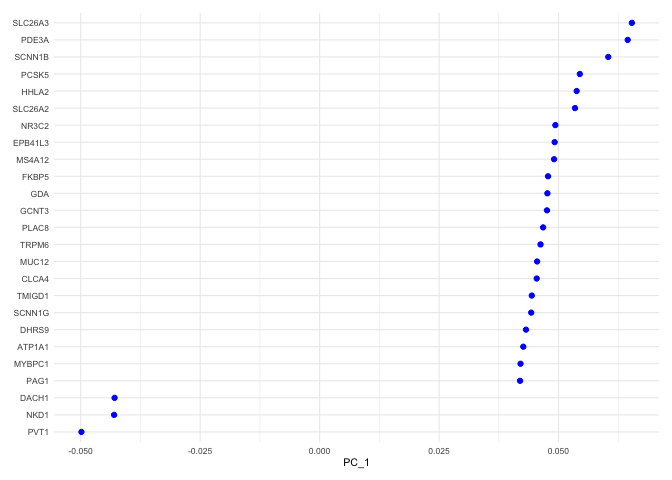
Each PC can be imagined as a sort of meta-gene for which every cell has an expression value. The top genes associated with the reduction component (i.e. contributing to a cell’s “expression level” of that meta-gene) can be plotted for a selected dimension(s) using the VizDimLoadings function.
VizDimLoadings(experiment.aggregate,
dims = 1,
nfeatures = 25,
reduction = "pca",
ncol = 1) +
theme_minimal(base_size = 8)
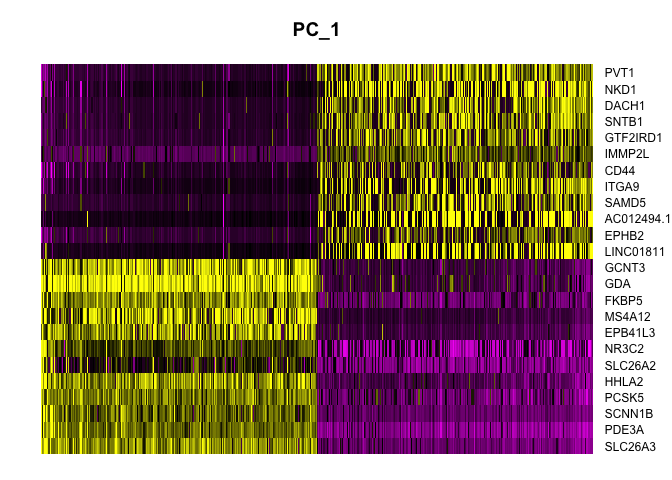
Heat map
Heat maps display similar information. On the x-axis, cells are ordered by their embeddings (“expression” of the PC), while on the y-axis, genes are ordered by PC loading. When fewer than the total number of cells is selected, this results in selection of the cells with the largest absolute value embeddings, which emphasizes variation on the PC.
DimHeatmap(experiment.aggregate,
dims = 1,
nfeatures = 25,
cells = 500,
reduction = "pca",
balanced = TRUE,
slot = "scale.data")
Explore
Re-import the original data and try modifying the ScaleData vars.to.regress argument. You could remove some variables, or add others. What happens? See how choices effect the plots.
experiment.explore <- readRDS("scRNA_workshop-03.rds")
experiment.explore <- ScaleData(experiment.explore) # make changes here to explore the data
experiment.explore <- RunPCA(experiment.explore) # what happens if you adjust npcs?
VizDimLoadings(experiment.explore, dims = 1:2)
DimPlot(experiment.explore, reduction = "pca")
DimHeatmap(experiment.explore, dims = 1:6, cells = 500, balanced = TRUE) # adjust parameters
Selecting PCs to use
To overcome the extensive technical noise in any single gene, Seurat clusters cells based on their PCA scores, with each PC essentially representing a meta-gene that combines information across a correlated gene set. Determining how many PCs to include downstream is therefore an important step.
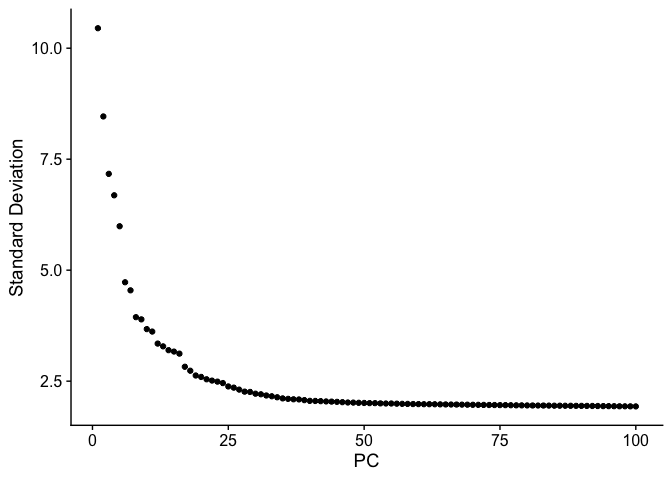
Elbow plot
An elbow plot displays the standard deviations (or approximate singular values if running PCAFast) of the principle components for easy identification of an elbow in the graph. This elbow often corresponds well with the significant PCs and is much faster to run. This is the traditional approach to selecting principal components.
The appearance of elbow plots tends to be highly consistent across single cell / single nucleus experiments. Generally, the line approaches zero at around PC 50. This is a reasonable number of PCs to use for the downstream steps.
ElbowPlot(experiment.aggregate, ndims = 100)
JackStraw
The JackStraw function randomly permutes a subset of data, and calculates projected PCA scores for these genes. The PCA scores for these randomly permuted genes are then compared with the observed PCA scores to determine statistical significance. The end result is a p-value for each gene’s association with each principal component.
PCs with a strong enrichment of low p-value genes are identified as significant components.
The JackStraw permutation is computationally intensive and can be quite slow. Consider skipping this step and exploring the function when you have some extra time.
experiment.aggregate <- JackStraw(experiment.aggregate, dims = 100)
experiment.aggregate <- ScoreJackStraw(experiment.aggregate, dims = 1:100)
JackStrawPlot(object = experiment.aggregate, dims = 1:100) +
scale_color_viridis_d() +
theme(legend.position="bottom")
Let’s use the first 50 PCs.
use.pcs <- 1:50
UMAP
Uniform Manifold Approximation and Projection (UMAP) is a dimensionality reduction method that is commonly used in single cell RNA-Seq analysis. Single cell data is extremely high-dimensional; UMAP calculates a nearest neighbor network describing the relationships between cells as measured by the PC loadings of variable genes and creates a low-dimensional space that preserves these relationships.
# calculate UMAP
experiment.aggregate <- RunUMAP(experiment.aggregate,
dims = use.pcs)
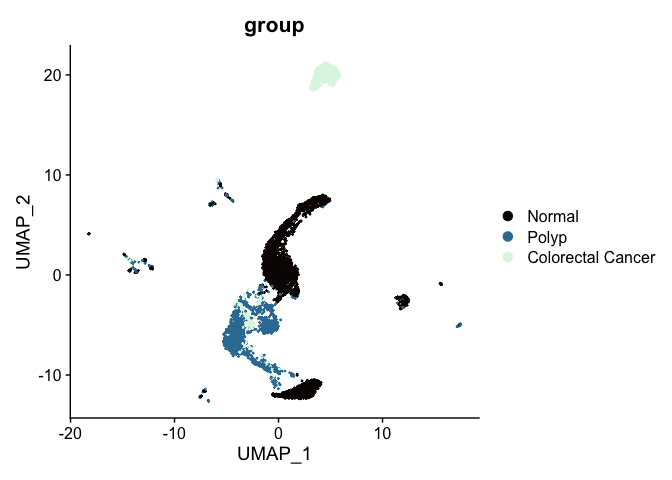
While UMAP can be a general non-linear dimensionality reduction approach, it’s most frequently used as a visualization technique. A UMAP biplot offers a very useful graphical representation of the relationships captured by the nearest neighbor graph.
# UMAP colored by sample identity
DimPlot(experiment.aggregate,
group.by = "group",
reduction = "umap",
shuffle = TRUE) +
scale_color_viridis_d(option = "mako")
Prepare for the next section
Save object
saveRDS(experiment.aggregate, file="scRNA_workshop-04.rds")
Download Rmd
download.file("https://raw.githubusercontent.com/ucdavis-bioinformatics-training/2023-December-Single-Cell-RNA-Seq-Analysis/main/data_analysis/05-integration.Rmd", "05-integration.Rmd")
Session information
sessionInfo()