
ChIPseq and ATACseq Project Setup
Let’s set up a project directory for the week, and talk a bit about project philosophy..
Creating a ChIPseq Project Directory
First, create a directory for you and the example project in the workshop share directory:
cd
mkdir -p /share/workshop/epigenetics_workshop/$USER/chipseq_example
Link Raw Fastq files
-
Next, go into that directory, create a raw data directory (we are going to call this 00-RawData) and cd into that directory. Lets then create symbolic links to the sample directories that contains the raw data.
cd /share/workshop/epigenetics_workshop/$USER/chipseq_example mkdir 00-RawData cd 00-RawData/ ln -s /share/biocore/workshops/2020_Epigenetics/ChIPseq/00-RawData/* .This directory now contains a folder for each sample and the fastq files for each sample are in the sample folders.
-
Let’s create a sample sheet for the project and store sample names in a file called samples.txt
ls > ../samples.txt cat ../samples.txt
Getting To Know Your Raw Data
Lets first spend a minute talking about sequence read files and the fastq file format.
-
Now, take a look at the raw data directory.
ls /share/workshop/epigenetics_workshop/$USER/chipseq_example/00-RawDataYou will see a list of the contents of each directory.
ls *Lets get a better look at all the files in all of the directories.
ls -lah */* -
Pick a directory and go into it. View the contents of the files using the ‘less’ command, when gzipped used ‘zless’ (which is just the ‘less’ command for gzipped files):
cd JLDY037E zless JLDY037E_S5_L005_R1_001.fastq.gzMake sure you can identify which lines correspond to a read and which lines are the header, sequence, and quality values. Press ‘q’ to exit this screen.
-
Then, let’s figure out the number of reads in this file. A simple way to do that is to count the number of lines and divide by 4 (because the record of each read uses 4 lines). In order to do this use cat to output the uncompressed file and pipe that to “wc” to count the number of lines:
zcat JLDY037E_S5_L005_R1_001.fastq.gz | wc -lDivide this number by 4 and you have the number of reads in this file.
-
One more thing to try is to figure out the length of the reads without counting each nucleotide. First get the first 4 lines of the file (i.e. the first record):
zcat JLDY037E_S5_L005_R1_001.fastq.gz | head -2 | tail -1Note the header lines (1st and 3rd line) and sequence and quality lines (2nd and 4th) in each 4-line fastq block.
-
Then, copy and paste the DNA sequence line into the following command (replace [sequence] with the line):
echo -n [sequence] | wc -cThis will give you the length of the read. Also can do the bash one liner:
echo -n $(zcat JLDY037E_S5_L005_R1_001.fastq.gz | head -2 | tail -1) | wc -cSee if you can figure out how this command works.
Prepare our experiment folder for analysis
Now go back to your ‘chipseq_example’ directory and create two directories called ‘slurm_out’ and ‘01-HTS_Preproc’:
cd /share/workshop/epigenetics_workshop/$USER/chipseq_example
mkdir slurm_out
mkdir 01-HTS_Preproc
The results of all our slurm script will output .out and .err files into the slurm_out folder. The results of our preprocessing steps will be put into the 01-HTS_Preproc directory. The next step after that will go into a “02-…” directory, etc. You can collect scripts that perform each step, and notes and metadata relevant for each step, in the directory for that step. This way anyone looking to replicate your analysis has limited places to search for the commands you used. In addition, you may want to change the permissions on your original 00-RawData directory to “read only”, so that you can never accidentally corrupt (or delete) your raw data. We won’t worry about this here, because we’ve linked in sample folders.
Your directory should then look like the below:
$ ls
00-RawData 01-HTS_Preproc samples.txt slurm_out
Questions you should now be able to answer.
- How many reads are in the sample you checked?
- How many basepairs is R1, how many is R2?
- What is the name of the sequencer this dataset was run on?
- Which run number is this for that sequencing?
- What lane was this ran on?
- Randomly check a few samples, were the all run the same sequencing, run, and lane?
Creating a ATACseq Project Directory
First, create a directory for you and the example project in the workshop share directory:
cd
mkdir -p /share/workshop/epigenetics_workshop/$USER/atacseq_example
Link Raw Fastq files
-
Next, go into that directory, create a raw data directory (we are going to call this 00-RawData) and cd into that directory. Lets then create symbolic links to the sample directories that contains the raw data.
cd /share/workshop/epigenetics_workshop/$USER/atacseq_example mkdir 00-RawData cd 00-RawData/ ln -s /share/biocore/workshops/2020_Epigenetics/ATACseq/00-RawData/* .This directory now contains a folder for each sample and the fastq files for each sample are in the sample folders.
-
Let’s create a sample sheet for the project and store sample names in a file called samples.txt
ls > ../samples.txt cat ../samples.txt -
Now just like before, get to know your data.
Perform the same operations as you did with ChIPseq
-
Prepare our experiment folder for analysis
Now go back to your ‘atacseq_example’ directory and create two directories called ‘slurm_out’ and ‘01-HTS_Preproc’:
cd /share/workshop/epigenetics_workshop/$USER/atacseq_example
mkdir slurm_out
mkdir 01-HTS_Preproc
- What are the differences between the 2 datasets???
A Peak Based Assay Data Reduction Flowchart
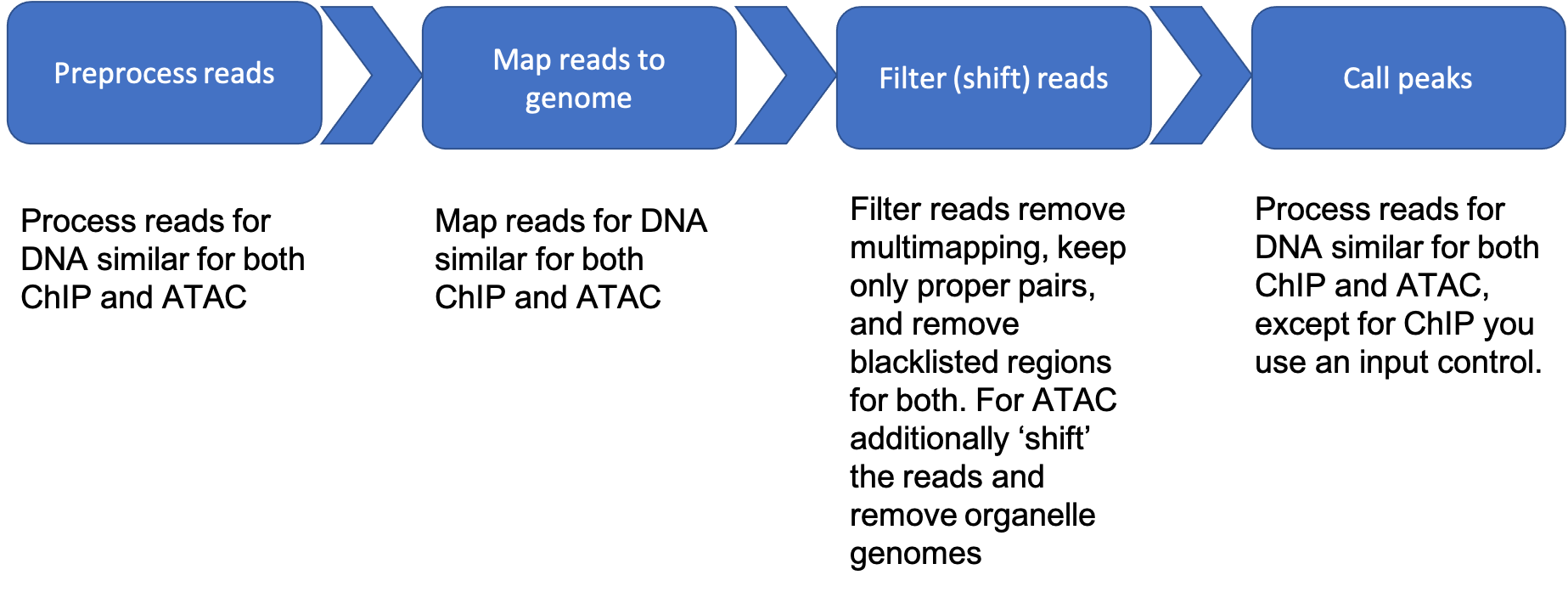
ChIP Seq Dataset
Mouse samples, Methyl-CpG binding protein 2 (MeCP2) 2 Timepoints and 3 replicates.
| Sample | Protein | Timepoint | Rep |
|---|---|---|---|
| JLDY037D | Igg | none | rep1 |
| JLDY037E | MeCP2 | 10_weeks | rep1 |
| JLDY037F | MeCP2 | 10_weeks | rep2 |
| JLDY037G | MeCP2 | 10_weeks | rep3 |
| JLDY037I | MeCP2 | 25_weeks | rep1 |
| JLDY037J | MeCP2 | 25_weeks | rep2 |
| JLDY037K | MeCP2 | 25_weeks | rep3 |
| JLDY037L | Input_mix | none | rep1 |
ChIP Controls
- IgG control (isotype-matched control immunoglobulin): IgG is added instead of MeCP2 antibody but at the same concentration, to give an indication of the assay background.
- Input control: A saved 5-10% of cell lysate before addition of MeCP2 to normalize for variations in starting material between consecutive experiments.
ATAC Seq Dataset
Mouse samples, C57 Strain, 3 treatments and 2 replicates.
| Sample | Strain | Treament | Rep |
|---|---|---|---|
| JLAC003A | C57 | control | rep1 |
| JLAC003B | C57 | single_treatment | rep1 |
| JLAC003C | C57 | double_treatment | rep1 |
| JLAC004D | C57 | control | rep2 |
| JLAC004E | C57 | single_treatment | rep2 |
| JLAC004F | C57 | double_treatment | rep2 |