
To download the Monocle R Markdown document, run:
download.file("https://github.com/ucdavis-bioinformatics-training/2020-Advanced_Single_Cell_RNA_Seq/raw/master/data_analysis/adv_scrnaseq_monocle.Rmd", "adv_scrnaseq_monocle.Rmd")
About Monocle
Monocle, from the Trapnell Lab, is a piece of the TopHat suite that performs differential expression, trajectory, and pseudotime analyses on single cell RNA-Seq data. A very comprehensive tutorial can be found on the Trapnell lab website. We will be using Monocle3, which is still in the beta phase of its development.
library(monocle3, warn.conflicts = FALSE, quietly = TRUE)
library(dplyr, warn.conflicts = FALSE, quietly = TRUE)
download.file("https://github.com/ucdavis-bioinformatics-training/2020-Advanced_Single_Cell_RNA_Seq/raw/master/datasets/monocle3_expression_matrix.rds", "monocle3_expression_matrix.rds")
download.file("https://github.com/ucdavis-bioinformatics-training/2020-Advanced_Single_Cell_RNA_Seq/raw/master/datasets/monocle3_cell_metadata.rds", "monocle3_cell_metadata.rds")
download.file("https://github.com/ucdavis-bioinformatics-training/2020-Advanced_Single_Cell_RNA_Seq/blob/master/datasets/monocle3_gene_metadata.rds?raw=true", "monocle3_gene_metadata.rds")
Setting up monocle3 cell_data_set object
The Bioinformatics Core generally uses Seurat for single cell analysis. In future versions of monocle, direct import from Seurat objects will be supported. We imported data from a Seurat object as three separate objects: an expression matrix, a phenotype data table, and a feature data table.
In order to create the monocle3 cell_data_set object, the expression matrix column names must be identical to the row names of the phenotype data table (cell names), and the expression matrix row names must be identical to the feature data table (gene identifiers).
expression_matrix <- readRDS("monocle3_expression_matrix.rds")
cell_metadata <- readRDS("monocle3_cell_metadata.rds")
gene_metadata <- readRDS("monocle3_gene_metadata.rds")
identical(rownames(cell_metadata), colnames(expression_matrix))
identical(rownames(expression_matrix), gene_metadata$gene_short_name)
cds <- new_cell_data_set(expression_matrix,
cell_metadata = cell_metadata,
gene_metadata = gene_metadata)
Dimension reduction in monocle3
Before doing UMAP and TSNE plots, we will pre-process the data. This step normalizes the data by log and size factor and calculates PCA for dimension reduction.
cds <- preprocess_cds(cds, num_dim = 25)
plot_pc_variance_explained(cds)
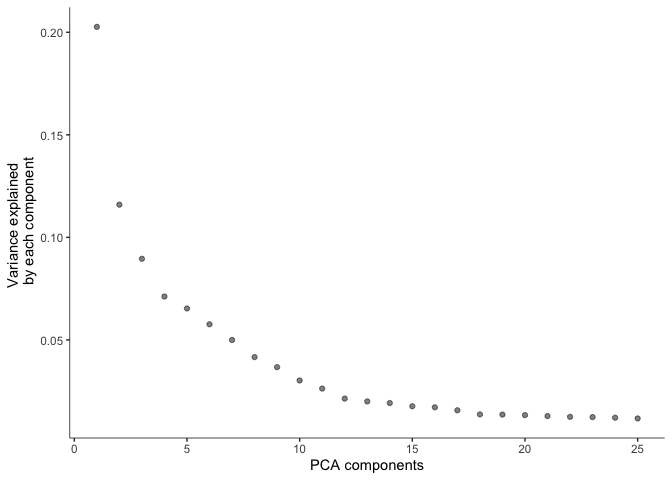
#saveRDS(cds, "monocle3_cds_preprocessed.rds")
The pre-processed data can then be used to perform UMAP and tSNE.
UMAP
cds <- reduce_dimension(cds, preprocess_method = "PCA",
reduction_method = "UMAP")
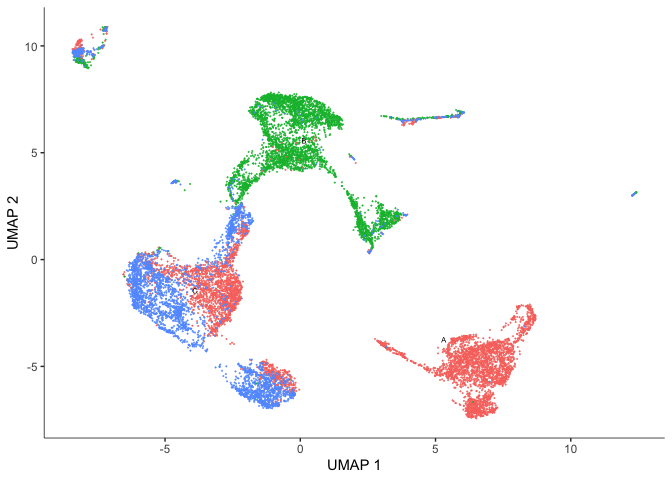
plot_cells(cds, reduction_method = "UMAP",
color_cells_by = "orig.ident",
show_trajectory_graph = FALSE)
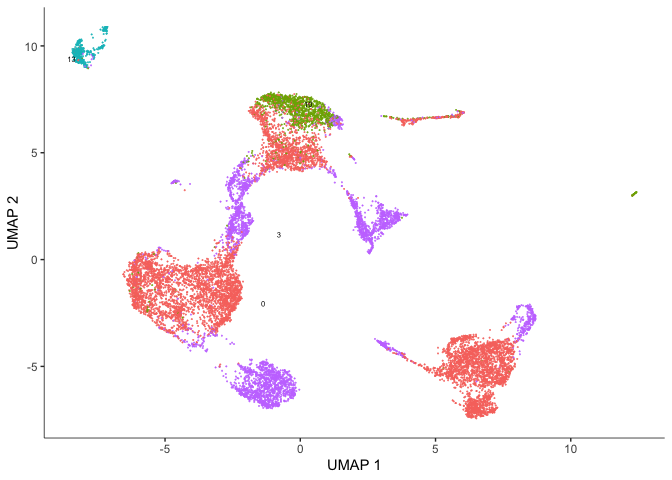
plot_cells(cds, reduction_method = "UMAP", color_cells_by = "res.0.3",
show_trajectory_graph = FALSE)
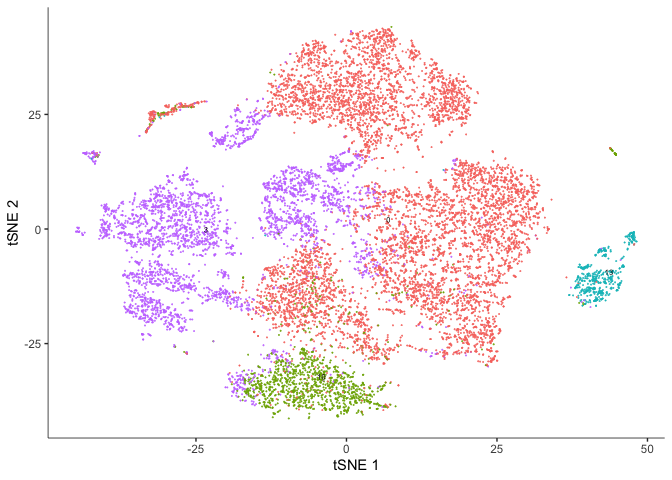
TSNE
cds <- reduce_dimension(cds, preprocess_method = "PCA",
reduction_method="tSNE")
plot_cells(cds, reduction_method="tSNE",
color_cells_by = "res.0.3",
show_trajectory_graph = FALSE)
plot_cells(cds, reduction_method="tSNE",
color_cells_by = "orig.ident",
show_trajectory_graph = FALSE)
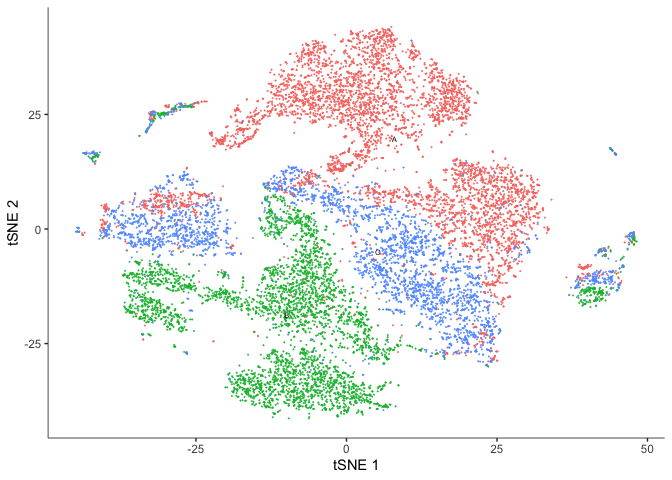
#saveRDS(cds, "monocle3_cds_dimensionreduced.rds")
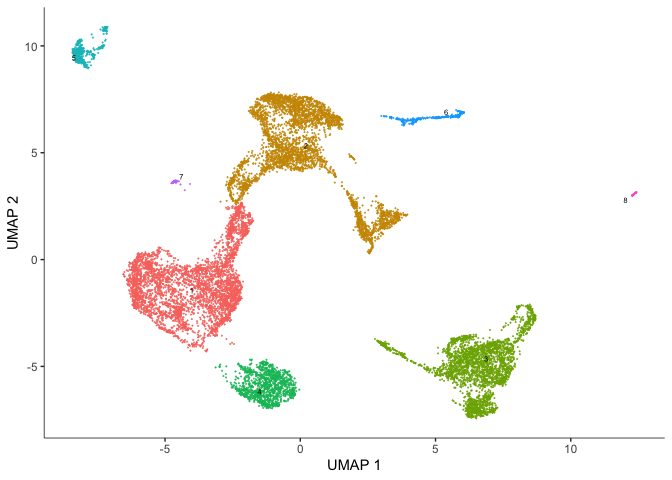
Clustering cells in monocle3
Monocle groups cells into clusters using community detection methods in the function cluster_cells(). Explore the options. Do they impact the number of clusters? The number of partitions?
cds <- cluster_cells(cds, resolution=1e-5)
plot_cells(cds, show_trajectory_graph = FALSE)
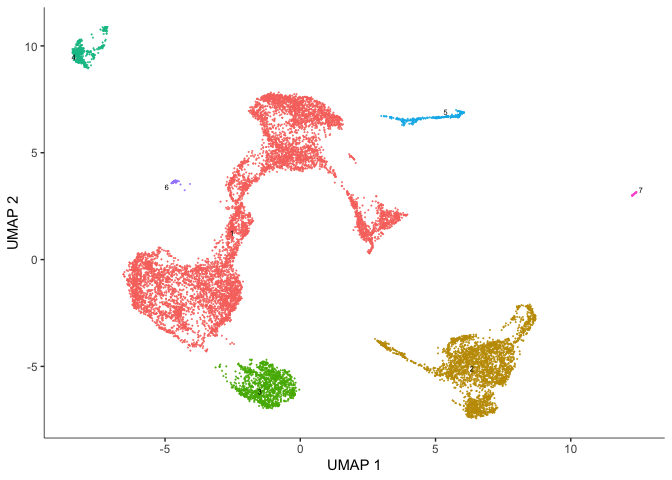
plot_cells(cds, color_cells_by = "partition",
group_cells_by = "partition",
show_trajectory_graph = FALSE)
Identify and plot marker genes for each cluster
Top markers identifies genes that are most specifically expressed in each group of cells. In this case, we are grouping cells by their monocle3 cluster. When marker_sig_test = "TRUE", monocle3 will perform a significance test on the discriminative power of each marker. This may be slow, so we have dedicated several cores to help speed up the process. You may set this number depending on the specifications of your computer. The reference set for the significance test is randomly selected.
marker_test_res <- top_markers(cds,
group_cells_by="cluster",
reduction_method = "UMAP",
marker_sig_test = TRUE,
reference_cells=1000,
cores=8)
head(arrange(marker_test_res, cell_group))
anyDuplicated(marker_test_res$gene_id)
length(which(duplicated(marker_test_res$gene_id)))
duplicate_markers <- names(which(table(marker_test_res$gene_id) > 1))
unique_markers <- marker_test_res[!(marker_test_res$gene_id %in% duplicate_markers),]
head(arrange(unique_markers, cell_group))
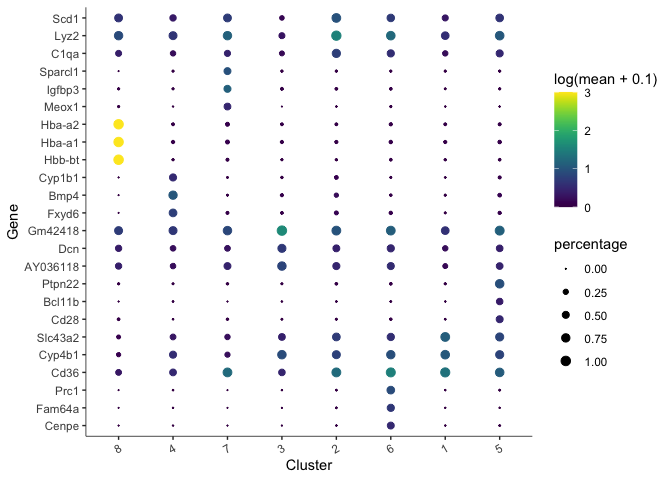
There are too many markers to look at all at once. Let’s limit the number of markers to display on a plot. The plot produced here displays expression level (color) and percentage of cells in which the marker is expressed for each cluster.
top_specific_markers <- unique_markers %>%
filter(fraction_expressing >= 0.10) %>%
group_by(cell_group) %>%
arrange(desc(specificity), .by_group = TRUE) %>%
dplyr::slice(1:3) %>%
pull(gene_id)
plot_genes_by_group(cds,
top_specific_markers,
group_cells_by="cluster",
ordering_type="cluster_row_col",
max.size=3)
We can also plot the expression of a user-defined list of markers (or genes of interest).
markers <- c("Ehd3", "Sdc1", "Fmo2", "Cd3g", "Ccna2", "Hbb-bt")
plot_cells(cds, genes = markers)
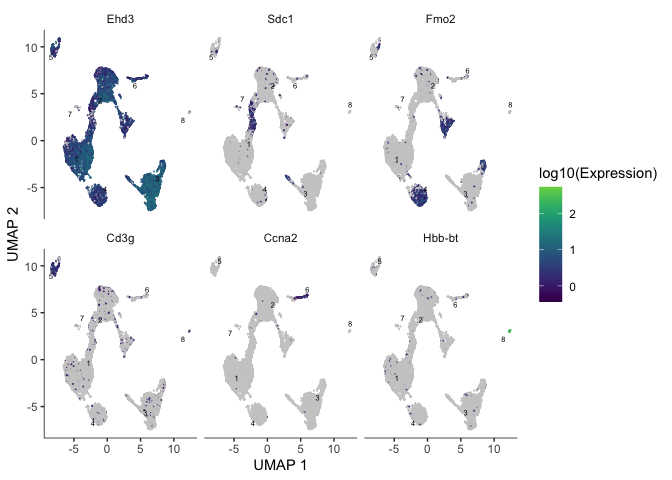
Trajectory analysis
In a dataset like this one, cells were not harvested in a time series, but may not have all been at the same developmental stage. Monocle offers trajectory analysis to model the relationships between groups of cells as a trajectory og gene expression changes. The first step in trajectory analysis is the learn_graph() function.
After learning the graph, monocle can plot add the trajectory graph to the cell plot.
plot_cells(cds,
color_cells_by = "cluster",
label_groups_by_cluster=FALSE,
label_leaves=FALSE,
label_branch_points=FALSE)
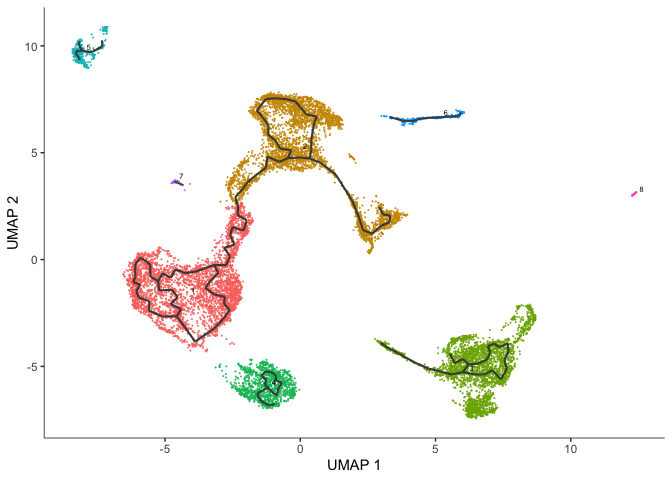
#saveRDS(cds, "monocle3_cds_learngraph.rds")
Not all of our trajectories are connected. In fact, only clusters that belong to the same partition are connected by a trajectory.
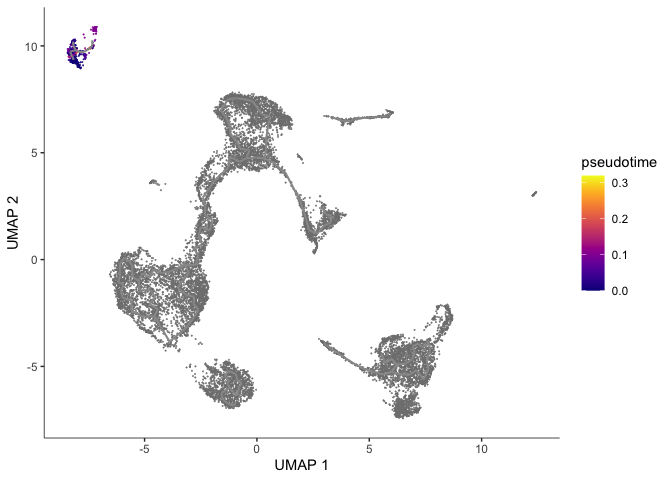
Color cells by pseudotime
We can set the root to any one of our clusters by selecting the cells in that cluster to use as the root in the function order_cells. All cells that cannot be reached from a trajectory with our selected root will be gray, which represents “infinite” pseudotime. Explore each of the trajectories by
root5 <- order_cells(cds, root_cells = colnames(cds[,clusters(cds) == 5]))
plot_cells(root5,
color_cells_by = "pseudotime",
group_cells_by = "cluster",
label_cell_groups = FALSE,
label_groups_by_cluster=FALSE,
label_leaves=FALSE,
label_branch_points=FALSE,
label_roots = FALSE,
trajectory_graph_color = "grey60")
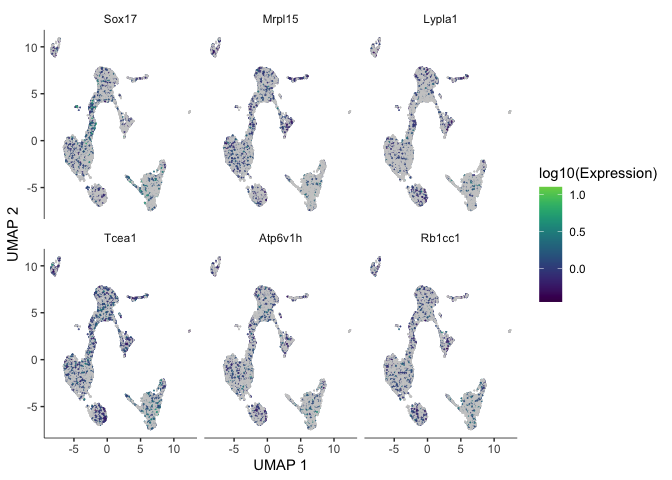
Identify genes that change as a function of pseudotime
Monocle’s graph_test() function detects genes that vary over a trajectory. This may run very slowly. For me, it took roughly 12 minutes. Adjust the number of cores as needed.
cds_graph_test_results <- graph_test(cds,
neighbor_graph = "principal_graph",
cores = 4)
The output of this function is a table. We can look at the expression of someof these genes overlaid on the trajectory plot.
head(cds_graph_test_results)
pr_deg_ids <- row.names(subset(cds_graph_test_results, q_value < 0.05))
plot_cells(cds, genes = head(pr_deg_ids),
show_trajectory_graph = FALSE,
label_cell_groups = FALSE,
label_leaves = FALSE)
We can also calculate modules of co-expressed genes, which we can display as a heatmap or superimpose expression of module genes on the trajectory graph.
# gene modules by cell type
gene_modules <- find_gene_modules(cds[pr_deg_ids,],
resolution=c(10^seq(-6,-1)))
cell_groups <- tibble::tibble(cell=row.names(colData(cds)),
cell_group=colData(cds)$orig.ident)
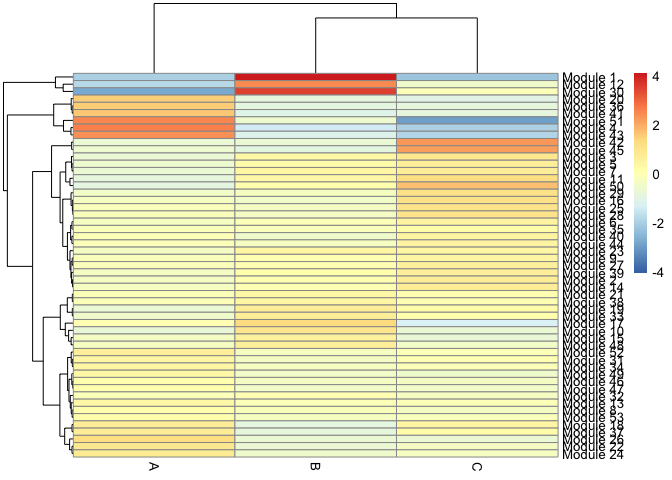
agg_mat <- aggregate_gene_expression(cds, gene_modules, cell_groups)
row.names(agg_mat) <- paste0("Module ", row.names(agg_mat))
pheatmap::pheatmap(agg_mat,
scale="column", clustering_method="ward.D2")
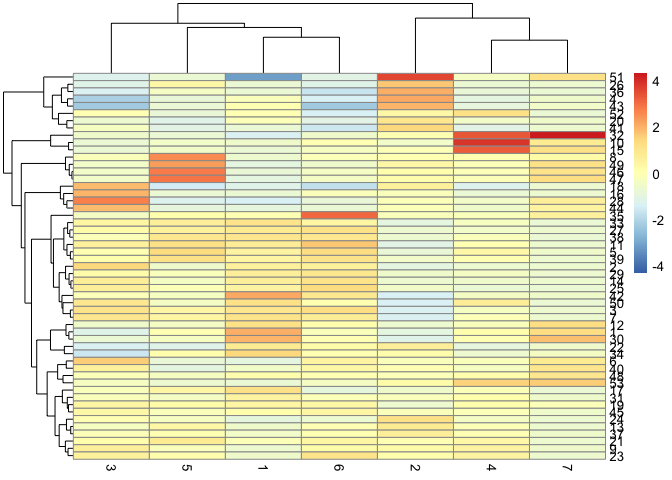
# gene modules by cluster
cluster_groups <- tibble::tibble(cell=row.names(colData(cds)),
cluster_group=cds@clusters$UMAP[[2]])
agg_mat2 <- aggregate_gene_expression(cds, gene_modules, cluster_groups)
row.names(agg_mat) <- paste0("Module ", row.names(agg_mat))
pheatmap::pheatmap(agg_mat2,
scale="column", clustering_method="ward.D2")
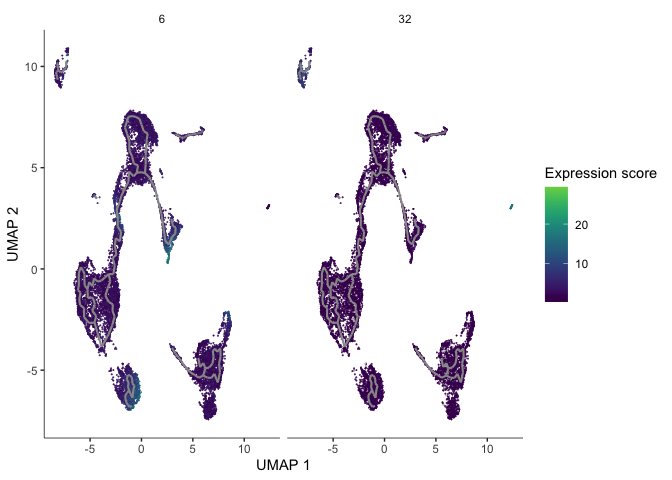
gm <- gene_modules[which(gene_modules$module %in% c(6, 32)),]
plot_cells(cds,
genes=gm,
label_cell_groups=FALSE,
show_trajectory_graph=TRUE,
label_branch_points = FALSE,
label_roots = FALSE,
label_leaves = FALSE,
trajectory_graph_color = "grey60")
R session information
sessionInfo()