Overview
In this section, we will learn how to use the method scAlign to take two separate datasets and “integrate” them, so that cells of the same type (across datasets) roughly fall into the same region of the scatterplots (instead of separating by dataset first). Integration is typically done in a few different scenarios, e.g., 1) if you collect data from across multiple conditions / days / batches / experimentalists / etc. and you want to remove these technical confounders, 2) if you are doing a case control study (as we are here) and you want to identify which cells match across condition, or 3) you have performed an experiment sequencing cells from a tissue (e.g. lung epithelium) and you want to label the cells by type, but you don’t have marker genes available, however, you do have access to a database of annotated cells that you could map onto your dataset.
Here we will perform alignment as if we do not have any labels (case 3), but we will use the labels after alignment to check its accuracy. The following R markdown illustrates how to do integration with scAlign, and aligns two datasets pretty successfully.
This tutorial provides a guided alignment for two groups of cells from Kowalczyk et al, 2015. In this experiment, single cell RNA (scRNA) sequencing profiles were generated from HSCs in young (2-3 mo) and old (>22 mo) C57BL/6 mice. Age related expression programs make a joint analysis of three isolated cell types long-term (LT), short-term (ST) and multipotent progenitors (MPPs). In this tutorial we demonstrate the unsupervised alignment strategy of scAlign described in Johansen et al, 2018 along with typical analysis utilizing the aligned dataset, and show how scAlign can identify and match cell types across age without using the labels as input.
Alignment goals
The following is a walkthrough of a typical alignment problem for scAlign and has been designed to provide an overview of data preprocessing, alignment and finally analysis in our joint embedding space. Here, our primary goals include:
- Learning a low-dimensional cell state space in which cells group by function and type, regardless of condition (age).
- Computing a single cell paired differential expression map from paired cell projections.
First, we perform a typical scRNA preprocessing step using the Seurat package. Then, reduce to the top 3,000 highly variable genes from both datasets to improve convergence and reduce computation time.
## User paths
working.dir = "." #where our data file, kowalcyzk_gene_counts.rda is located
results.dir = "." #where the output should be stored
## Load in data - either option
download.file('https://github.com/quon-titative-biology/examples/raw/master/scAlign_paired_alignment/kowalcyzk_gene_counts.rda','kowalcyzk_gene_counts.rda'); load('kowalcyzk_gene_counts.rda')
#load(url('https://github.com/quon-titative-biology/examples/raw/master/scAlign_paired_alignment/kowalcyzk_gene_counts.rda'))
## Extract age and cell type labels
cell_age = unlist(lapply(strsplit(colnames(C57BL6_mouse_data), "_"), "[[", 1))
cell_type = gsub('HSC', '', unlist(lapply(strsplit(colnames(C57BL6_mouse_data), "_"), "[[", 2)))
## Separate young and old data
young_data = C57BL6_mouse_data[unique(row.names(C57BL6_mouse_data)),which(cell_age == "young")]
old_data = C57BL6_mouse_data[unique(row.names(C57BL6_mouse_data)),which(cell_age == "old")]
## Set up young mouse Seurat object
youngMouseSeuratObj <- CreateSeuratObject(counts = young_data, project = "MOUSE_AGE", min.cells = 0)
youngMouseSeuratObj <- NormalizeData(youngMouseSeuratObj)
youngMouseSeuratObj <- ScaleData(youngMouseSeuratObj, do.scale=T, do.center=T, display.progress = T)
## Set up old mouse Seurat object
oldMouseSeuratObj <- CreateSeuratObject(counts = old_data, project = "MOUSE_AGE", min.cells = 0)
oldMouseSeuratObj <- NormalizeData(oldMouseSeuratObj)
oldMouseSeuratObj <- ScaleData(oldMouseSeuratObj, do.scale=T, do.center=T, display.progress = T)
## Gene selection
youngMouseSeuratObj <- FindVariableFeatures(youngMouseSeuratObj, do.plot = F, nFeature=3000)
oldMouseSeuratObj <- FindVariableFeatures(oldMouseSeuratObj, do.plot = F, nFeature=3000,)
#find the intersection of different variable gene lists
genes.use = Reduce(intersect, list(VariableFeatures(youngMouseSeuratObj),
VariableFeatures(oldMouseSeuratObj),
rownames(youngMouseSeuratObj),
rownames(oldMouseSeuratObj)))
#[FUTURE] ComBat and Seurat (regress) batch correction results.
Is alignment necessary?
Let’s visualize the data from both young and old mice, to determine whether we need alignment/batch correction.
## Combine our Seurat objects
hsc.combined <- merge(youngMouseSeuratObj, oldMouseSeuratObj, add.cell.ids = c("YOUNG", "OLD"), project = "HSC")
hsc.combined <- ScaleData(hsc.combined, do.scale=T, do.center=T, display.progress = T)
VariableFeatures(hsc.combined) = genes.use
## Run PCA and TSNE
hsc.combined = RunPCA(hsc.combined, do.print=FALSE)
hsc.combined = RunTSNE(hsc.combined, dims.use = 1:30, max_iter=2000)
#get cell type
celltypes = rownames(hsc.combined@meta.data)
celltypes[grep('MPP',celltypes)]='MPP'; celltypes[grep('ST_HSC',celltypes)]='ST_HSC'; celltypes[grep('LT_HSC',celltypes)]='LT_HSC'; celltypes=factor(celltypes);
## Plot tsne results
plot.me <- data.frame(x=hsc.combined@reductions$tsne@cell.embeddings[,1],
y=hsc.combined@reductions$tsne@cell.embeddings[,2],
labels=Idents(hsc.combined),
celltypes=celltypes,
stringsAsFactors=FALSE)
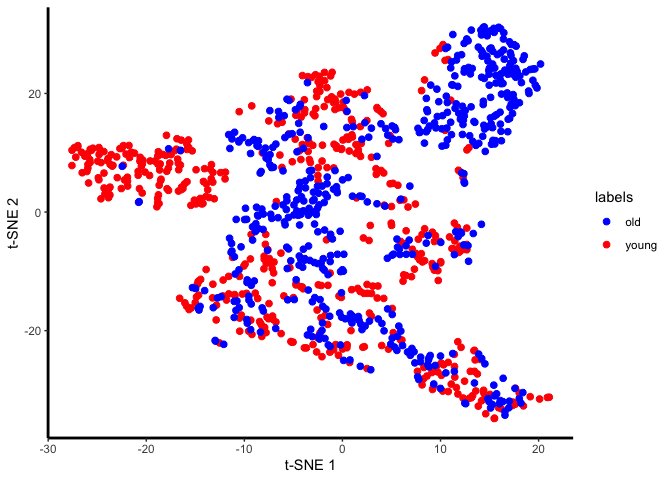
unaligned.plot <- ggplot(plot.me, aes(x=x, y=y, colour = labels)) +
geom_point(size=2) +
scale_colour_manual(values=c("blue", "red")) +
xlab('t-SNE 1') +
ylab('t-SNE 2') +
theme_bw() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "transparent"), # bg of the panel
plot.background = element_rect(fill = "transparent", color = NA),
axis.line = element_line(colour = 'black',size=1))
plot(unaligned.plot)
unaligned.plot <- ggplot(plot.me, aes(x=x, y=y, colour = celltypes)) +
geom_point(size=2) +
scale_colour_manual(values=c("blue", "red","green")) +
xlab('t-SNE 1') +
ylab('t-SNE 2') +
theme_bw() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "transparent"), # bg of the panel
plot.background = element_rect(fill = "transparent", color = NA),
axis.line = element_line(colour = 'black',size=1))
plot(unaligned.plot)
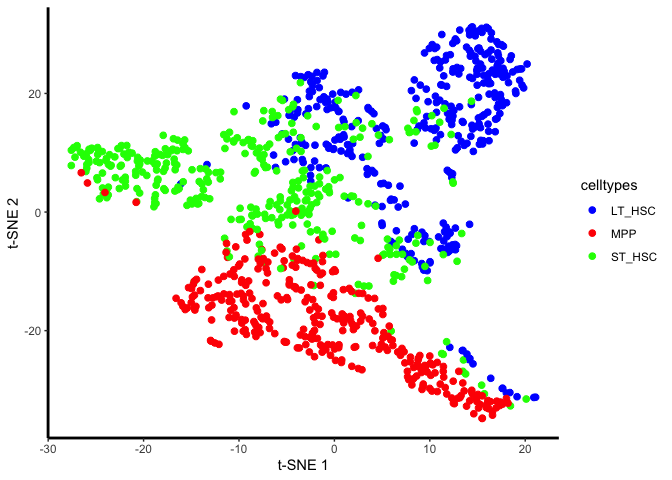
Yes, there are definitely condition-specific clusters of cells in the tSNE, so we will go ahead with alignment.
scAlign setup
The general design of scAlign makes it agnostic to the input RNA-seq data representation. Thus, the input data can either be
gene-level counts, transformations of those gene level counts or a preliminary step of dimensionality reduction such
as canonical correlates or principal component scores. Here we create the scAlign object from the previously defined
Seurat objects and perform both PCA and CCA on the unaligned data.
## Create paired dataset SCE objects to pass into scAlignCreateObject
youngMouseSCE <- SingleCellExperiment(
assays = list(counts = youngMouseSeuratObj@assays$RNA@counts[genes.use,],
logcounts = youngMouseSeuratObj@assays$RNA@data[genes.use,],
scale.data = youngMouseSeuratObj@assays$RNA@scale.data[genes.use,])
)
oldMouseSCE <- SingleCellExperiment(
assays = list(counts = oldMouseSeuratObj@assays$RNA@counts[genes.use,],
logcounts = oldMouseSeuratObj@assays$RNA@data[genes.use,],
scale.data = oldMouseSeuratObj@assays$RNA@scale.data[genes.use,])
)
We now build the scAlign SCE object and compute PCs and/or CCs using Seurat for the assay defined by data.use. It is assumed that data.use, which is being used for the initial step of dimensionality reduction, is properly normalized and scaled.
Resulting combined matrices will always be ordered based on the sce.objects list order.
scAlignHSC = scAlignCreateObject(sce.objects = list("YOUNG"=youngMouseSCE, "OLD"=oldMouseSCE),
labels = list(cell_type[which(cell_age == "young")], cell_type[which(cell_age == "old")]),
data.use="scale.data",
pca.reduce = TRUE,
pcs.compute = 50,
cca.reduce = TRUE,
ccs.compute = 15,
project.name = "scAlign_Kowalcyzk_HSC")
Alignment of young and old HSCs
Now we align the young and old cpopulations for multiple input types which are specified by encoder.data. scAlign returns a
low-dimensional joint embedding space where the effect of age is removed allowing us to use the complete dataset for downstream analyses such as clustering or differential expression. For the gene level input we also run the decoder procedure which projects each cell into logcount space for both conditions to perform paired single cell differential expressional.
## Run scAlign with high_var_genes as input to the encoder (alignment) and logcounts with the decoder (projections).
scAlignHSC = scAlign(scAlignHSC,
options=scAlignOptions(steps=3000, steps.decoder=500, log.every=100, norm=TRUE, batch.norm.layer=TRUE, early.stop=FALSE, architecture="small"),
encoder.data="scale.data",
decoder.data="logcounts",
supervised='none',
run.encoder=TRUE,
run.decoder=TRUE,
log.dir=file.path(results.dir, 'models','gene_input'),
device="CPU")
## Additional run of scAlign with PCA, the early.stopping heuristic terminates the training procedure too early with PCs as input so it is disabled.
# scAlignHSC = scAlign(scAlignHSC,
# options=scAlignOptions(steps=500, log.every=100, norm=TRUE, batch.norm.layer=TRUE, early.stop=FALSE),
# encoder.data="PCA",
# supervised='none',
# run.encoder=TRUE,
# run.decoder=FALSE,
# log.dir=file.path(results.dir, 'models','pca_input'),
# device="CPU")
#
# ## Additional run of scAlign with CCA
# scAlignHSC = scAlign(scAlignHSC,
# options=scAlignOptions(steps=500, log.every=100, norm=TRUE, batch.norm.layer=TRUE, early.stop=TRUE),
# encoder.data="CCA",
# supervised='none',
# run.encoder=TRUE,
# run.decoder=FALSE,
# log.dir=file.path(results.dir, 'models','cca_input'),
# device="CPU")
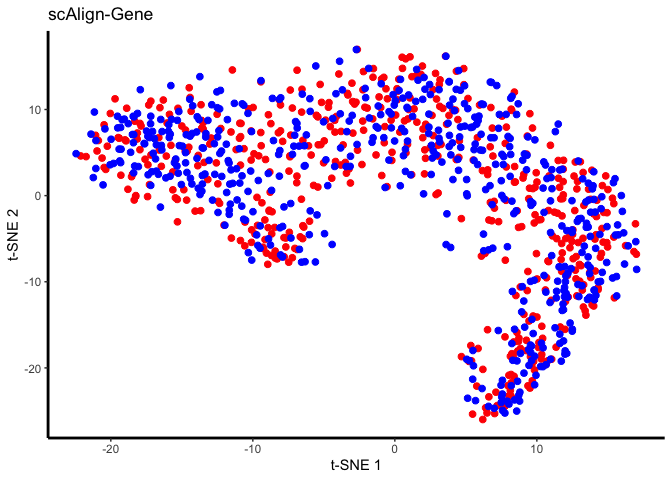
Now visualize:
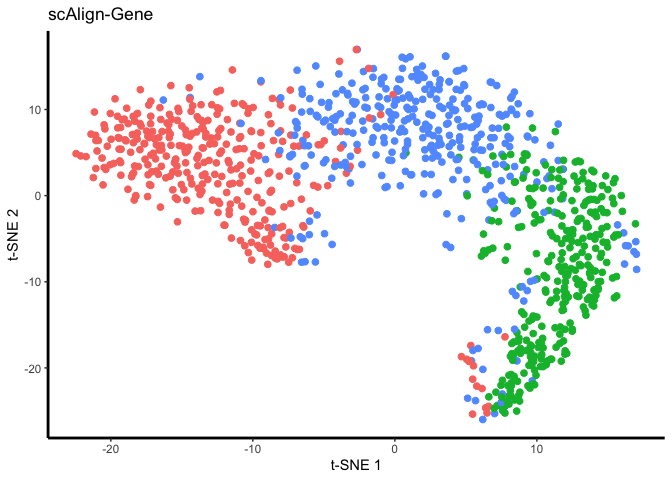
## Plot aligned data in tSNE space, when the data was processed in three different ways: 1) either using the original gene inputs, 2) after PCA dimensionality reduction for preprocessing, or 3) after CCA dimensionality reduction for preprocessing. Cells here are colored by input labels
set.seed(5678)
#try changing the line below to "ALIGNED-PCA" or "ALIGNED-CCA" to check how alignment using just PCs or CCAs worked
DATA_TO_PLOT = 'ALIGNED-GENE';
tsne.res = Rtsne(reducedDim(scAlignHSC, "ALIGNED-GENE"), perplexity=30)
plot.me <- data.frame(x=tsne.res$Y[,1],
y=tsne.res$Y[,2],
labels=as.character(colData(scAlignHSC)[,"scAlign.labels"]),
stringsAsFactors=FALSE)
gene_plot <- ggplot(plot.me, aes(x=x, y=y, colour = labels)) +
geom_point(size=2) +
#scale_colour_manual(values=c("blue", "red")) +
xlab('t-SNE 1') +
ylab('t-SNE 2') +
ggtitle("scAlign-Gene") +
theme_bw() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "transparent"), # bg of the panel
plot.background = element_rect(fill = "transparent", color = NA),
legend.position="none",
axis.line = element_line(colour = 'black',size=1))
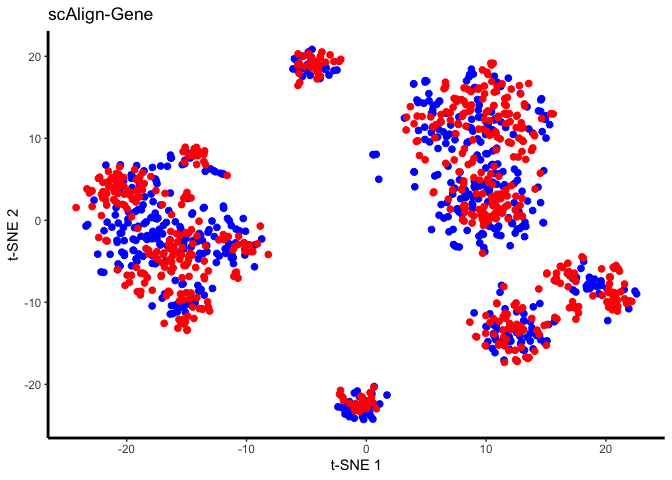
plot(gene_plot);
set.seed(5678)
tsne.res = Rtsne(reducedDim(scAlignHSC, "ALIGNED-GENE"), perplexity=30)
plot.me <- data.frame(x=tsne.res$Y[,1],
y=tsne.res$Y[,2],
labels=as.character(colData(scAlignHSC)[,"group.by"]),
stringsAsFactors=FALSE)
gene_plot <- ggplot(plot.me, aes(x=x, y=y, colour = labels)) +
geom_point(size=2) +
scale_colour_manual(values=c("blue", "red")) +
xlab('t-SNE 1') +
ylab('t-SNE 2') +
ggtitle("scAlign-Gene") +
theme_bw() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "transparent"), # bg of the panel
plot.background = element_rect(fill = "transparent", color = NA),
legend.position="none",
axis.line = element_line(colour = 'black',size=1))
plot(gene_plot);
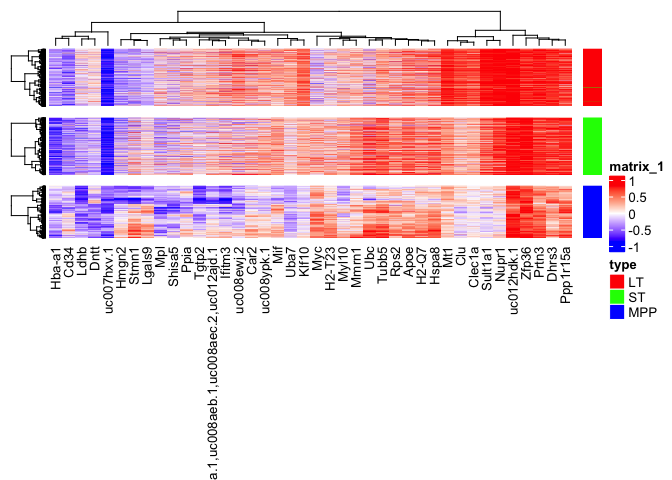
Paired differential expression of young and old cells.
Since we have run the decoder for “ALIGNED-GENE” alignment we can also investigate the paired differential of cells with respect to the young and old conditions. The projections are saved as “YOUNG2OLD” and “OLD2YOUNG” in scAlignHSC reducededDims. “YOUNG2OLD” indicates the projection of young cells into the expression space of old cells. As a reminder the combined matrices are always in the order of the sce.objects list passed to scAlignCreateObject.
library(ComplexHeatmap)
library(circlize)
all_data_proj_2_old = reducedDim(scAlignHSC, "YOUNG2OLD")
all_data_proj_2_young = reducedDim(scAlignHSC, "OLD2YOUNG")
scDExpr = all_data_proj_2_old - all_data_proj_2_young
colnames(scDExpr) <- genes.use
## Identify most variant DE genes
gene_var <- apply(scDExpr,2,var)
high_var_genes <- sort(gene_var, decreasing=T, index.return=T)$ix[1:40]
## Subset to top variable genes
scDExpr = scDExpr[,high_var_genes]
## Cluster each cell type individually
hclust_LT <- as.dendrogram(hclust(dist(scDExpr[which(cell_type == "LT"),], method = "euclidean"), method="ward.D2"))
hclust_ST <- as.dendrogram(hclust(dist(scDExpr[which(cell_type == "ST"),], method = "euclidean"), method="ward.D2"))
hclust_MPP <- as.dendrogram(hclust(dist(scDExpr[which(cell_type == "MPP"),], method = "euclidean"), method="ward.D2"))
clustering <- merge(hclust_ST, hclust_LT)
clustering <- merge(clustering, hclust_MPP)
## Reorder based on cluster groups
reorder = c(which(cell_type == "LT"), which(cell_type == "ST"), which(cell_type == "MPP"))
## Colors for ComplexHeatmap annotation
cell_type_colors = c("red", "green", "blue")
names(cell_type_colors) = unique(cell_type)
ha = rowAnnotation(df = data.frame(type=cell_type[reorder]),
col = list(type = cell_type_colors),
na_col = "white")
#png(file.path(results.dir,"scDExpr_heatmap.png"), width=28, height=12, units='in', res=150, bg="transparent")
Heatmap(as.matrix(scDExpr[reorder,]),
col = colorRamp2(c(-0.75, 0, 0.75), c('blue', 'white', 'red')),
row_dend_width = unit(1, "cm"),
column_dend_height = unit(1, "cm"),
cluster_columns = TRUE,
cluster_rows = clustering,
row_dend_reorder=FALSE,
show_row_names = FALSE,
show_column_names = TRUE,
na_col = 'white',
column_names_gp = gpar(fontsize = 10),
split=3,
gap = unit(0.3, "cm")) + ha
#dev.off()
Discussion points
When does alignment work well? Statistical significance? When does alignment make sense? How do you know when alignment makes sense?
More reading
For a larger list of alignment methods, as well as an evaluation of them, see our scAlign paper here: https://genomebiology.biomedcentral.com/articles/10.1186/s13059-019-1766-4. As a side note, some of the benefits of scAlign compared to most other methods include:
- ability to ‘project’ data from aligned space back to UMI/count space (for post-analysis).
- ability to use partial labeling of cells to improve alignment - e.g. suppose only some cells can be labeled using high confidence markers.
Try human-mouse alignment
Now try aligning human and mouse cortex cells (data from Hodge et al., 2019, Nature). Briefly, inhibitory neurons, excitatory neurons, and glial cells were sequenced across human and mouse cortex, and the goal of the study in part is to identify which cell types and genes expression patterns differ across the two species.
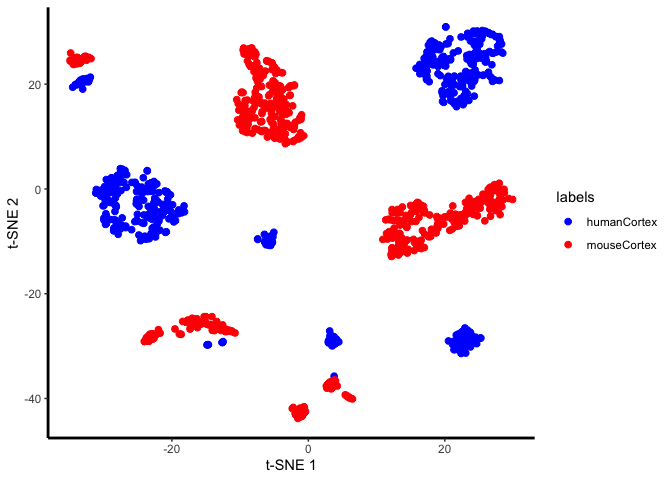
First, we’ll visualize the data to check for a “species” effect:
working.dir = "." #where our data file, kowalcyzk_gene_counts.rda is located
results.dir = "." #where the output should be stored
download.file('https://github.com/quon-titative-biology/examples/raw/master/scAlign_paired_alignment/hodges_2019_subset.rdata','hodges_2019_subset.rdata');
load('hodges_2019_subset.rdata')
cortex.combined <- merge(humanCortex, mouseCortex, add.cell.ids = c("human", "mouse"), project = "cortex")
cortex.combined <- ScaleData(cortex.combined, do.scale=T, do.center=T, display.progress = T)
VariableFeatures(cortex.combined) = rownames(humanCortex)
genes.use = rownames(humanCortex)
## Run PCA and TSNE
cortex.combined = RunPCA(cortex.combined, do.print=FALSE)
cortex.combined = RunTSNE(cortex.combined, dims.use = 1:30, max_iter=2000)
#get cell type - can use the subtype variable as well
celltypes = cortex.combined@meta.data$type;
## Plot tsne results
plot.me <- data.frame(x=cortex.combined@reductions$tsne@cell.embeddings[,1],
y=cortex.combined@reductions$tsne@cell.embeddings[,2],
labels=Idents(cortex.combined),
celltypes=celltypes,
stringsAsFactors=FALSE)
unaligned.plot <- ggplot(plot.me, aes(x=x, y=y, colour = labels)) +
geom_point(size=2) +
scale_colour_manual(values=c("blue", "red")) +
xlab('t-SNE 1') +
ylab('t-SNE 2') +
theme_bw() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "transparent"), # bg of the panel
plot.background = element_rect(fill = "transparent", color = NA),
axis.line = element_line(colour = 'black',size=1))
plot(unaligned.plot)
unaligned.plot <- ggplot(plot.me, aes(x=x, y=y, colour = celltypes)) +
geom_point(size=2) +
#scale_colour_manual(values=c("blue", "red","green")) +
xlab('t-SNE 1') +
ylab('t-SNE 2') +
theme_bw() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "transparent"), # bg of the panel
plot.background = element_rect(fill = "transparent", color = NA),
axis.line = element_line(colour = 'black',size=1))
plot(unaligned.plot)
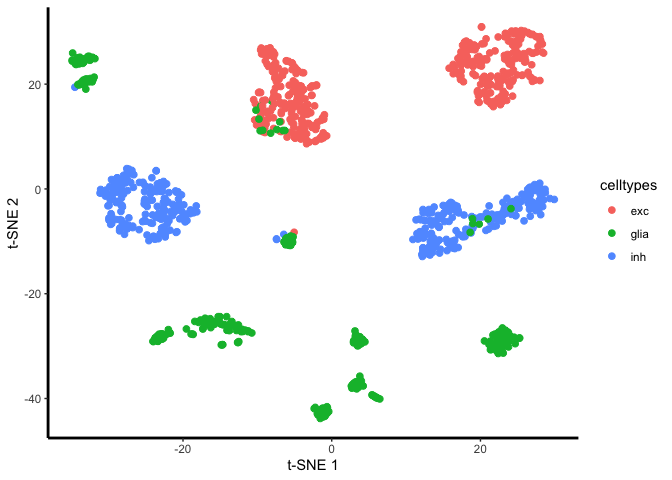
Yes, there is a species effect. So now we’ll align the two species:
library(scAlign)
library(Seurat)
library(SingleCellExperiment)
library(gridExtra)
library(cowplot)
## Create paired dataset SCE objects to pass into scAlignCreateObject
humanSCE <- SingleCellExperiment(
assays = list(counts = humanCortex@assays$RNA@counts[genes.use,],
logcounts = humanCortex@assays$RNA@data[genes.use,],
scale.data = humanCortex@assays$RNA@scale.data[genes.use,])
)
mouseSCE <- SingleCellExperiment(
assays = list(counts = mouseCortex@assays$RNA@counts[genes.use,],
logcounts = mouseCortex@assays$RNA@data[genes.use,],
scale.data = mouseCortex@assays$RNA@scale.data[genes.use,])
)
scAlignCortex = scAlignCreateObject(sce.objects = list("human"=humanSCE, "mouse"=mouseSCE),
labels = list(celltypes[which(cortex.combined@meta.data$stim == "human")], celltypes[which(cortex.combined@meta.data$stim == "mouse")]),
data.use="scale.data",
pca.reduce = TRUE,
pcs.compute = 50,
cca.reduce = TRUE,
ccs.compute = 15,
project.name = "hodges_2019")
scAlignCortex = scAlign(scAlignCortex,
options=scAlignOptions(steps=500, steps.decoder=500, log.every=100, norm=TRUE, batch.norm.layer=TRUE, early.stop=FALSE, architecture="small"),
encoder.data="scale.data",
decoder.data="logcounts",
supervised='none',
run.encoder=TRUE,
run.decoder=TRUE,
log.dir=file.path(results.dir, 'models','gene_input'),
device="CPU")
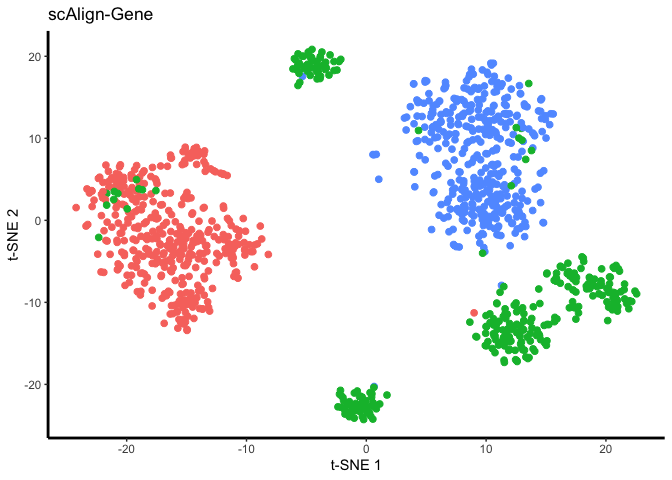
And finally, we will visualize the result.
set.seed(5678)
#try changing the line below to "ALIGNED-PCA" or "ALIGNED-CCA" to check how alignment using just PCs or CCAs worked
## Plot tsne results for gene alignment
tsne.res = Rtsne(reducedDim(scAlignCortex, "ALIGNED-GENE"), perplexity=30)
plot.me <- data.frame(x=tsne.res$Y[,1],
y=tsne.res$Y[,2],
labels=as.character(colData(scAlignCortex)[,"scAlign.labels"]),
stringsAsFactors=FALSE)
gene_plot <- ggplot(plot.me, aes(x=x, y=y, colour = labels)) +
geom_point(size=2) +
#scale_colour_manual(values=c("blue", "red")) +
xlab('t-SNE 1') +
ylab('t-SNE 2') +
ggtitle("scAlign-Gene") +
theme_bw() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "transparent"), # bg of the panel
plot.background = element_rect(fill = "transparent", color = NA),
legend.position="none",
axis.line = element_line(colour = 'black',size=1))
plot(gene_plot)
set.seed(5678)
tsne.res = Rtsne(reducedDim(scAlignCortex, "ALIGNED-GENE"), perplexity=30)
plot.me <- data.frame(x=tsne.res$Y[,1],
y=tsne.res$Y[,2],
labels=as.character(colData(scAlignCortex)[,"group.by"]),
stringsAsFactors=FALSE)
gene_plot <- ggplot(plot.me, aes(x=x, y=y, colour = labels)) +
geom_point(size=2) +
scale_colour_manual(values=c("blue", "red")) +
xlab('t-SNE 1') +
ylab('t-SNE 2') +
ggtitle("scAlign-Gene") +
theme_bw() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "transparent"), # bg of the panel
plot.background = element_rect(fill = "transparent", color = NA),
legend.position="none",
axis.line = element_line(colour = 'black',size=1))
plot(gene_plot);