
About Monocle
Monocle, from the Trapnell Lab, is a piece of the TopHat suite that performs differential expression, trajectory, and pseudotime analyses on single cell RNA-Seq data. A very comprehensive tutorial can be found on the Trapnell lab website. We will be using Monocle3, which is still in the beta phase of its development.
library(monocle3)
library(dplyr)
Setting up monocle3 cell_data_set object
The data used in this analysis represent a subset of both samples and clusters from a larger experiment analyzed in Seurat. The long original identity strings have been overwritten with “A,” “B,” and “C” for the sake of simplicity.
In future versions of monocle, direct import from Seurat objects will be supported. We will import data from a Seurat object as three separate objects: an expression matrix, a phenotype data table, and a feature data table.
expression_matrix <- readRDS("monocle3_expression_matrix.rds")
cell_metadata <- readRDS("monocle3_cell_metadata.rds")
gene_metadata <- readRDS("monocle3_gene_metadata.rds")
In order to create the monocle3 cell_data_set object, the expression matrix column names must be identical to the row names of the phenotype data table (cell names), and the expression matrix row names must be identical to the feature data table (gene identifiers).
identical(rownames(cell_metadata), colnames(expression_matrix))
identical(rownames(expression_matrix), gene_metadata$gene_short_name)
cds <- new_cell_data_set(expression_matrix,
cell_metadata = cell_metadata,
gene_metadata = gene_metadata)
rm(cell_metadata, expression_matrix, gene_metadata)
Dimension reduction in monocle3
Before doing UMAP and TSNE plots, we will pre-process the data. This step normalizes the data by log and size factor and calculates PCA for dimension reduction.
cds <- preprocess_cds(cds, num_dim = 25)
plot_pc_variance_explained(cds)
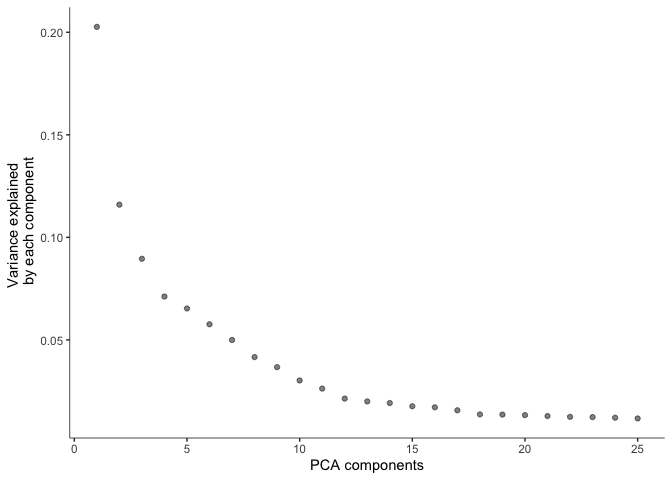
The pre-processed data can then be used to perform UMAP and tSNE.
UMAP
This experiment has already been through clustering in Seurat, and retains the Seurat cluster metadata as “res.0.3.”
cds <- reduce_dimension(cds,
preprocess_method = "PCA",
reduction_method = "UMAP")
plot_cells(cds,
reduction_method = "UMAP",
color_cells_by = "orig.ident",
group_label_size = 3,
show_trajectory_graph = FALSE)
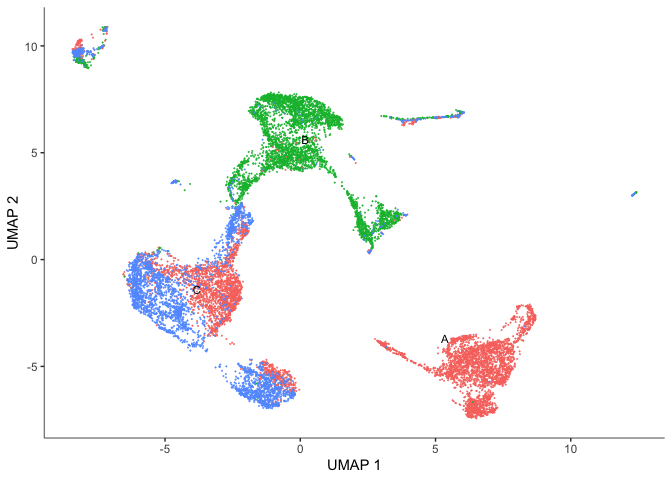
plot_cells(cds,
reduction_method = "UMAP",
color_cells_by = "res.0.3",
group_label_size = 3,
show_trajectory_graph = FALSE)
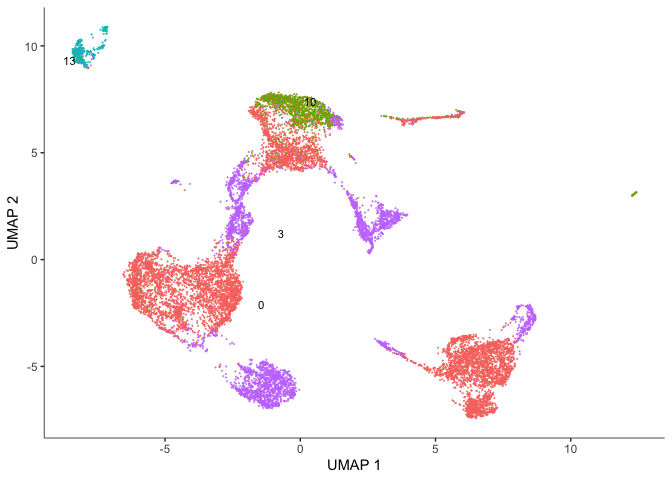
One thing we can observe here is that our Seurat clusters are a bit less contiguous that we might expect on our UMAP plot.
TSNE
We can simply choose whichever is more easily interpreted and better helps us understand and tell the story of our experiment.
cds <- reduce_dimension(cds,
preprocess_method = "PCA",
reduction_method="tSNE")
plot_cells(cds,
reduction_method="tSNE",
color_cells_by = "res.0.3",
group_label_size = 3,
show_trajectory_graph = FALSE)
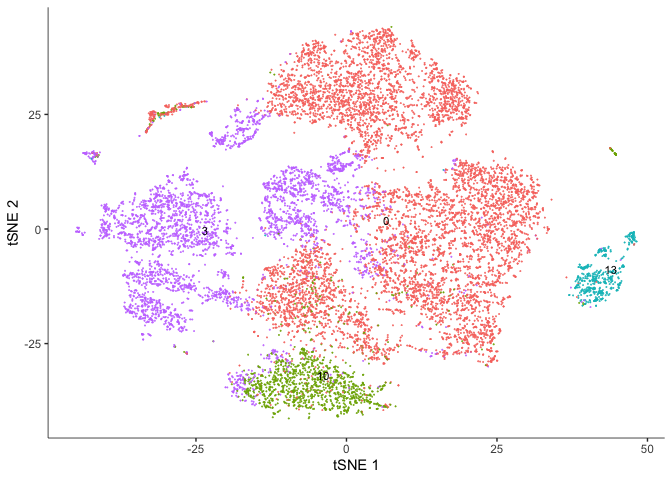
plot_cells(cds,
reduction_method="tSNE",
color_cells_by = "orig.ident",
group_label_size = 3,
show_trajectory_graph = FALSE)
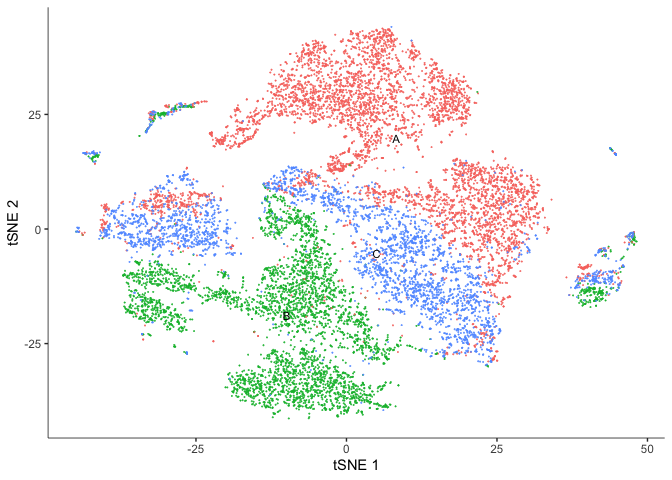
The Seurat clusters look a bit more contiguous when displayed on the tSNE plot. Use whichever you prefer for the remainder of the analysis.
Clustering cells in monocle3
Monocle groups cells into clusters using community detection methods in the function cluster_cells(). Explore the options. Do they impact the number of clusters? The number of partitions?
cds <- cluster_cells(cds, resolution=1e-5)
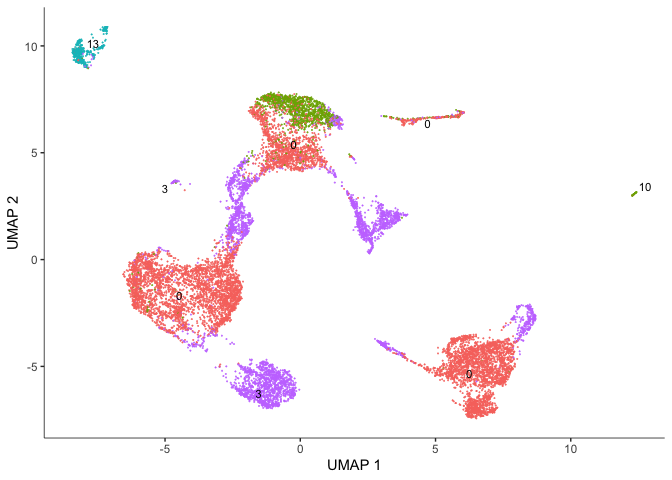
# Seurat clusters
plot_cells(cds,
reduction_method = "UMAP",
color_cells_by = "res.0.3",
group_label_size = 3,
show_trajectory_graph = FALSE)
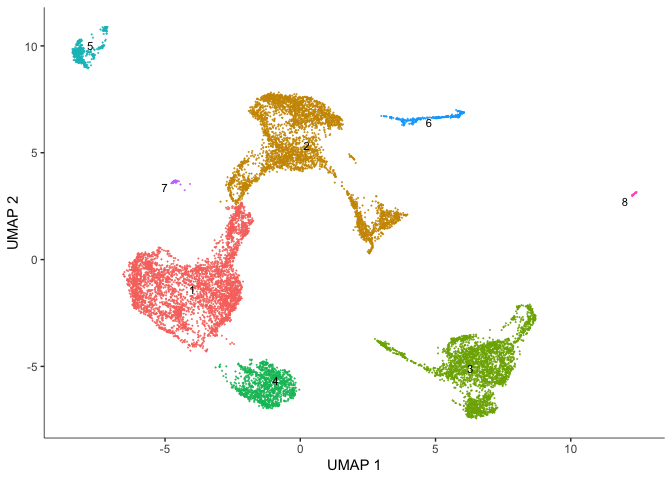
# Monocle clusters
plot_cells(cds,
reduction_method = "UMAP",
color_cells_by = "cluster",
group_label_size = 3,
show_trajectory_graph = FALSE)
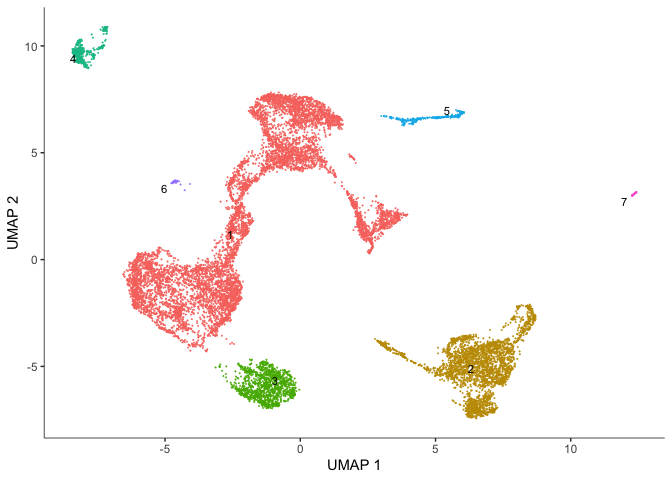
In addition to clusters, monocle produces partitions, which are larger well-separated groups.
plot_cells(cds,
reduction_method = "UMAP",
color_cells_by = "partition",
group_cells_by = "partition",
group_label_size = 3,
show_trajectory_graph = FALSE)
Identify and plot marker genes for each cluster
Top markers identifies genes that are most specifically expressed in each group of cells. In this case, we are grouping cells by their monocle3 cluster. When marker_sig_test = "TRUE", monocle3 will perform a significance test on the discriminative power of each marker. This may be slow, so we have dedicated several cores to help speed up the process. You may set this number depending on the specifications of your computer. The reference set for the significance test is randomly selected.
marker_test_res <- top_markers(cds,
group_cells_by="cluster",
reduction_method = "UMAP",
marker_sig_test = TRUE,
reference_cells=1000,
cores=8)
Once monocle has identified markers, we can explore the results and take a look at the genes identified. For example, how many marker genes were identified? Are any of the genes markers for more than one cluster?
head(marker_test_res)
dim(marker_test_res)
length(which(duplicated(marker_test_res$gene_id)))
duplicate_markers <- names(which(table(marker_test_res$gene_id) > 1))
head(marker_test_res[marker_test_res$gene_id %in% duplicate_markers,])
unique_markers <- marker_test_res[!(marker_test_res$gene_id %in% duplicate_markers),]
head(unique_markers)
rm(marker_test_res, duplicate_markers)
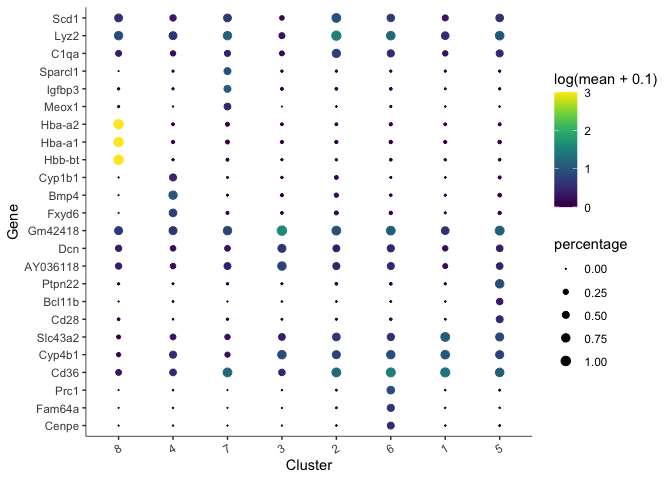
There are too many markers to look at all at once. Let’s limit the number of markers to display on a plot. The plot produced here displays expression level (color) and percentage of cells in which the marker is expressed for each cluster.
top_specific_markers <- unique_markers %>%
filter(fraction_expressing >= 0.10) %>%
group_by(cell_group) %>%
arrange(desc(specificity), .by_group = TRUE) %>%
dplyr::slice(1:3) %>%
pull(gene_id)
plot_genes_by_group(cds,
top_specific_markers,
group_cells_by="cluster",
ordering_type="cluster_row_col",
max.size=3)
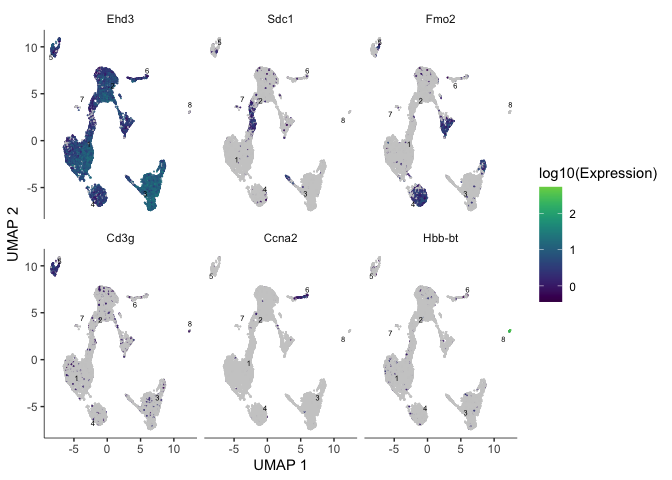
We can also plot the expression of a user-defined list of markers (or genes of interest).
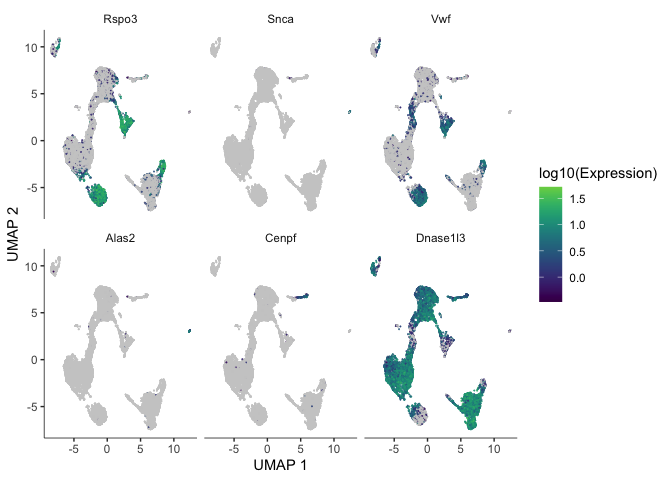
markers <- c("Ehd3", "Sdc1", "Fmo2", "Cd3g", "Ccna2", "Hbb-bt")
plot_cells(cds, genes = markers)
Trajectory analysis
In a data set like this one, cells were not harvested in a time series, but may not have all been at the same developmental stage. Monocle offers trajectory analysis to model the relationships between groups of cells as a trajectory of gene expression changes. The first step in trajectory analysis is the learn_graph() function. This may be time consuming.
cds <- learn_graph(cds, use_partition = TRUE, verbose = FALSE)
After learning the graph, monocle can plot add the trajectory graph to the cell plot.
plot_cells(cds,
color_cells_by = "cluster",
label_groups_by_cluster=FALSE,
label_leaves=FALSE,
label_branch_points=FALSE)
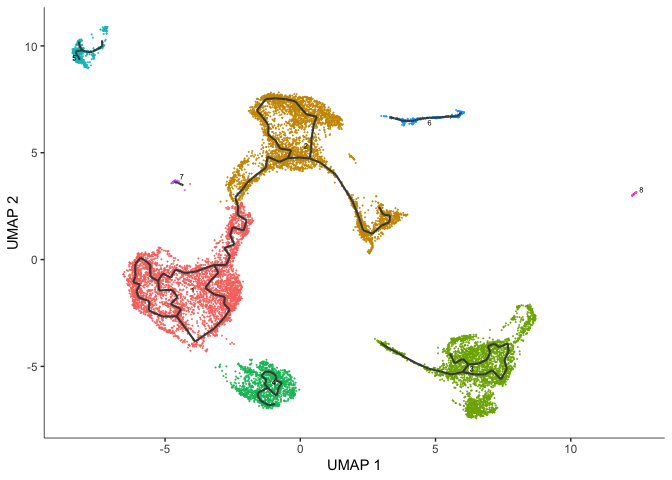
Not all of our trajectories are connected. In fact, only clusters that belong to the same partition are connected by a trajectory.
Color cells by pseudotime
We can set the root to any one of our clusters by selecting the cells in that cluster to use as the root in the function order_cells. All cells that cannot be reached from a trajectory with our selected root will be gray, which represents “infinite” pseudotime.
root5 <- order_cells(cds, root_cells = colnames(cds[,clusters(cds) == 5]))
plot_cells(root5,
color_cells_by = "pseudotime",
group_cells_by = "cluster",
label_cell_groups = FALSE,
label_groups_by_cluster=FALSE,
label_leaves=FALSE,
label_branch_points=FALSE,
label_roots = FALSE,
trajectory_graph_color = "grey60")
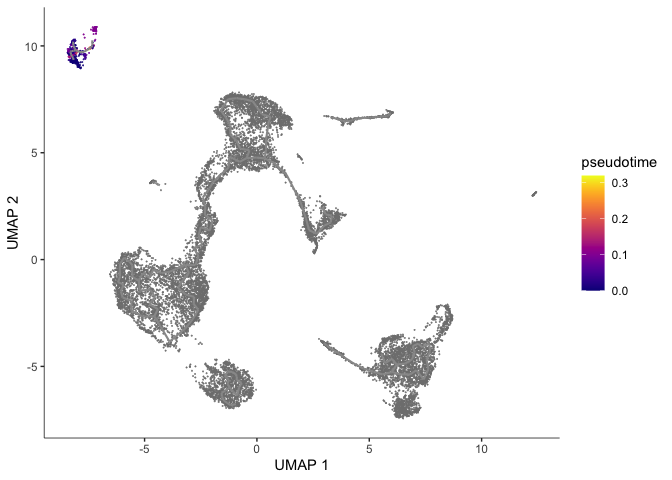
Here the pseudotime trajectory is rooted in cluster 5. This choice was arbitrary. In reality, you would make the decision about where to root your trajectory based upon what you know about your experiment. If, for example, the markers identified with cluster 1 suggest to you that cluster 1 represents the earliest developmental time point, you would likely root your pseudotime trajectory there. Explore what the pseudotime analysis looks like with the root in different clusters. Because we have not set a seed for the random process of clustering, cluster numbers will differ between R sessions.
Identify genes that change as a function of pseudotime
Monocle’s graph_test() function detects genes that vary over a trajectory. This may run very slowly. Adjust the number of cores as needed.
cds_graph_test_results <- graph_test(cds,
neighbor_graph = "principal_graph",
cores = 8)
The output of this function is a table. We can look at the expression of some of these genes overlaid on the trajectory plot.
head(cds_graph_test_results)
deg_ids <- rownames(subset(cds_graph_test_results[order(cds_graph_test_results$morans_I, decreasing = TRUE),], q_value < 0.05))
plot_cells(cds,
genes = head(deg_ids),
show_trajectory_graph = FALSE,
label_cell_groups = FALSE,
label_leaves = FALSE)
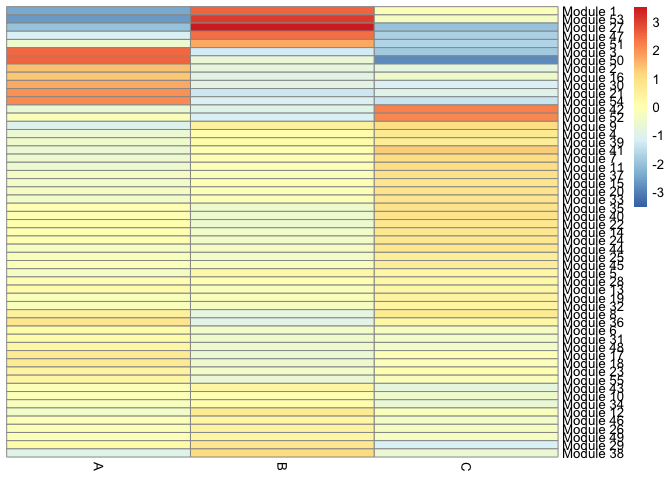
We can also calculate modules of co-expressed genes. By providing the module-finding function with a list of possible resolutions, we are telling Louvain to perform the clustering at each resolution and select the result with the greatest modularity. Modules will only be calculated for genes that vary as a function of pseudotime.
This heatmap displays the association of each gene module with each cell type.
gene_modules <- find_gene_modules(cds[deg_ids,],
resolution=c(10^seq(-6,-1)))
table(gene_modules$module)
cell_groups <- data.frame(cell = row.names(colData(cds)),
cell_group = colData(cds)$orig.ident)
agg_mat <- aggregate_gene_expression(cds,
gene_group_df = gene_modules,
cell_group_df = cell_groups)
dim(agg_mat)
row.names(agg_mat) <- paste0("Module ", row.names(agg_mat))
pheatmap::pheatmap(agg_mat,
scale="column",
treeheight_row = 0,
treeheight_col = 0,
clustering_method="ward.D2")
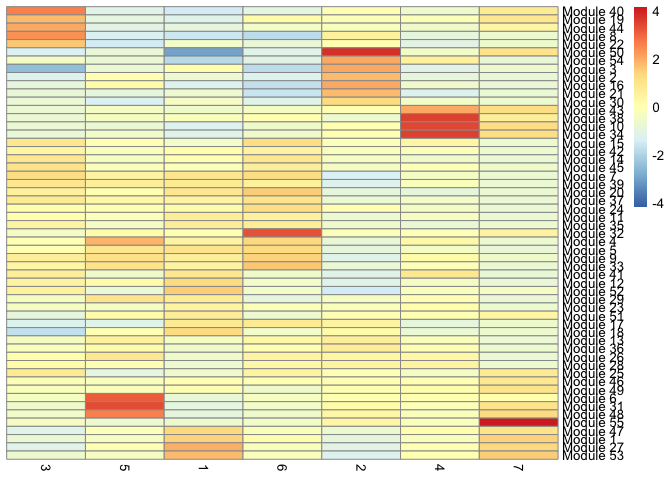
 We can also display the relationship between gene modules and monocle clusters as a heatmap.
We can also display the relationship between gene modules and monocle clusters as a heatmap.
cluster_groups <- data.frame(cell = row.names(colData(cds)),
cluster_group = cds@clusters$UMAP[[2]])
agg_mat2 <- aggregate_gene_expression(cds, gene_modules, cluster_groups)
dim(agg_mat2)
row.names(agg_mat2) <- paste0("Module ", row.names(agg_mat2))
pheatmap::pheatmap(agg_mat2,
scale="column",
treeheight_row = 0,
treeheight_col = 0,
clustering_method="ward.D2")
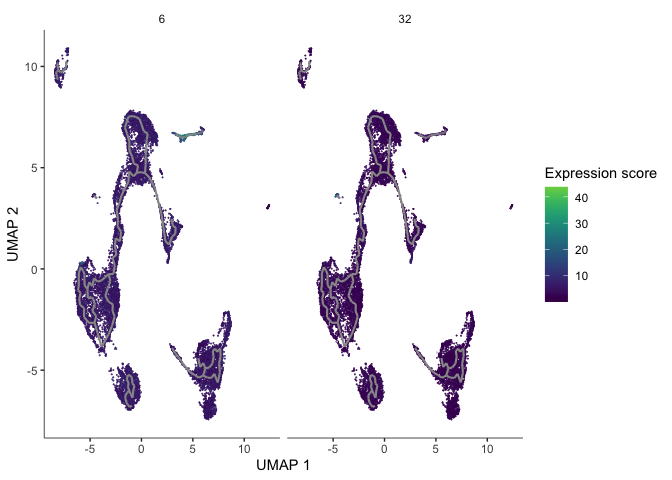
gm <- gene_modules[which(gene_modules$module %in% c(6, 32)),]
plot_cells(cds,
genes=gm,
label_cell_groups=FALSE,
show_trajectory_graph=TRUE,
label_branch_points = FALSE,
label_roots = FALSE,
label_leaves = FALSE,
trajectory_graph_color = "grey60")
R session information
sessionInfo()